Build It Yourself: Chatbot API With Keras/TensorFlow Model
Build a chatbot with Keras and TensorFlow.
Join the DZone community and get the full member experience.
Join For FreeIt's not as complex to build your own chatbot (or assistant, this word is a new trendy term for a chatbot) as you may think. Various chatbot platforms are using classification models to recognize user intent. While obviously, you get a strong heads-up when building a chatbot on top of the existing platform, it never hurts to study the background concepts and try to build it yourself. Why not use a similar model yourself? The main challenges of chatbot implementation are:
- Classify user input to recognize intent (this can be solved with machine learning, I'm using Keras with TensorFlow backend)
- Keep context. This part is programming, and there is nothing much ML-related here. I'm using the Node.js backend logic to track conversation context (while in context, we typically don't require a classification for user intents — user input is treated as answers to chatbot questions)
Complete source code for this article with readme instructions is available on my GitHub repo (open source).
This is the list of Python libraries that are used in the implementation. Keras deep learning library is used to build a classification model. Keras runs training on top of the TensorFlow backend. The Lancaster stemming library is used to collapse distinct word forms:

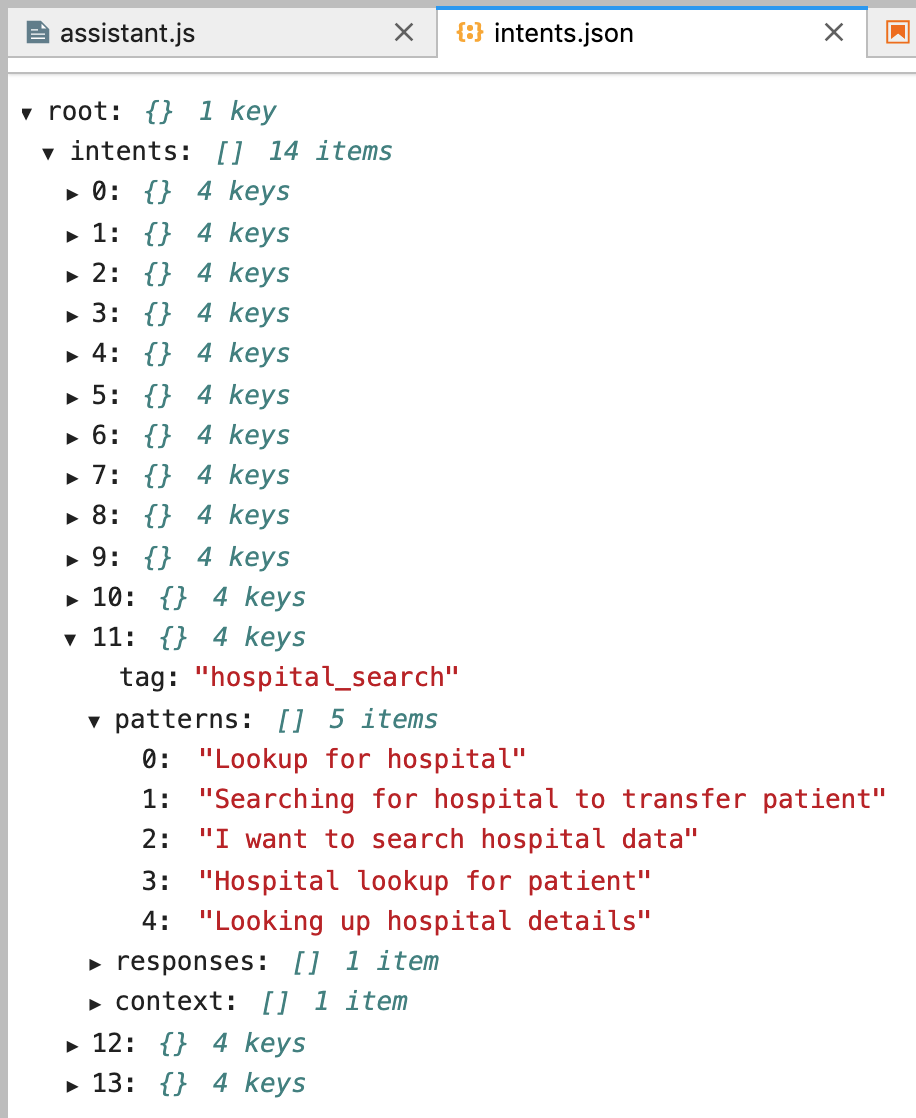
Chatbot intents and patterns to learn are defined in a plain JSON file. There is no need to have a huge vocabulary. Our goal is to build a chatbot for a specific domain. Classification models can be created for small vocabulary too, and it will be able to recognize a set of patterns provided for the training:
Before we can start with classification model training, we need to build vocabulary first. Patterns are processed to build a vocabulary. Each word is stemmed to produce generic root, and this will help to cover more combinations of user input:

This is the output of vocabulary creation. There are 9 intents (classes) and 82 vocabulary words:

Training would not run based on the vocabulary of words because words are meaningless to the machine. We need to translate the words into bags of words with arrays containing 0/1. The array length will be equal to vocabulary size, and 1 will be set when a word from the current pattern is located in the given position:

Training data — X (pattern converted into array [0,1,0,1..., 0]), Y (intents converted into array [1, 0, 0, 0,...,0], there will be single 1 for intents array). The model is built with Keras based on three layers. According to my experiments, three layers provide good results (but it all depends on training data). Classification output will be multiclass array, which will help to identify encoded intent. Using softmax activation to produce multiclass classification output (result returns an array of 0/1: [1,0,0,...,0] — this set identifies encoded intent):

Compile Keras model with SGD optimizer:

Fit the model — execute training and construct the classification model. I'm executing training in 200 iterations with batch size = 5:

The model is built. Now we can define two helper functions. Function bow helps to translate user sentence into a bag of words with array 0/1:

Check out this example — translating the sentence into a bag of words:

When the function finds a word from the sentence in chatbot vocabulary, it sets 1 into the corresponding position in the array. This array will be sent to be classified by the model to identify to what intent it belongs:

It is a good practice to save the trained model into a pickle file to be able to reuse it to publish through Flask REST API:

Before publishing model through Flask REST API, is always good to run an extra test. Use model.predict function to classify user input, and based on calculated probability, return intent (multiple intents can be returned):

Example to classify sentence:

The intent is calculated correctly:

To publish the same function through REST endpoint, we can wrap it into the Flask API:

I have explained how to implement the classification part. In the GitHub repo referenced at the beginning of the post, you will find a complete example of how to maintain the context. Context is maintained by logic written in JavaScript and running on the Node.js backend. Context flow must be defined in the list of intents, as soon as the intent is classified and backend logic finds a start of the context — we enter into the loop and ask related questions. How advanced context handling is all depends on the backend implementation (this is beyond the scope of machine learning at this stage).
Chatbot UI:

Published at DZone with permission of Andrejus Baranovskis. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments