Every Cache Miss Is a Tiny Tax on Your Performance
Cache misses add latency, load, and cost — optimize your cache hit ratio to reduce unnecessary backend work and keep systems fast at scale.
Join the DZone community and get the full member experience.
Join For FreeEvery cache miss is a small but persistent cost on your system.
Individually, a single miss may seem insignificant. At scale — thousands or millions of requests — these misses accumulate into measurable latency, increased database load, and degraded user experience.
Most systems do not slow down because of one expensive query. They degrade over time due to repeated inefficiencies. Cache misses are one of the most common and overlooked contributors to this pattern.
In modern distributed systems, where services depend on multiple layers of infrastructure, even small inefficiencies propagate quickly. What starts as a single cache miss can ripple through downstream systems, amplifying latency and increasing resource consumption.
The Hidden Cost of Cache Misses
A cache miss is not simply a delay. It triggers a sequence of additional work:
- A database query or downstream API call
- Network latency and serialization overhead
- Increased CPU and I/O utilization
- Additional pressure on shared infrastructure
When this pattern repeats under load, even a small drop in cache efficiency can lead to:
- Increased response times
- Higher infrastructure cost
- Elevated load on backend systems
- Greater likelihood of cascading failures
These effects compound quickly in distributed systems, where dependencies amplify delays across services. In high-throughput environments, this can result in bottlenecks that are difficult to diagnose because the root cause appears trivial at an individual request level.
What Is Cache Hit Ratio (and Why It Matters)
Cache hit ratio measures how often requests are served from cache instead of reaching the primary data store.
Cache Hit Ratio (%) = (Cache Hits / Total Lookups) × 100
While it appears to be a simple metric, it reflects how effectively a system avoids unnecessary work. A higher hit ratio typically results in:
- Lower latency
- Reduced backend load
- Improved scalability
A lower hit ratio indicates that the system is repeatedly performing operations that could have been avoided. Over time, this inefficiency translates into increased operational cost and reduced system reliability.
Architecture Overview
The diagram below compares a cache hit and a cache miss flow.
- The cache hit path (green) represents a short execution path where data is served directly from cache.
- The cache miss path (red) illustrates a longer path involving database queries, increased latency, and additional system load.
This comparison highlights a fundamental principle: not all requests carry the same cost. Some require significantly more resources than others.
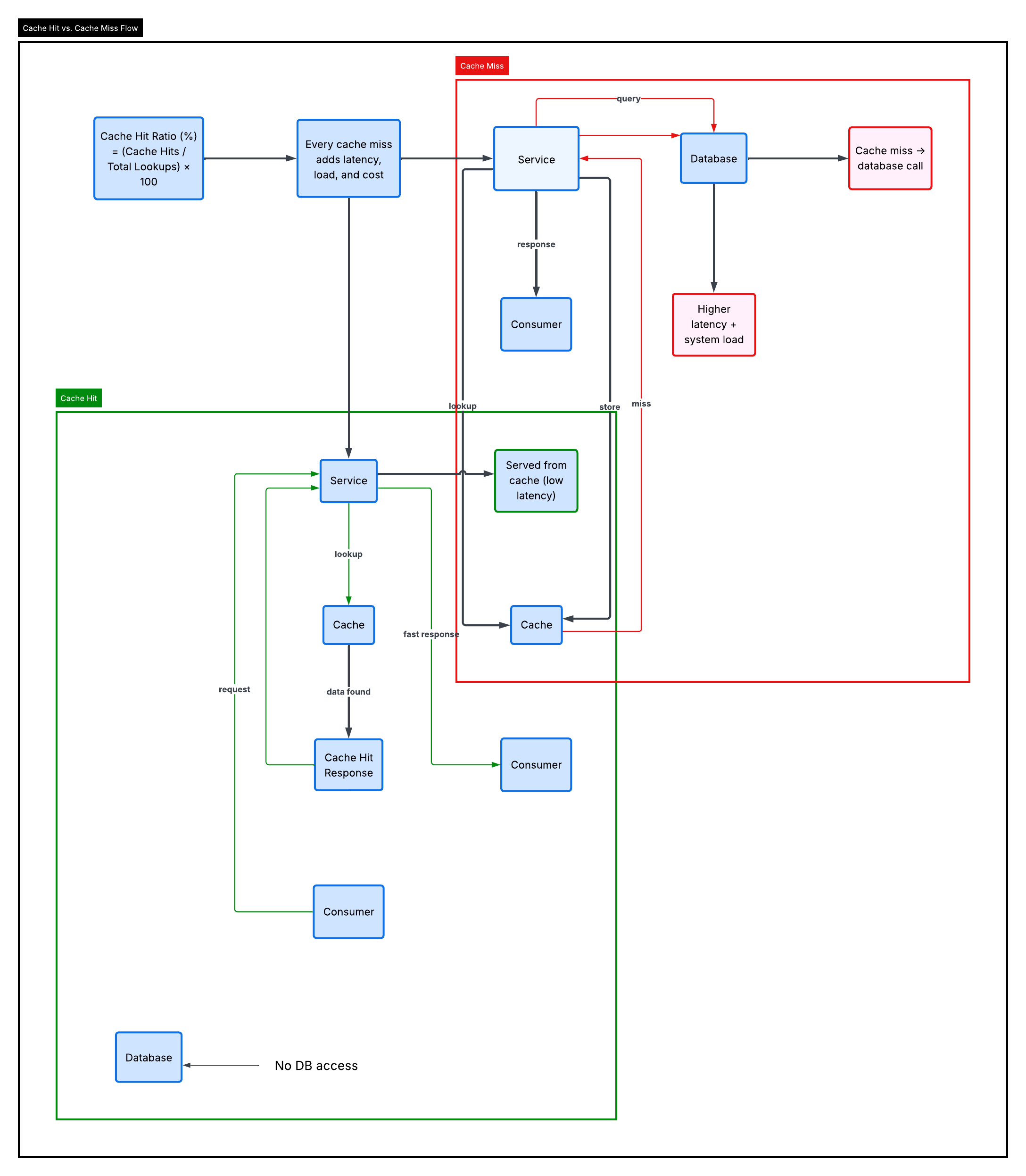
Cache hit vs cache miss flow illustrating how cache misses introduce latency, backend load, and system cost at scale.
A Simple Example
Consider a service receiving 10 requests:
- The first request results in a cache miss, queries the database, and stores the result
- The next 9 requests are served from cache
This results in:
9 cache hits out of 10 → 90% cache hit ratio
At a small scale, this level of efficiency appears acceptable. However, even in this simple scenario, the first request is significantly more expensive than the rest, demonstrating how cache misses introduce uneven cost distribution.
What Happens at Scale
The impact becomes more visible as traffic increases.
At a small scale:
- A cache miss introduces a minor delay
At a large scale:
- A 1% drop in cache hit ratio can result in thousands or millions of additional backend calls
This leads to:
- Increased latency across requests
- Higher load on databases and services
- Greater risk of timeouts and failures
In distributed architectures, this can trigger cascading effects, where delays propagate across multiple services and amplify system instability. Systems that perform well under normal conditions may degrade rapidly during traffic spikes due to inefficient caching strategies.
Trade-Offs: Performance vs Freshness
Caching introduces an inherent trade-off between performance and data consistency.
Serving data from cache improves latency and reduces backend load, but it also introduces the possibility of stale data.
Key considerations include:
- Strong consistency ensures data accuracy, but increases latency
- Eventual consistency improves performance but requires tolerance for temporary staleness
Techniques such as cache invalidation, write-through caching, and event-driven updates can help manage this balance effectively. The right approach depends on business requirements and tolerance for data freshness.
Implementation Considerations
Effective caching requires more than introducing a cache layer.
Cache warming is essential during deployments or cold starts. Without it, systems experience an initial surge in cache misses that can overwhelm backend dependencies.
Time-to-live (TTL) tuning must be handled carefully:
- Short TTL values lead to frequent expirations and increased misses
- Long TTL values risk serving stale data
Cache key design plays a critical role. Poorly structured or inconsistent keys lead to cache fragmentation, reducing overall effectiveness.
Failure handling must also be considered. Systems should handle cache failures gracefully without triggering retry storms or excessive backend load.
Real-World Impact
In production environments, cache inefficiencies often manifest as:
- Spikes in database CPU usage
- Increased API latency during peak traffic
- Unexpected infrastructure scaling
- Performance degradation after deployments
Organizations often scale infrastructure to address these issues. However, in many cases, the underlying problem is inefficient caching rather than insufficient capacity.
Improving cache efficiency is one of the most cost-effective ways to enhance system performance and stability.
What Is a Good Cache Hit Ratio?
There is no universal threshold, but general benchmarks include:
- Database query caches: 85–95%
- API response caches: 95–99%
- Content delivery networks: 99%+
The objective is not to achieve perfection, but to minimize avoidable backend operations.
How to Reduce the Cache Miss Tax
1. Preload Frequently Accessed Data
Warm caches during deployments to reduce cold-start impact.
2. Tune TTL Carefully
Balance expiration timing with data freshness requirements.
3. Use Predictable Cache Keys
Ensure consistency and avoid unnecessary misses.
4. Monitor Continuously
Track cache hit ratio alongside latency, backend load, and error rates.
Conclusion
A high cache hit ratio improves performance, but it should not come at the cost of serving outdated data.
The goal is not to cache everything, but to cache strategically based on access patterns and system requirements.
Every cache miss represents additional work performed by the system. At scale, these small costs accumulate into measurable performance degradation. Reducing cache misses is not only an optimization — it is a foundational requirement for building scalable, efficient systems.
Opinions expressed by DZone contributors are their own.
Comments