System Design on Kafka and Redis
Read this article in order to learn more about the system design on Kafka and Redis.
Join the DZone community and get the full member experience.
Join For FreeI recently worked on a horizontally scalable and high performant data ingestion system based on Apache Kafka. The objective was to read, transform, load, validate, enrich, and store the risk feed within minutes of file arrival. The system received the bank upstream risk feed and processed the data to calculate and aggregate run information for a number of risk feed systems and runs.
The performance SLAs limited performing validation, transformation, and enrichment of data to streaming and ruled out any batch processing.
This article describes the approach I took in the project.
Architecture Diagram
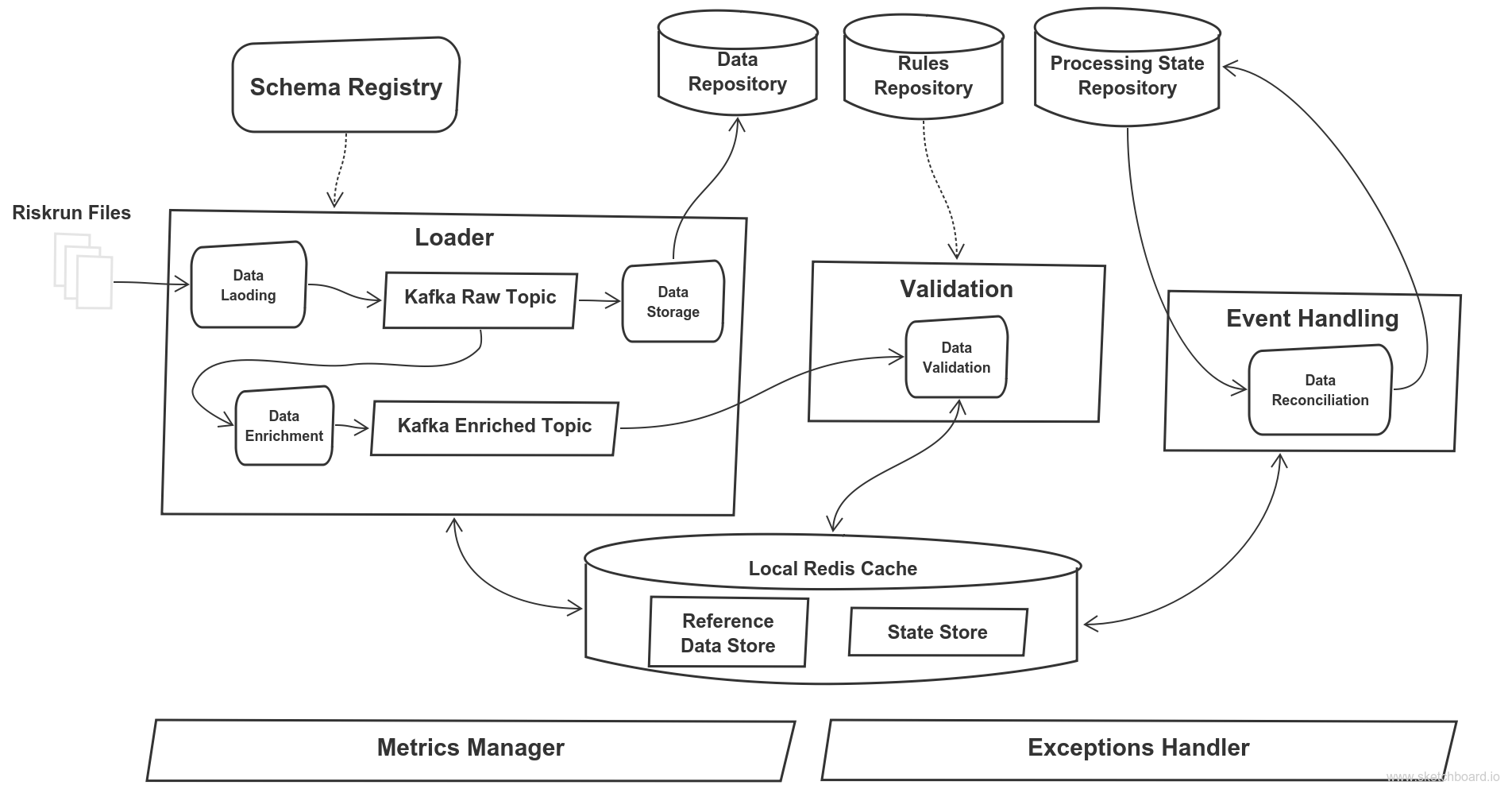
Apache Kafka
The first decision was to use Apache Kafka and stream incoming file records into Kafka.
Apache Kafka was chosen as the underlying distributed messaging platform because of its ability to support high-throughput linear writes and low-latency linear reads. Its combination of capabilities of distributed file system and enterprise messaging platform was ideal for this project for storing and streaming data.
Kafka’s ability to scale, its resilience, and its fault tolerance were the key drivers for the integration.
Kafka topics in chained topology were used to provide reliable, self-balancing, and scalable ingestion buffer. Using a chain of Kafka topics to store intermediate shared data as part of the ingest pipeline is proven to be an effective pattern.
Stage 1: Loading
Incoming risk feeds were delivered to the system in different forms, but this document will focus on CSV file feed loads. System read the file feed and transformed the delimited rows to AVRO representation and stored these AVRO messages in “raw” Kafka topic.
AVRO
Constraints in both memory and storage required us to move away from traditional XML or JSON objects to AVRO. There are a number of reasons why AVRO was chosen as the data format:
- Compact format. Both XML or JSON would have been inefficient for high volume.nergy saving tip definition, with James B, if not already complete by then.
- Ability to evolve schema over time
- Direct mapping to and from JSON
Stage 2: Enrichment
As opposed to making remote calls to a database, it was decided to use local store to enable data processors to query and modify states. We provided Redis datastores local to processing engines that are used to enrich data as they stream through these components. Therefore, by providing fast local stores to enrich in-flight data, we were able to give better performance.
The custom enrichment component processed incoming data from the upstream “raw” Kafka topic, queried its local store to enrich them and written the result to downstream Kafka topic “enriched” for validation.
Redis
Reasons why Redis was chosen as the reference data store:
- Offers data replication across primary and secondary nodes.
- Can withstand failure and therefore provide uninterrupted service.
- Cache insertion is fast and allows mass insertion.
- Allows secondary indexing on the dataset which allowed versioning on cache elements.
- Clients in java. We choose Lettuce over Jedis for its transparent reconnection and asynchronous calls features.
The system had multiple processors running in a distributed fashion and needed a reliable local cache for each node.
Stage 3: Validation
Each row of data passed through applicable validation rules. We implemented a schema DSL to enable the system to define validation rules using predicate logic. All common logic operators (AND, OR, EQUAL, NOT EQUAL, IN RANGE, NULL, NOT NULL) were supported alongside some custom operators (LOOKUP).
Data validation process depended on specific conditions and implemented schemas had validation rules and condition mapping.
Validation rules were dynamically built based on the data type and applied to the data. And validation errors were collected and sent to the exception service.
Data validation success or failure were recorded using atomic counters spanning across multiple JVMs.
Stage 4: Reconciliation
The system’s responsibility was to notify about the complete of riskrun processing at file, slice, and run level. So, how were we able to achieve that? The event manager component was responsible for this task. The component was responsible to keep track of expected and actual number of records passing through different stages (loading, validation, etc...). Once the stage counters are same, the stage was tagged as complete.
What if the counters are not the same? The event manager implemented the concept of time windows between which the process looked for the counters. Once the time window elapsed, the stage was tagged as failed if it was not already set to complete.
Leaf nodes state contributed to the determination of their parent node state; e.g. files state belonging to a slice determined the state of the slice.
Reference Data Stores
Reference data comprises a number of different datasets, some static, others dynamic. These datasets are provided in Redis and refreshed on different frequencies (on arrival of new risk run slice, new data in source system or daily basis).
Data processors had to wait for the availability of cache entities before they could process the stream.
The requirement was to apply a specific version of the reference data set for a risk run. That required versioning to be implemented without exploding the memory requirements. The data set was stored in memory to avoid cache misses and access to the filesystem.
Redis' sorted set data structure was used to store records with a score, which was the timestamp for when the data is added to the cache. The average case insertion or search in sorted sets are O(N), where N is the number of elements in the set. A visual representation of Redis sorted sets data is provided below:
+-------------------+
| KEY |
+-------------------+
+---------------+ +-------------------+
| SCORE | | UNIQUE MEMBER 1 |
+---------------+ +-------------------+
+---------------+ +-------------------+
| SCORE | | UNIQUE MEMBER 2 |
+---------------+ +-------------------+
+---------------+ +-------------------+
|… | | … |
+---------------+ +-------------------+State Stores
Every stream processing is required to maintain the state of the processing. In this scenario, we had a processing engine that was distributed across multiple nodes. Therefore, the processing state was shared between these nodes. Now that all nodes are capable of modifying the same state, we need to ensure that multiple nodes should not end up overriding each other's changes.
This is were distributed locks implementation in Redis was critical for efficiency and accuracy. The system stored all shared counters, which were used to keep track of the process in Redis. Since Redis is single-threaded, every operation is atomic. The INCR operation in Redis is an atomic operation, which returns incremented value and ensures that different processes don’t take over the same key.
Opinions expressed by DZone contributors are their own.
Comments