Building a Custom Kafka Connect Connector
Read this article in order to learn how to customize, build, and deploy a Kafka connect connector in Landoop's open-source UI tools.
Join the DZone community and get the full member experience.
Join For FreeIn this article, we will learn how to customize, build, and deploy a Kafka Connect connector in Landoop's open-source UI tools. Landoop provides an Apache Kafka docker image for developers, and it comes with a number of source and sink connectors to a wide variety of data sources and sinks. FileStreamSourceConnector is a simple file connector that continuously tails a local file and publishes each line into the configured Kafka topic. Although this connector is not meant for production use, owing to its simplicity, we'll use it to demonstrate how to customize an open source connector to meet our particular needs, build it, deploy it in Landoop's docker image and make use of it.
Need for Customization
The FileStreamSourceConnector does not include a key in the message that it publishes to the Kafka topic. In the absence of key, lines are sent to multiple partitions of the Kafka topic with round-robin strategy. A relevant code snippet from the FileStreamSourceConnector source code is shown below.

If we are processing access logs, shown below, of Apache HTTP server, the logs will go to different partitions. We would like to customize this behavior and send all the logs from the same source IP to go to the same partition. This will require us to send source IP as the key included in the message.
109.169.248.247 - - [12/Dec/2015:18:25:11 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
109.169.248.247 - - [12/Dec/2015:18:25:11 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
46.72.177.4 - - [12/Dec/2015:18:31:08 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
46.72.177.4 - - [12/Dec/2015:18:31:08 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
83.167.113.100 - - [12/Dec/2015:18:31:25 +0100] "GET /administrator/ HTTP/1.1" 200 4263 "-" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"
83.167.113.100 - - [12/Dec/2015:18:31:25 +0100] "POST /administrator/index.php HTTP/1.1" 200 4494 "http://almhuette-raith.at/administrator/" "Mozilla/5.0 (Windows NT 6.0; rv:34.0) Gecko/20100101 Firefox/34.0" "-"Note that this use case is for pedagogical use only. There are number of logging solutions available for production use, e.g., ELK, EFK, Splunk to name a few.
Build the Connector
The source code for FileSourceStreamConnector is included in the Apache Kafka source code. To customize and build, follow these steps.
1. Fork Apache Kafka source code into your GitHub account.
2. Clone the forked repository and build jar.
git clone https://github.com/Randhir123/kafka.git
cd kafka
gradle
./gradlew jarThis will build the Apache Kafka source and create jars. To see the relevant jars for file source connector
cd connect/file/build/and you'll see connector jar and it's dependencies.
3. We'll make the required changes to include the source IP as key in the messages published to the Kafka topic. Let us rename the source file FileStreamSourceConnector.java to MyFileStreamSourceConnector.java so that the new connector is called MyFileStreamSourceConnector. The relevant changes are available on my GitHub.
4. Build your changes and copy the jars shown in Step 2 into a folder that we'll use to include the connector in Landoop's docker image.
Deploy the Connector
To make the connector that we have built in the last section available in Landoop's UI, follow these steps.
1. Create a docker-compose.yaml file to launch Apache Kafka cluster.
version: '2'
services:
kafka-cluster:
image: landoop/fast-data-dev
environment:
ADV_HOST: 127.0.0.1
RUNTESTS: 0
volumes:
- /Users/randhirsingh/custom-file-connector:/opt/landoop/connectors/third-party/kafka-connect-file
- /Users/randhirsingh/access.log:/var/log/myapp/access.log
ports:
- 2181:2181
- 3030:3030
- 8081-8083:8081-8083
- 9581-9585:9581-9585
- 9092:9092We have copied all the relevant file source connect jars to the local folder named custom-file-connector and we mount the folder to the relevant path in Landoop docker image. We are also mounting the Apache HTTP server access log that we want to process.
2. Change directory to the folder where you created docker-compose.yaml and launch kafka-cluster.
docker-compose up kafka-clusterCreate a File Source Connector
Once the docker container is up and running, create a new topic with multiple partitions that we'll use for our File source connector. Find the container ID and grab a shell into the container to create a topic.
docker container ps # note the container id
docker exec -ti <container-id> bash
kafka-topics --create
--topic my-topic-3
--partitions 3
--replication-factor 1
--zookeeper 127.0.0.1:2181Hit http://localhost:3030 to bring up Landoop UI. Navigate to Kafka Connect UI and click on New button. Under the Source connectors, you'll see the new connector.
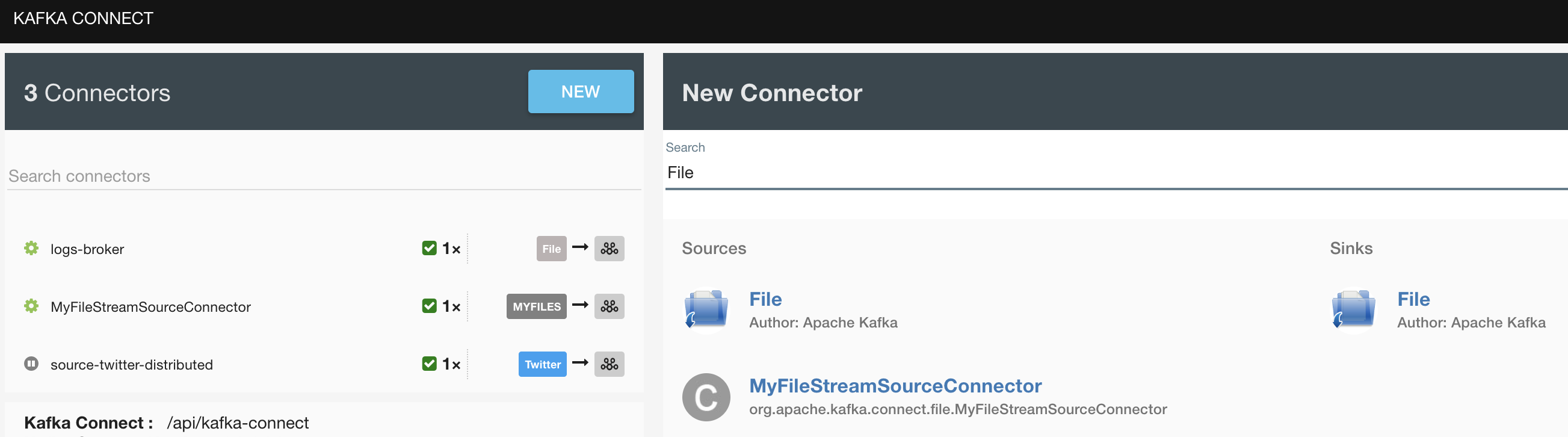
Select the new connector and provide details of topic and file configuration properties.
{
"connector.class": "org.apache.kafka.connect.file.MyFileStreamSourceConnector",
"file": "/var/log/myapp/access.log",
"tasks.max": "1",
"name": "MyFileStreamSourceConnector",
"topic": "my-topic-3"
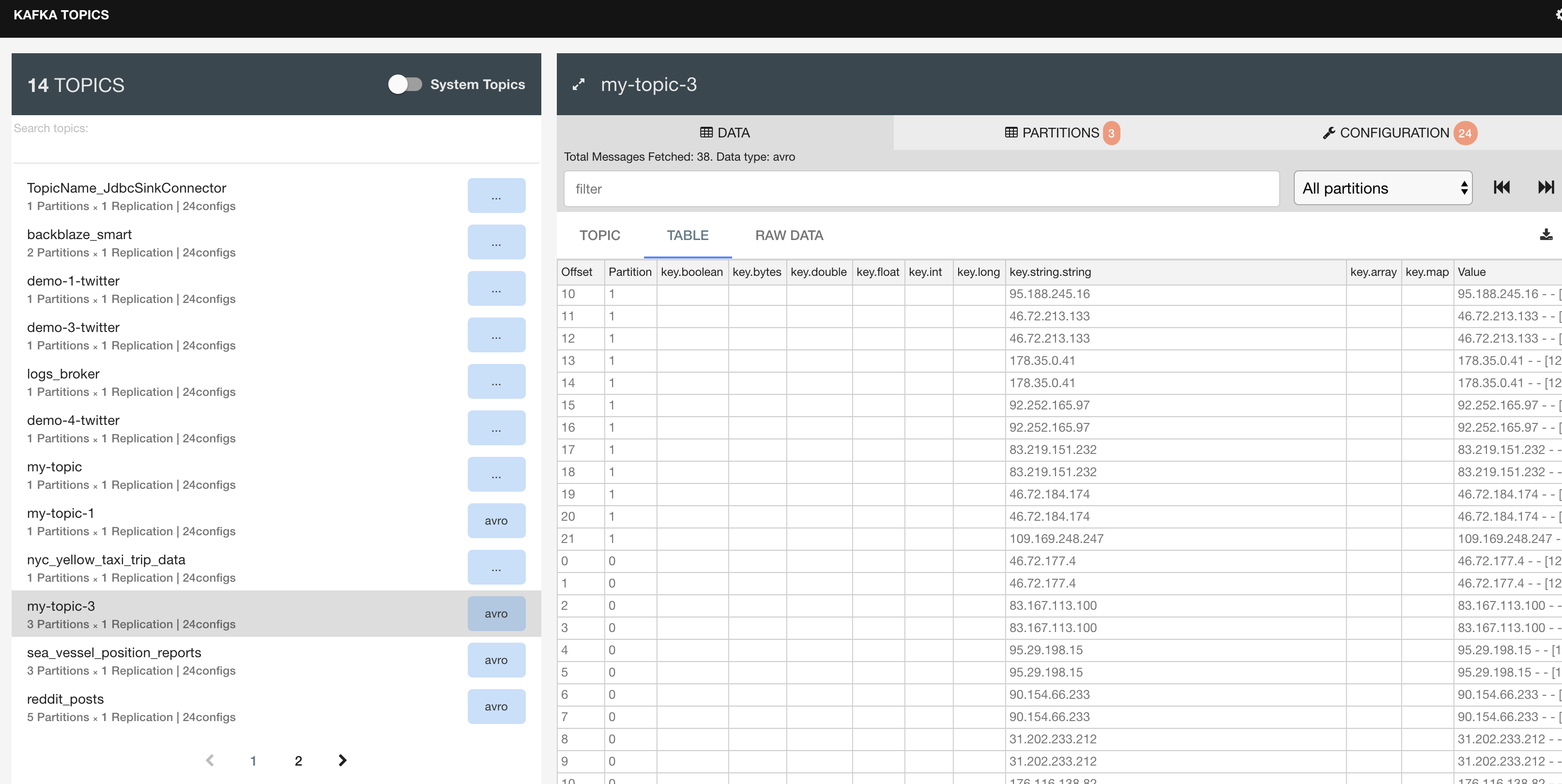
}Navigate back to the Kafka Topics UI to see the topic my-topic-3 and examine it's contents. Each log message now has source IP as the key included. Kafka takes care of sending messages with the same key to the same partition.
Conclusion
In this article, we looked at the steps to customize, build, and deploy a Kafka Connect connector into Landoop's docker image. The development steps for the connector are very specific for our use case. For a more comprehensive example of writing a connector from scratch, please take a look at the reference.
Opinions expressed by DZone contributors are their own.
Comments