Caching Across Layers in Software Architecture
This article looks at how the cache works and how to use it across layers.
Join the DZone community and get the full member experience.
Join For FreeThe purpose of this article is to help readers understand what is caching, the problems it addresses, and how caching can be applied across layers of system architecture to solve some of the challenges faced by modern software systems.
This article is aimed at software developers, technical managers, software architects, test engineers, or anyone else interested in understanding how the cache can be used in software systems.
What Is Caching?
Why Caching Is Needed
Modern software systems have become more and more distributed and complex. This brings with it many challenges and problems, especially related to system performance. The slowness of systems may lead to a loss of credibility and profitability for companies.
The diagram below shows a very straightforward view of modern distributed architecture. Notice that the actual architecture would be even more complicated with many microservices (both internal as well as external) getting executed as part of the flow. There would be additional components such as messaging systems, LDAPs, rule engines, and so on in the design of the system.
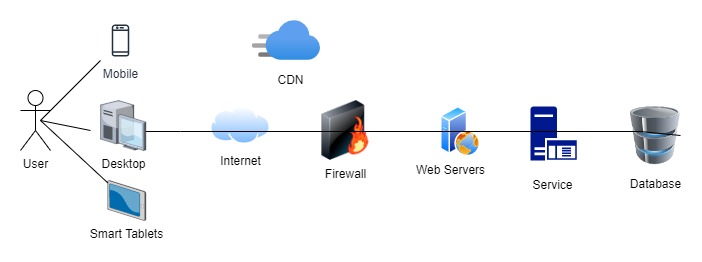
Figure 1: Layers of a software system
As the above diagram shows, there are a lot of interactions between the different components and hops are needed to complete a single request. This increases the latency at each point of contact due to the processing time taken by the component and the waiting time while it awaits the response of the downstream components.
Notice that the processing time may be due to the time taken by the application itself or a downstream system — or it may be due to the network (DNS lookups, establishing connections, network transfer time, and so on).
That's where caching helps make a system perform better by keeping a copy of the data close to the application's client/component.
How Caching Works
As illustrated in Figure 1 above, there can be different layers and interactions in a software system. Caching can be applied to any layer, but the basic principle for caching operation remains the same. Cached data would be used to avoid costly network hops, calls from the underlying database or slow storage systems.
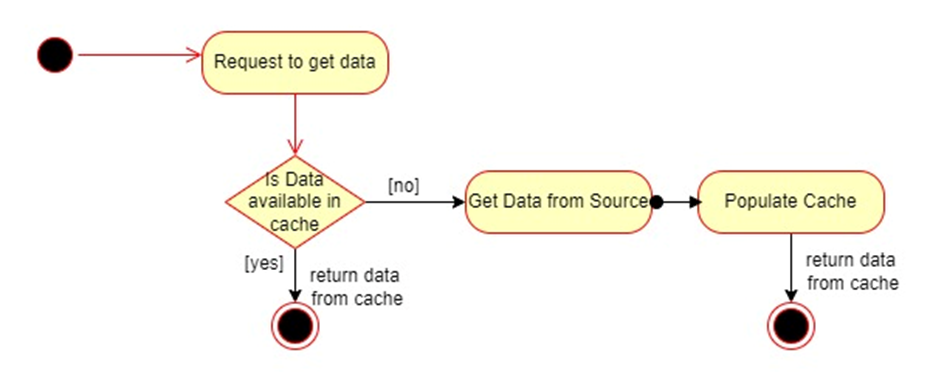
The following diagram shows how a caching would work in a particular scenario. That may be explained by the following sequence of steps. Note that there may be variations in the implementation of caching in various scenarios, but at a high level, the approach remains the same.
- A system/component receives a request to send back the requested data.
- It will check if the requested data is in the cache or not.
- In case the data is in the cache, the same cached data will be returned.
- Otherwise, the system will get data from the source (can be DB, external system, or an API call, for example) and will use this data to populate the cache.
- Finally, this data will be returned to the caller.
Advantages of Using Cache
- Better application performance: The main advantage of using the cache is that it increases the performance of the application. As the requested data is typically available closer to the application, in a fast memory access, it can be returned and reused for further processing. This helps boost the application performance.
- Avoid unnecessary disk access/network hops: As the requested data is typically available closer to the application, in a fast memory access, this can help avoiding the unnecessary hops to slower components like DB, the disk, or making calls to other components/systems over network. This again helps in boosting the application performance.
- Better scalability of DB: Since now there are fewer queries to the database, its capacity is freed up to handle other requests. This can reduce database load/cost and improve scalability. The same is true for other backend systems/components, as well.
Important Considerations While Using Cache
A few important decisions must be made while designing a caching framework for a given scenario. The following is a summary of some of the critical aspects of cache design:
- How much data should you cache?
- Which data must be deleted or kept when inserting new data in the cache?
- Is the data in cache still relevant, or is it stale/outdated?
- How can you keep the data in cache up-to-date?
- How can you keep cache-miss low?
The type/flavor of cache and various cache policy approaches will be discussed in the following sections. We'll look at how these affect cache behavior and address some of the issues raised above.
Multiple Flavors of Cache
In this section, we will discuss the various strategies that are commonly used to manage a scenario where the underlying data store is updated. As mentioned in the previous section, cache-miss ratio should be kept low.
Cache-miss is the scenario in which requested data is not found in the cache, while cache hit is the scenario in which requested data is found in the cache and need not to be retrieved from source.
To keep the cache-miss low, cache data should be kept up-to-date. Depending upon the application patterns, one of the following techniques can be used to ensure data in cache is as up-to-date as possible.
- Write through cache: In this technique, data is first updated in the cache, followed by the source system. This will ensure that cache always has the latest updated data. However, this introduces the delay in the write operations happening on the source systems. If the application is write-intensive, this approach is not recommended.
- Write back cache: To overcome the problem in write through cache, this technique is used. Similarly, the cache is also updated first in this case. However, the updated data in the cache is synchronized back to the source system asynchronously. If the application demands a higher level of consistency of source systems, this may not be a recommended technique.
- Write around cache: In this technique, data is directly updated in the source. Cache will be refreshed periodically to update the data from the datastore. This has the potential of getting stale data or increasing the cache-miss.
Examples of Cache Refresh Policies
This section summarizes some of the most popular techniques used to refresh the cache contents. There are multiple reasons that the cache might need to be refreshed. As cache size is generally much smaller than the source, not all data can be cached. As cache size grows over time, it can become full. Replacing the old data in cache with data that is more needed or more commonly used will result in lower cache miss. Below is a list of common used techniques to refresh the cache.
- Most recently used (MRU): In this technique, the most recently used item is discarded first and is replaced by a new item.
- Least recently used (LRU): In this technique, the item which is least recently used is discarded first and is replaced by a new item.
- First in, first out (FIFO): In this technique, the first item to be inserted in the cache is discarded first and is replaced by a new item.
- Last in, first out (LIFO): In this technique, the last item to be inserted in the cache is discarded first and is replaced by new item.
- Least frequently used (LFU): In this technique, the item which is least used in the cache is discarded first and is replaced by a new item.
- Most frequently used (MFU): In this technique, the item which is most frequently used in cache is discarded first and is replaced by new item.
Caching Across Layers
The following table summarizes how the cache can be used across layers in a software system. A few tools/frameworks are also highlighted, which can be used for implementing caching in a given scenario.
Note that, in a software application, caching can be applied in one or multiple layers.
|
|
|
|
Layer/Component |
Where to cache |
What to cache |
Tools/Framework |
Web Client |
Web/Mobile browsers |
Images/fonts and media files |
|
Web Server |
Web Servers |
Dynamic content, avoids overloading of app servers |
Using reverse proxies |
CDN |
On Content Delivery Network |
Static as well as API responses |
CDNs like AWS CloudFront, Akamai, etc. |
Application/Services Layer(L1) |
On application server |
Dynamic server response |
Custom logic or can use in-memory features provided by various frameworks like provided by Hibernate |
Distributed/In Memory Cache(L2) |
On a separate cluster running in memory. Can be used by multiple applications. |
Normally data stored in key value pair. Also can be used for session management for a stateless application. |
Redis, MemCached, AWS ElasticCache, HazelCast |
Opinions expressed by DZone contributors are their own.
Comments