Building Multimodal Agents with Google ADK — Practical Insights from My Implementation Journey
AI agents have rapidly evolved to support non-text inputs, unlocking new use cases and enabling seamless human-AI collaboration.
Join the DZone community and get the full member experience.
Join For FreeThe landscape of AI agents is rapidly evolving, moving far beyond the early days of simple language models and retrieval-augmented generation (RAG). The diagram below depicts the evolution in the last two years:
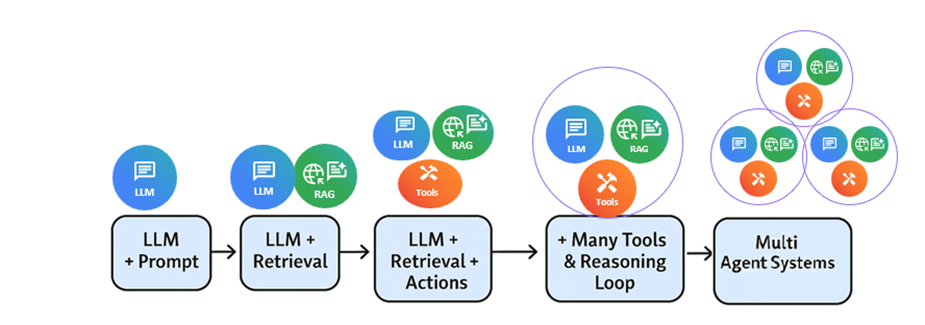
Key Milestones in Agent Evolution
- LLM + prompt: The journey began with large language models (LLMs) responding to prompts — powerful, but limited to text-based interactions.
- LLM + retrieval (RAG): The next step was integrating retrieval mechanisms, allowing agents to fetch and ground their responses in external knowledge sources, improving factual accuracy and context awareness.
- LLM + retrieval + actions (tools): Agents then gained the ability to use tools — APIs, databases, and external services — enabling them to perform actions, not just provide information.
- Many tools and reasoning loop: Modern agents orchestrate multiple tools and reason through complex workflows, iteratively planning and executing steps to achieve user goals
What's Next
As agentic systems mature, the proverbial question surfaces again: what’s next? A difficult one to answer, given how fast things are changing, but we are definitely witnessing a shift toward multimodal, tool-using, and multi-agent systems capable of sophisticated reasoning, planning, and autonomous action. You may have already seen recent advertisements showcasing Samsung & Google’s Gemini integration, leveraging video, voice, and screen sharing to power AI-driven shopping experiences. Multimodality simply means using or combining multiple types of input data, not just text, but also images, audio, or video, to understand or generate information.
As agents move beyond text, they can:
- Interpret and generate images, audio, and video, unlocking new use cases in fields like healthcare, e-commerce, design, customer support, and education. This is crucial for real-world applications — think voice-driven support, visual search, or cross-channel customer engagement
- Understand context more deeply, combining signals from multiple sources to make better decisions.
- Enable seamless human-AI collaboration, where users interact naturally, using the modalities that best fit their needs. For example, a user streams a video of their smart thermostat showing an error. The AI agent identifies the issue visually, suggests a fix, and adapts mid-conversation when the user also mentions a wiring concern — offering a wiring diagram and step-by-step guidance.
Why This Matters for Developers and Architects
For those building the next generation of AI-powered applications, these trends are more than technical milestones — they’re a call to action:
- Design for multimodality: Architect your agents to handle not just text but audio, images, and video, too. This unlocks new use cases and makes your solutions more accessible and intuitive.
- Embrace agentic patterns: Move beyond single-turn, stateless bots. Implement agents that can reason, plan, remember, and collaborate — mirroring how humans solve problems.
- Leverage modern protocols: Move beyond REST. Use technologies like WebSockets and Server-Sent Events (SSE) to enable real-time, multimodal interactions. This is especially relevant for live audio/video conversations, where latency and streaming are critical.
- Focus on orchestration and interoperability: As agents become more specialized, orchestrating their collaboration becomes key. Adopt open standards and modular frameworks to ensure your agents can work together seamlessly.
So, it should be clear that along with multimodality, the frontier now is also systems where multiple specialized agents collaborate. But, in this article, we are going to focus on multi-modality.
Demonstrating the Future: Gemini Live API & Multimodal Agents
I’ll showcase how one can build a multimodal agent conversation using the Google Agent Development Kit (ADK) & Gemini Live API, leveraging audio as a primary modality. By integrating WebSockets and SSE, we’ll enable real-time, streaming interactions — demonstrating how modern agentic architectures can deliver seamless, human-like experiences.
“This project builds upon Google’s Agent Development Kit (ADK) multimodal samples available on GitHub. I’ve adapted and extended them for educational and demonstration purposes.”
Bi-Directional Streaming
Bi-directional streaming refers to a communication pattern where data flows simultaneously in both directions between a client and a server. It represents a fundamental shift from traditional AI interactions.
Instead of the rigid "ask-and-wait" pattern, it enables real-time, two-way communication where both human and AI can speak, listen, and respond simultaneously. This creates natural, human-like conversations with immediate responses and the revolutionary ability to interrupt ongoing interactions. User-Agent interaction depicted below will follow the same, albeit not only in text but audio as well.
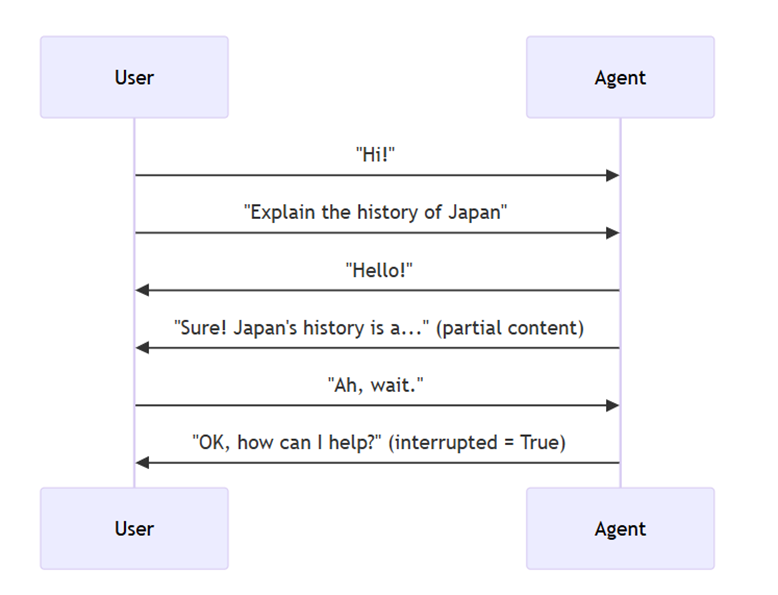
Challenges of Bi-Directional Streaming
- Unstable network connection
- Transparent Reconnection
- Caches session resumption
- Context Preservation on Reconnections
Bidi-Streaming vs Other Streaming Approaches:
- Server-Side Streaming: One-way data flow from server to client. Like watching a live video stream, you receive continuous data but can't interact with it in real-time. It's useful for dashboards or live feeds, but not for conversations.
- Token-Level Streaming: Sequential text token delivery without interruption. The AI generates responses word by word, but you must wait for completion before sending new input. It's similar to watching someone type a message in real-time — you see it forming, but can't interrupt
- Bidirectional Streaming: Full two-way communication with interruption support. True conversational AI where both parties can speak, listen, and respond simultaneously. This is what enables natural dialogue, where you can interrupt, clarify, or change topics mid-conversation
Differences Between WebSockets & Server-Sent Events (SSE) Protocols
The implementation example provided here is for both protocols, but it’s important to understand the difference between the two first:
|
Feature |
Web Sockets |
Server-Sent Events (SSE) |
|
Communication |
Bidirectional (full-duplex) |
Unidirectional (server → client) |
|
Protocol |
WebSocket protocol (ws://, wss://) |
HTTP/1.1 with long-lived GET request |
|
Data Type |
Text and binary |
Text only |
|
Use Case |
Live chat, agent-user interaction, multi-agent coordination |
Streaming LLM responses, notifications |
|
Reconnection |
Manual implementation required or through SDKs |
Automatic via EventSource API |
|
Error Handling |
Basic onerror event |
Robust; auto-reconnect built-in |
|
Proxy/Firewall |
May be blocked by older firewalls |
Works wherever HTTP works |
|
Client Implementation |
WebSocket API in JavaScript |
EventSource API in JavaScript |
|
Enterprise Readiness |
Mature and widely supported |
Simple and effective for streaming |
About Google Agent Development Kit (ADK)
Google ADK is an open-source client-side SDK that enables developers to quickly build and test complex multi-agent systems. It's available in both Python and Java. Ever since the launch of Google ADK at Cloud Next 2025 in April, it has attracted strong traction from developers looking to simplify agent building and reduce time and effort. As this article is more focused on multimodality, I will not go into details of Google ADK, but quickly cover some features that will allow readers to explore it further and what it offers.
- Easy-to-use interface. It allows four ways for developers to interact:
a. WebUI (visual interaction, events, and monitoring agent behavior)
b. Command Line (Quick tasks, scripting, terminal commands)
c. API Server (Run your agent as REST API, allowing other applications to communicate and even test agent behavior through REST API calls via Postman)
d. Programmatic Interface (Create your own session and runner for more fine-grained control over agent execution, how you would with any Python application)
- Instant local testing. Comes with its own visual interface to test models and show event graphs for all interactions for easy debugging
- Pre-built custom community tools
- Session memory for stateful conversations
- Multi-agent interaction
- Callbacks to invoke custom functions through the flow
- Support for bi-directional streaming
- Artefacts management (outputs, i.e., files and docs from agent interactions)
Google ADK bidi streaming demo architectural view and components for this example:
It's a simple agent that uses GoogleSearch API as a tool to pass user queries received in text and audio and pass the results back to the user in the same format.

Developer provides:
Web/Mobile: Frontend applications that users interact with, handling UI/UX, user input capture, and response display
WebSocket / SSE Server: Real-time communication server (such as FastAPI) that manages client connections, handles streaming protocols, and routes messages between clients and ADK
Agent: Custom AI agent definition with specific instructions, tools, and behavior tailored to your application's needs
ADK provides:
LiveRequestQueue: Message queue that buffers and sequences incoming user messages (text content, audio blobs, control signals) for orderly processing by the agent
Runner: Execution engine that orchestrates agent sessions, manages conversation state, and provides the run_live() streaming interface
LLM Flow: Processing pipeline that handles streaming conversation logic, manages context, and coordinates with the language model
GeminiLlmConnection: Abstraction layer that bridges ADK's streaming architecture with Gemini Live API, handling protocol translation and connection management
Gemini provides:
Gemini Live API: Google's real-time language model service that processes streaming input, generates responses, handles interruptions, supports multimodal content (text, audio, video), and provides advanced AI capabilities like function calling and contextual understanding
Session Resumption Configuration:
ADK supports live session resumption to improve reliability during streaming conversations. This feature enables automatic reconnection when live connections are interrupted due to network issues.
• Automatic handle caching: The system automatically caches session resumption handles during live conversations.
• Transparent reconnection: When connections are interrupted, the system attempts to resume using cached handles.
• Context preservation: Conversation context and state are maintained across reconnections.
• Network resilience: Provides better user experience during unstable network conditions.
How to Run
Please refer to the code repository link for the code and instructions to get the app up and running. One would need to have Python >=3.9 and pip installed as a prerequisite. Using pip one can install google-adk in a single step after creating a Python virtual environment specific to this exploration. ADK came along with uvicorn web server as a dependency, so I didn't install it separately.
The web server and application can be brought up in a simple command:
uvicorn main:app --reload
Once the server is up just hit http://localhost:8000 to bring the application up and running and start interaction with the Agent. The agent currently uses Google Search to answer all your queries. Don't forget to interject the agent in between or steer the conversation to any unrelated topic.
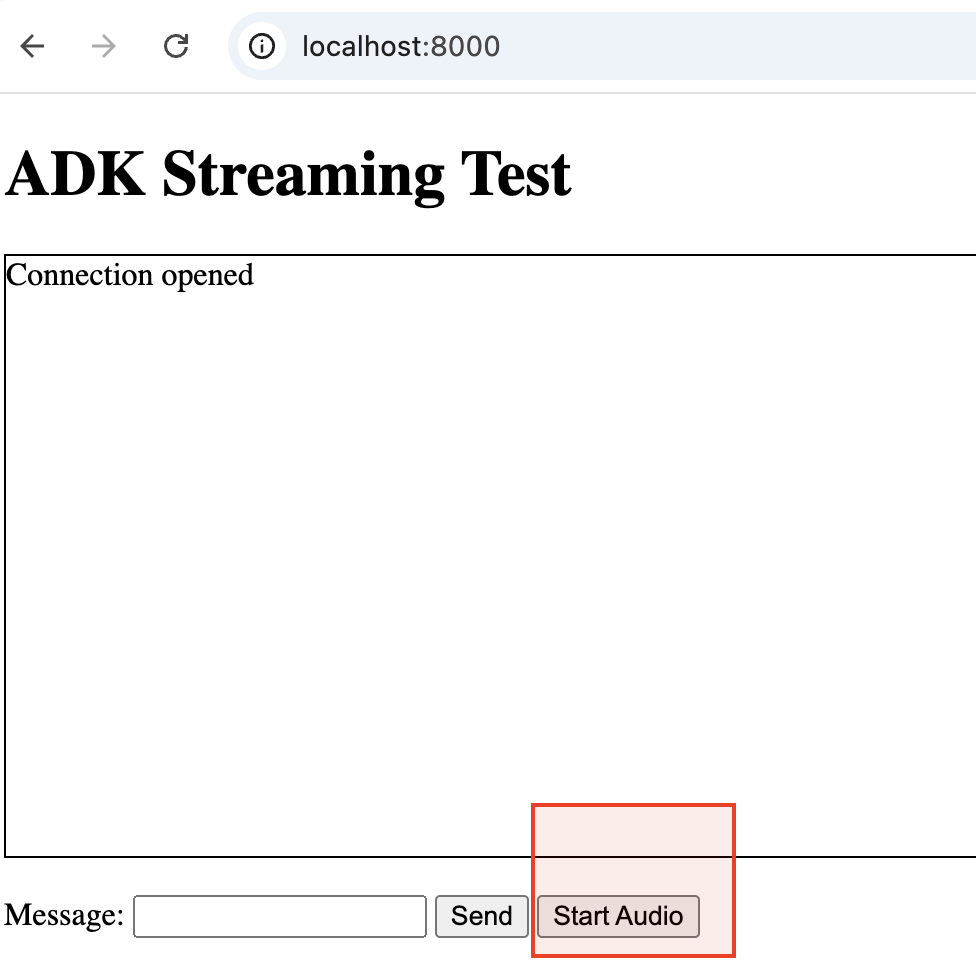
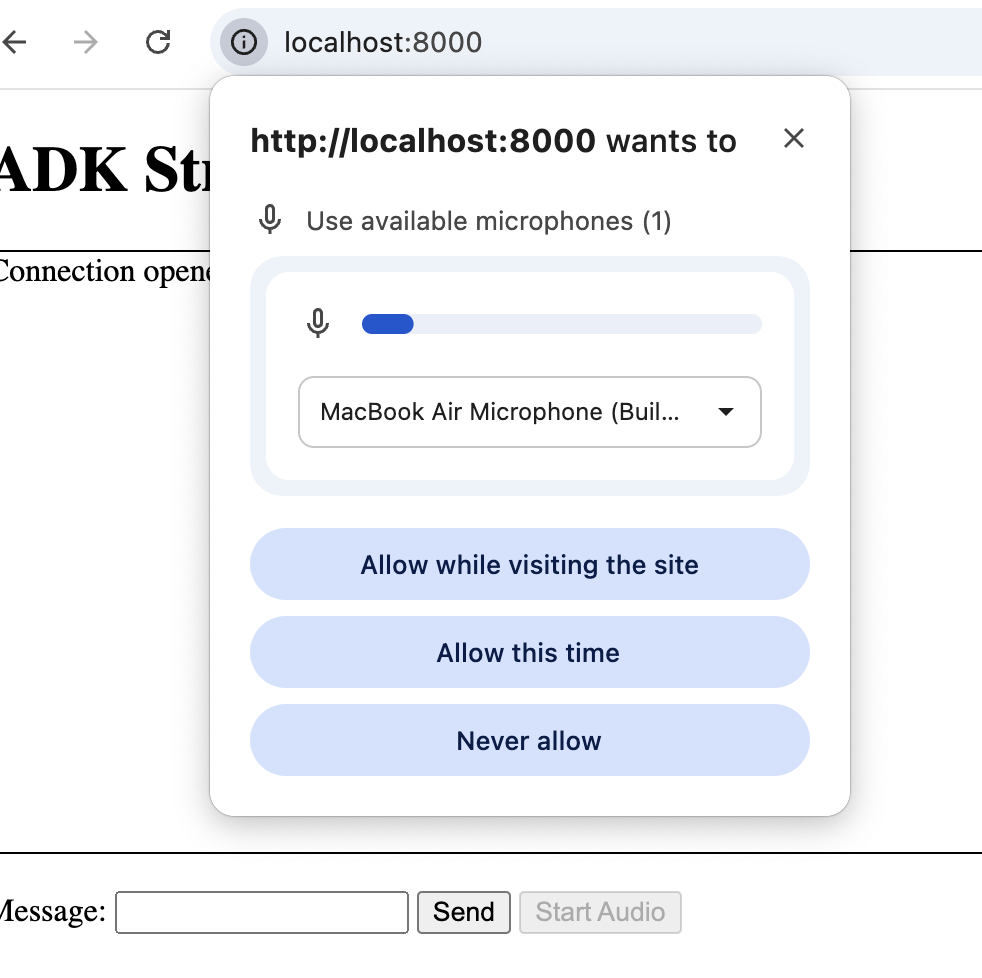
Conclusion
Looking ahead, the momentum behind multimodal agent development is undeniable — and accelerating. The industry is rapidly adopting frameworks that enable richer, more natural interactions across text, audio, images, and video. Even as I finish this article, Microsoft has also launched its own Agent Development Kit. So, the landscape of AI interaction may soon change, with multimodality at its core. Be ready to embrace it!
Opinions expressed by DZone contributors are their own.
Comments