Choosing the Right Caching Strategy
This article explores different caching strategies, such as in-memory, distributed, and hybrid approaches, for optimizing performance in microservices or mono.
Join the DZone community and get the full member experience.
Join For FreeToday, it’s nearly impossible to build scalable applications without eventually addressing caching. Most development teams have likely experimented with different caching strategies or tools and eventually crafted a solution that works best for their own needs.
We deal with large volumes of data, ensuring low-latency data delivery is crucial across projects, whether B2C, B2B, or even desktop applications.
In this article, I’ll explore fundamental caching approaches, tools, and the primary scenarios where they shine. For simplicity, examples are implemented with Java and the Spring Framework, focusing solely on caching technology.
Key Technologies Used
- Java 22 and Spring Boot 3: The primary backend environment.
- Caffeine: A fast, in-memory cache for single-instance applications.
- Redis: A widely-used distributed caching system.
- Hazelcast: A distributed, in-memory data grid suitable for clustering.
- Kafka: Messaging service for asynchronous data updates.
- PostgreSQL: Relational database used for persistent storage.
- Grafana and Prometheus: Monitoring and visualization tools for performance metrics.
- Locust: Load testing tool to benchmark each caching strategy.
Let’s dive in.
What Is Caching?
Caching is a crucial optimization technique that allows data to be stored and quickly retrieved, reducing latency, decreasing database load, and improving application responsiveness.
Common Scenarios for Caching
- When an object hasn’t changed, retrieving it from the cache is cheaper than querying the database.
- Data is rarely updated, and fast access is essential.
- Microservices with potentially redundant data requests across services.
However, caching can also have drawbacks, especially when horizontal scaling and consistency are required across multiple instances. Let’s examine the primary caching methods, popular cache types, and the benefits and limitations of each approach.
Monolithic Applications or Vertically Scaled Services
In-memory caching is well-suited to monolithic applications or services with vertical scaling. Popular in-memory caching tools include Caffeine, Ehcache, and Guava.
In-memory caching stores data directly in the JVM, offering low latency by avoiding network calls. This approach is ideal when cached data is non-critical, has a short time-to-live (TTL), and has a slight inconsistency, which is acceptable.
Example with Caffeine:
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
return new CaffeineCacheManager();
}
}YAML configuration:
spring:
cache:
type: caffeine
cache-names: orders
caffeine:
spec: maximumSize=500,expireAfterAccess=600sYou can find the full code here.
Benefits
- Fast performance by keeping data in memory.
- Simple integration with frameworks like Spring Boot.
- Useful for storing non-essential information in responses.
Drawbacks
- Limited to server memory.
- Cache isn’t shared across instances, complicating horizontal scaling.
License: Caffeine, Guava, and Ehcache are free and open-source for commercial use.
Improving In-Memory Caching via Database Synchronization
If minor delays or eventual consistency are tolerable, using a database for synchronization can be effective. This approach allows services to detect updates by checking a timestamp in the database and clearing the cache if the data has changed.
Use Cases
- Minor latency is acceptable for non-critical data (e.g., product descriptions).
- Cache can be cleared and reloaded upon detecting timestamp changes.
Example:
@EnableScheduling
@Configuration
public class CacheControl {
private final CacheManager cacheManager;
private final CacheRepository cacheRepository;
private final ConcurrentHashMap<String, Instant> cacheMap = new ConcurrentHashMap<>();
private static final Logger logger = LoggerFactory.getLogger(CacheControl.class);
public CacheControl(CacheManager cacheManager, CacheRepository cacheRepository) {
this.cacheManager = cacheManager;
this.cacheRepository = cacheRepository;
}
@PostConstruct
public void init() {
cacheRepository.findAll()
.forEach(c -> cacheMap.put(c.getName(), c.getLastUpdate()));
}
@Scheduled(fixedRate = 60000)
public void resetCache() {
logger.info("Start cache reset");
cacheRepository.findAll().forEach(c -> {
var name = c.getName();
if (cacheMap.get(name).isBefore(c.getLastUpdate())) {
var cache = cacheManager.getCache(name);
if (cache != null) {
cache.clear();
} else {
logger.error("Cache not found for {}", name);
}
}
});
}
}Code Explanation: At application startup and during bean initialization, we query the database to collect information on the latest cache updates. This information is stored in a ConcurrentHashMap.
@PostConstruct
public void init() {
cacheRepository.findAll()
.forEach(c -> cacheMap.put(c.getName(), c.getLastUpdate()));
} In a Scheduled job, we regularly check the cache validity. If the cache is expired, we clear it.
if (cacheMap.get(name).isBefore(c.getLastUpdate())) {
var cache = cacheManager.getCache(name);
if (cache != null) {
cache.clear();
} else {
logger.error("Could not find cache for {}", name);
}
}
This approach is quite common. However, it can be further improved by using message queues.
Synchronizing Caches With a Message Queue
At some point, we may want to synchronize our caches not just within a single service but across all services. Yes, there are cases where we can share cache across multiple services because it serves as a hot storage layer for very fast operations. Or, we may want to avoid calling external services whenever possible to reduce latency, so we store data in each service and duplicate it.
For example, let’s say data from Service A is cached in Services B, C, and D. The task now is to notify all services whenever a product description changes or a user updates their nickname.
A message queue synchronization pattern can help here. In this example, I’m using Kafka.
Example:
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.kafka.annotation.KafkaListener;
import java.util.concurrent.TimeUnit;
public class OrderService {
private final Cache<String, Order> orderCache;
public OrderService() {
this.orderCache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(1000)
.build();
}
@KafkaListener(topics = "orders")
public void processOrder(String orderId) {
Order order = fetchOrderFromDatabase(orderId);
orderCache.put(orderId, order);
}
public Order getOrder(String orderId) {
return orderCache.getIfPresent(orderId);
}
}
The full listing can be found here.
To ensure each service can update its cache, we can configure them slightly to make this possible.
kafka:
bootstrap-servers: localhost:9092
consumer:
group-id: ${KAFKA_CG_NAME:cf-kafka-service-2}
auto-offset-reset: latest
producer:
bootstrap-servers: localhost:9092
We set a unique group-id for each service, allowing each service instance to update its cache.
This solution is somewhat complex, but it provides flexibility for your team to experiment with different modifications and find an optimal setup.
There are also simpler, out-of-the-box solutions if we’re using other patterns...
Distributed Caching Solutions
If you're short on time or don’t want to build everything from scratch, you can rely on ready-made solutions like Redis.
Redis
In 90% of Java and Spring projects, I would choose Redis. Often, we don’t need an expensive and complex cluster costing $1000/month — a basic setup is usually sufficient. I’ve seen several projects where even a simple Redis configuration was enough, even for high-load services.
As usual, the Spring team has ensured that integration is simple, so configuring Redis doesn’t feel significantly different from Caffeine, although the config file is slightly longer.
Example:
@Override
@Cacheable(cacheNames = "orders")
public Optional<Order> getOrder(String orderId) {
return orderRepository
.findById(UUID.fromString(orderId))
.map(this::map);
The full listing can be found here.
Configuration:
cache:
type: redis
cache-names: orders
redis:
key-prefix: "order_"
cache-null-values: false
data:
redis:
host: localhost
port: 6379
client-type: jedis
client-name: redis-service
Some nuances to keep in mind:
- Redis is free for basic use, with an Enterprise Edition that offers additional features.
- You need to monitor for failures yourself.
- Latency may increase since it’s still a network call.
- Redis can be combined with Caffeine to reduce latency, though this requires extensive configuration.
- Redis adds an extra point of failure to your system.
Hazelcast
Another caching option, and in my opinion, a more advanced one, is Hazelcast. Hazelcast is a distributed data and computing system that provides powerful tools for Java developers to create and manage microservices.
Hazelcast connects several nodes into a cluster, enabling fast data access and horizontal scalability. The cluster is automatically formed since Hazelcast uses multicast for node discovery or TCP/IP for static networks. One key advantage is that data is distributed across nodes and replicated for fault tolerance. The cluster also scales automatically as nodes are added, with no system downtime.
From the code perspective, there are not many changes in the service — only the configuration does.
@Override
@Cacheable(cacheNames = "orders")
public Optional<Order> getOrder(String orderId) {
return orderRepository
.findById(UUID.fromString(orderId))
.map(this::map);
The full listing can be found here.
Configuration:
cache:
type: hazelcast
cache-names: orders
hazelcast:
config: classpath:hazelcast-client.yamlHazelcast also has some downsides, like any solution:
- In the event of a network failure or other issues, the Hazelcast cluster may split into multiple parts, resulting in data inconsistency.
- Data eviction policies may sometimes lead to data loss if entries are removed too quickly.
- During routine node restarts, Hazelcast’s insert and retrieval operations may slow down cluster performance.
- A large number of features are only available in the paid version.
To summarize this approach:
Advantages:
- Data consistency across different instances of the application.
- Suitable for horizontally scalable systems.
Disadvantages:
- Higher latency due to network requests.
- Requires a well-configured infrastructure.
Other Options
Multi-Tier Caching
This method combines in-memory and distributed caching. For example, Caffeine could be used for fast in-memory data access, while Redis serves as a second-level cache for larger data volumes. If you have a few spare weeks and the desire to build it yourself, this approach offers a very flexible solution that can be customized with preferred metrics and fine-tuned to maximize performance.
Advantage:
- Balances speed and storage capacity.
Drawback:
- More complex architecture.
CDN-Level Caching (Content Delivery Network)
CDN caching could be a solution if your content is static and you want to avoid server costs.
Using a CDN, such as Cloudflare, Akamai, or Amazon CloudFront, allows for the rapid delivery of static content by distributing it across servers worldwide.
Advantages:
- Minimal latency for end users.
- Reduces server load.
Drawbacks:
- Only applies to static content.
- Dependence on a third-party provider.
Some Numbers
In the project, I tested all the implementations with Locust, which proved quite convenient. You can replicate these tests to see the results for yourself.
Naturally, in-memory caches perform the fastest. If time efficiency is your top priority, these solutions are ideal.
Load Testing With Locust
The link is here.
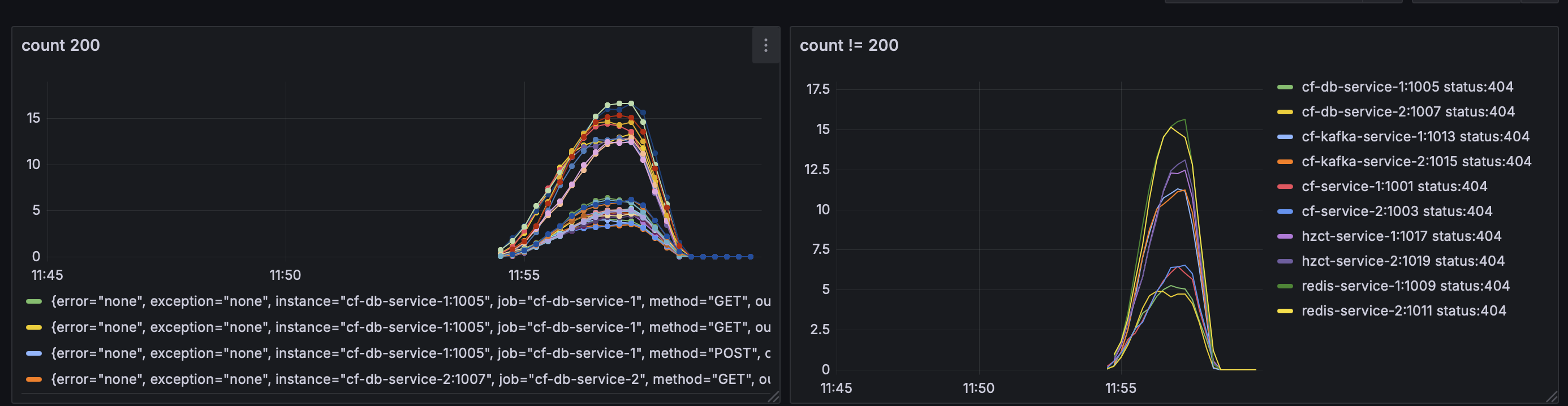
Using Locust, each service is tested under various loads to analyze response times, hit/miss ratios, and overall behavior. Here are the general results for the caching strategies:
- Caffeine (cf-service): Shows the lowest latency as it operates entirely in-memory within the JVM.
- Redis (redis-service): Slightly higher latency due to network calls but provides better scalability.
- Hazelcast (hzct-service): Moderate latency, with robust support for high availability.
- Memcached: Similar performance to Redis but lacks advanced features, making it better suited for basic caching needs.
Services and Code
The repository provides five main caching services, each with a unique implementation. Here’s an overview:
cf-service: Uses Caffeine, a high-performance in-memory cache, ideal for fast, lightweight applications that don’t require distributed cache support.cf-db-service: Combines Caffeine cache with database synchronization, storing frequently accessed data in memory while ensuring data integrity by syncing changes with PostgreSQL.cf-kafka-service: Integrates Caffeine with Kafka for messaging, allowing asynchronous updates to the cache when data changes.redis-service: Utilizes Redis for distributed caching, providing persistent caching across multiple instances, which is essential for highly available, horizontally scalable applications.hz-service: Leverages Hazelcast, a distributed in-memory data grid, for cache replication and clustering. Hazelcast is especially suitable for cloud environments where horizontal scaling is necessary.
You can find the GitHub repository here.
Conclusion
Since the goal of this article is to introduce caching approaches, let’s summarize some general takeaways for choosing a caching strategy:
1. Data Type:
- For complex data structures requiring high consistency, distributed caching works best.
- For simpler data, in-memory caching is sufficient.
2. Latency and Performance Needs:
- If minimal latency is critical, use in-memory caching.
- For larger data volumes, distributed caching is more suitable.
3. Data Consistency:
- If data updates frequently and strict consistency is needed, use caches with replication (such as Hazelcast).
4. Budget and Licensing:
- Open-source solutions like Redis Community Edition are great for medium-sized projects.
- For enterprise-level reliability, consider Redis Enterprise or Hazelcast Enterprise.
Always start by evaluating your metrics and SLAs. If caching can be avoided initially, hold off on implementing it. If a 500ms delay in your service isn’t a concern, then it’s not a problem. Remember that solving data synchronization issues can add complexity and maintenance overhead to your system.
If you decide to add caching, add it incrementally and monitor where it’s lacking instead of immediately creating a complex solution. In practice, a simple Caffeine cache with low TTL is often sufficient for non-complex fintech or similar applications.
For systems being built from scratch where speed is essential, Hazelcast or Redis are good starting points.
And don’t forget about licenses and paid versions:
- Caffeine: Free and commercially available.
- Redis: Free Community Edition, with a paid Enterprise version.
- Hazelcast: Free Community Edition and paid Enterprise Edition.
- Cloudflare and other CDNs: Commercial solutions with usage-based pricing.
Opinions expressed by DZone contributors are their own.
Comments