Boosted Embeddings with Catboost
In this article, gain insights into Catboost, which is a simple and lesser-known way to use embeddings with gradient boosted models.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
When working with a large amount of data, it becomes necessary to compress the space with features into vectors. An example is text embeddings, which are an integral part of almost any NLP model creation process. Unfortunately, it is far from always possible to use neural networks to work with this type of data — the reason, for example, maybe a low fitting or inference rates.
I want to suggest an interesting way to use gradient boosting that few people know about.
Data
One of Kaggle’s competitions recently ended, and a small dataset with text data was presented there. I decided to take this data for experiments since the competition showed that the dataset is labelled well, and I did not face any unpleasant surprises.
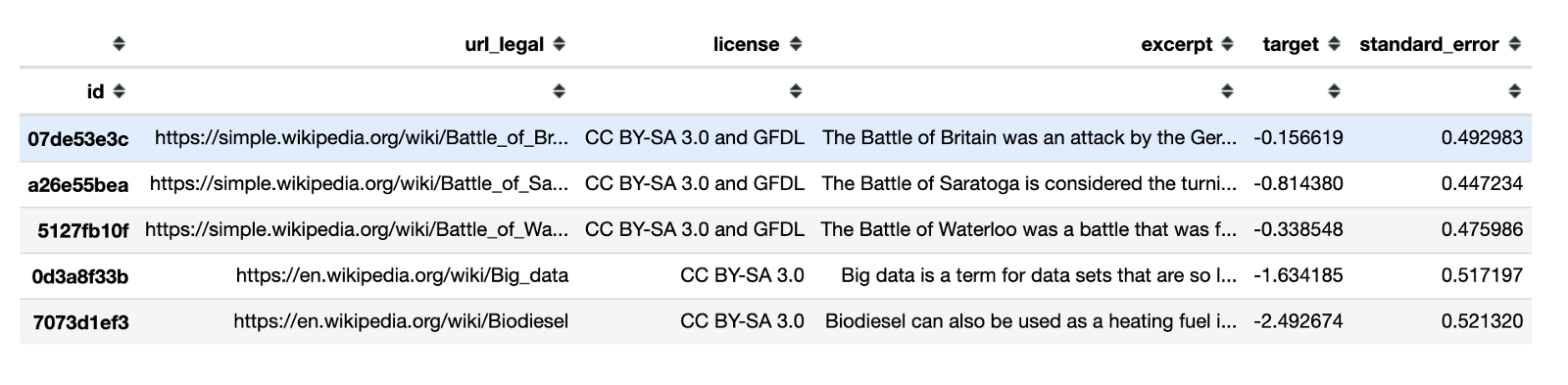
Columns:
id- unique ID for excerpturl_legal- URL of sourcelicense- license of source materialexcerpt- text to predict reading easetarget- reading easestandard_error- measure of the spread of scores among multiple raters for each excerpt
As a target in the dataset, it is a numerical variable, and it is proposed to solve the regression problem. However, I decided to replace it with a classification problem. The main reason is that the library I will use does not support working with text and embeddings in regression problems. I hope that developers will eliminate this deficiency in the future. But in any case, the problems of regression and classification are closely related, and for analysis, it makes no difference which of the problems to solve.
Let's calculate the number of bins by Sturge’s rule:
num_bins = int(np.floor(1 + np.log2(len(train))))
train['target_q'], bin_edges = pd.qcut(train['target'],
q=num_bins, labels=False, retbins=True, precision=0)
But, first, I clean up the data.
train['license'] = train['license'].fillna('nan')
train['license'] = train['license'].astype('category').cat.codes
With the help of a small self-written function, I clean and lemmatize the text. The function can be complicated, but this is enough for my experiment.
def clean_text(text):
table = text.maketrans(
dict.fromkeys(string.punctuation))
words = word_tokenize(
text.lower().strip().translate(table))
words = [word for word in words if word not in stopwords.words('english')]
lemmed = [WordNetLemmatizer().lemmatize(word) for word in words]
return " ".join(lemmed)
I save the cleaned text as a new feature.
train['clean_excerpt'] = train['excerpt'].apply(clean_text)
In addition to text, I can select individual words in URLs and turn this data into a new text feature.
def getWordsFromURL(url):
return re.compile(r'[\:/?=\-&.]+',re.UNICODE).split(url)
train['url_legal'] = train['url_legal'].fillna("nan").apply(getWordsFromURL).apply(
lambda x: " ".join(x))
I created several new features from the text — these are various pieces of statistical information. Again, there is a lot of room for creativity, but this data is enough for us. The main purpose of these features is to be useful for the baseline model.
def get_sentence_lengths(text):
tokened = sent_tokenize(text)
lengths = []
for idx,i in enumerate(tokened):
splited = list(i.split(" "))
lengths.append(len(splited))
return (max(lengths),
min(lengths),
round(mean(lengths), 3))
def create_features(df):
df_f = pd.DataFrame(index=df.index)
df_f['text_len'] = df['excerpt'].apply(len)
df_f['text_clean_len' ]= df['clean_excerpt'].apply(len)
df_f['text_len_div'] = df_f['text_clean_len' ] / df_f['text_len']
df_f['text_word_count'] = df['clean_excerpt'].apply(
lambda x : len(x.split(' ')))
df_f[['max_len_sent','min_len_sent','avg_len_sent']] = \
df_f.apply(
lambda x: get_sentence_lengths(x['excerpt']),
axis=1, result_type='expand')
return df_f
train = pd.concat(
[train, create_features(train)], axis=1, copy=False, sort=False)
basic_f_columns = [
'text_len', 'text_clean_len', 'text_len_div', 'text_word_count',
'max_len_sent', 'min_len_sent', 'avg_len_sent']
When data is scarce, it is difficult to test hypotheses, and the results are usually unstable. Therefore, to be more confident in the results, I prefer to use OOF(Out-of-Fold) predictions in such cases.
Baseline
I chose Catboost as the free library for the model. Catboost is a high-performance, open-source library for gradient boosting on decision trees. From release 0.19.1, it supports text features for classification on GPU out-of-the-box. The main advantage is that CatBoost can include categorical functions and text functions in your data without additional preprocessing.
In Unconventional Sentiment Analysis: BERT vs. Catboost, I expanded on how Catboost worked with text and compared it with BERT.
This library has a killer feature: it knows how to work with embeddings. Unfortunately, at the moment, there is not a word about this in the documentation, and very few people know about this Catboost advantage.
!pip install catboost
When working with Catboost, I recommend using Pool. It is a convenience wrapper combining features, labels and further metadata like categorical and text features.
To compare experiments, I created a baseline model that uses only numerical and categorical features.
I wrote a function to initialize and train the model. By the way, I didn’t select the optimal parameters.
def fit_model_classifier(train_pool, test_pool, **kwargs):
model = CatBoostClassifier(
task_type='GPU',
iterations=5000,
eval_metric='AUC',
od_type='Iter',
od_wait=500,
l2_leaf_reg=10,
bootstrap_type='Bernoulli',
subsample=0.7,
**kwargs
)
return model.fit(
train_pool,
eval_set=test_pool,
verbose=100,
plot=False,
use_best_model=True)
For OOF implementation, I wrote a small and simple function.
def get_oof_classifier(
n_folds, x_train, y, embedding_features,
cat_features, text_features, tpo, seeds,
num_bins, emb=None, tolist=True):
ntrain = x_train.shape[0]
oof_train = np.zeros((len(seeds), ntrain, num_bins))
models = {}
for iseed, seed in enumerate(seeds):
kf = StratifiedKFold(
n_splits=n_folds,
shuffle=True,
random_state=seed)
for i, (tr_i, t_i) in enumerate(kf.split(x_train, y)):
if emb and len(emb) > 0:
x_tr = pd.concat(
[x_train.iloc[tr_i, :],
get_embeddings(
x_train.iloc[tr_i, :], emb, tolist)],
axis=1, copy=False, sort=False)
x_te = pd.concat(
[x_train.iloc[t_i, :],
get_embeddings(
x_train.iloc[t_i, :], emb, tolist)],
axis=1, copy=False, sort=False)
columns = [
x for x in x_tr if (x not in ['excerpt'])]
if not embedding_features:
for c in emb:
columns.remove(c)
else:
x_tr = x_train.iloc[tr_i, :]
x_te = x_train.iloc[t_i, :]
columns = [
x for x in x_tr if (x not in ['excerpt'])]
x_tr = x_tr[columns]
x_te = x_te[columns]
y_tr = y[tr_i]
y_te = y[t_i]
train_pool = Pool(
data=x_tr,
label=y_tr,
cat_features=cat_features,
embedding_features=embedding_features,
text_features=text_features)
valid_pool = Pool(
data=x_te,
label=y_te,
cat_features=cat_features,
embedding_features=embedding_features,
text_features=text_features)
model = fit_model_classifier(
train_pool, valid_pool,
random_seed=seed,
text_processing=tpo
)
oof_train[iseed, t_i, :] = \
model.predict_proba(valid_pool)
models[(seed, i)] = model
oof_train = oof_train.mean(axis=0)
return oof_train, models
I’ll write about the get_embeddings function below, but it is not used to get the model’s baseline for now.
I trained the baseline model with the following parameters:
columns = ['license', 'url_legal'] + basic_f_columns
oof_train_cb, models_cb = get_oof_classifier(
n_folds=5,
x_train=train[columns],
y=train['target_q'].values,
embedding_features=None,
cat_features=['license'],
text_features=['url_legal'],
tpo=tpo,
seeds=[0, 42, 888],
num_bins=num_bins
)
Quality of the trained model:
roc_auc_score(train['target_q'], oof_train_cb, multi_class="ovo")
AUC: 0.684407
Now I have a benchmark for the model’s quality. Judging by the numbers, the model turned out weak, and I would not implement it in production.
Embeddings
You can translate multidimensional vectors into embedding, which is a relatively low-dimensional space. Thus, embeddings simplify machine learning for large inputs such as sparse vectors representing words. Ideally, embedding captures some of the input semantics by placing semantically similar inputs close to each other in the embedding space.
There are many ways to obtain such vectors, and I do not consider them in this article since this is not the purpose of the study. However, it is enough for me to get embeddings in any way; the main thing is that they save the necessary information. In most cases, I use the popular method at the moment — pre-trained transformers.
from sentence_transformers import SentenceTransformer
STRANSFORMERS = {
'sentence-transformers/paraphrase-mpnet-base-v2': ('mpnet', 768),
'sentence-transformers/bert-base-wikipedia-sections-mean-tokens': ('wikipedia', 768)
}
def get_encode(df, encoder, name):
device = torch.device(
"cuda:0" if torch.cuda.is_available() else "cpu")
model = SentenceTransformer(
encoder,
cache_folder=f'./hf_{name}/'
)
model.to(device)
model.eval()
return np.array(model.encode(df['excerpt']))
def get_embeddings(df, emb=None, tolist=True):
ret = pd.DataFrame(index=df.index)
for e, s in STRANSFORMERS.items():
if emb and s[0] not in emb:
continue
ret[s[0]] = list(get_encode(df, e, s[0]))
if tolist:
ret = pd.concat(
[ret, pd.DataFrame(
ret[s[0]].tolist(),
columns=[f'{s[0]}_{x}' for x in range(s[1])],
index=ret.index)],
axis=1, copy=False, sort=False)
return ret
Now I have everything to start testing different versions of the models.
Models
I have several options for fitting models:
- text features;
- embedding features;
- embedding features like a list of separated numerical features.
I have consistently trained various combinations of these options, which allowed me to conclude how useful embeddings might be, or, perhaps, it is just an over-engineering.
As an example, I give a code that uses all three options:
columns = ['license', 'url_legal', 'clean_excerpt', 'excerpt']
oof_train_cb, models_cb = get_oof_classifier(
n_folds=FOLDS,
x_train=train[columns],
y=train['target_q'].values,
embedding_features=['mpnet', 'wikipedia'],
cat_features=['license'],
text_features=['clean_excerpt','url_legal'],
tpo=tpo,
seeds=[0, 42, 888],
num_bins=num_bins,
emb=['mpnet', 'wikipedia'],
tolist=True
)
For more information, I trained models on both GPU and CPU; and summarized the results in one table.
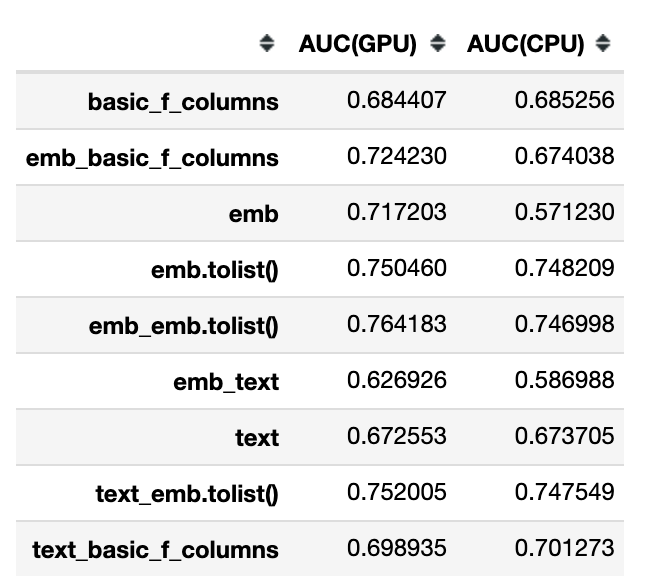
The first thing that shocked me was the extremely poor interaction of the text feature and embeddings. Unfortunately, I don't have any logical explanation for this fact yet — here, a more detailed study of this issue on other datasets is required. In the meantime, note that the combined use of text and embedding for the same text can bring down the quality of the model.
And another revelation for me was that embeddings do not work when training modes on a CPU.
And now a good thing — if you have a GPU and could get embeddings, the best quality will be when you simultaneously use embedding both as a feature and as a list of separate numerical features.
Summary
In this article, I:
- selected a small free dataset for tests;
- created several statistical features for the text data to use them for creating a baseline model;
- tested various combinations of embeddings, texts, and simple features;
- got some non-obvious insights.
I hope that this little-known information will be useful to the community and benefit from your projects. Unfortunately, the functionality of Catboost for working with embeddings and texts is still raw. But, it is actively being improved, and I hope there will be a stable release soon, and developers will update the documentation. The complete code to reproduce the results from this article is available here.
Opinions expressed by DZone contributors are their own.
Comments