Better explaining the CAP Theorem
By
 ·
·
Interview
·
·
Interview
Likes
(18)
Likes
There are no likes...yet! 👀
Be the first to like this post!
It looks like you're not logged in.
Sign in to see who liked this post!
Comment
Save
139.4K Views
Join the DZone community and get the full member experience.
Join For Free
today, i thought a lot about how to examine different databases. choosing a database is often a daunting task. there's a lot of confusion, a 'theorem', and more than all, the immortal proverb 'not one size fits all'. as if it helps.
one of the first things that you realize, when examining nosql distributed databases (and how could you not)is that these days databases are like cars: they're all good. old fashioned sql databases can scale in and out, horizontally sharded over several machines to achieve high availability. nosql systems claim to be consistent. what difference then does it make what database would you choose?
the availability and consistency that i mentioned comes, of course, from the misunderstood
cap theorem
, that - so people say - states that you can only choose 2 out of the 3
- consistency: every read would get you the most recent write
- availability: every node (if not failed) always executes queries
- partition-tolerance: even if the connections between nodes are down, the other two (a & c) promises, are kept.
usually its depicted in a nicely equilaterl triangle, as this one from
ofirm
:
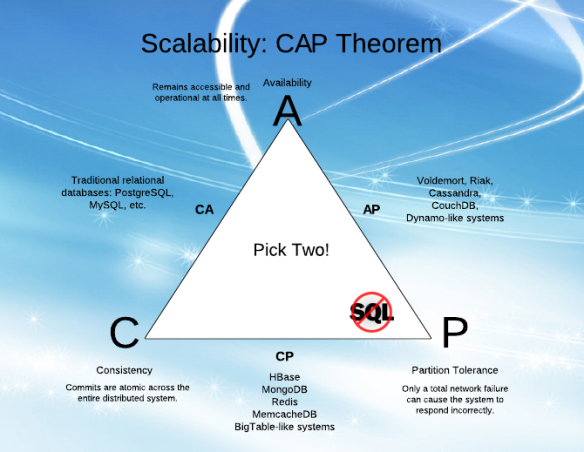
there's a nice proof and explanation of it in this 4 minute video
here
. but if we think about it, and also see some of brewer's (the theorem author) later
remarks
, we'll see that the 2 out of 3 is really 1 out of 2:
it's really just a vs c!
and this is simply because:
- availability is achieved by replicating the data across different machines
- consistency is achieved by updating several nodes before allowing further reads
- total partitioning, meaning failure of part of the system is rare. however, we could look at a delay, a latency, of the update between nodes, as a temporary partitioning . it will then cause a temporary decision between a and c:
- on systems that allow reads before updating all the nodes, we will get high availability
- on systems that lock all the nodes before allowing reads, we will get consistency
that's it! and since this decision is temporary, it exists only for the duration of the delay,
some may say
that we are really contrasting latency (another word for availability) against consistency.
by the way, there's no distributed system that wants to live with "paritioning" - if it does, it's not distributed. that is why putting sql in this triangle may lead to confusion.
Database
Theorem
IT
Machine
sql
NoSQL
Data (computing)
Task (computing)
Lock (computer science)
Opinions expressed by DZone contributors are their own.
Comments