Chaos Engineering for Architects: Designing Systems That Embrace Failure
Breaking things on purpose so they don't break by accident in production; a practical guide to building resilient distributed systems
Join the DZone community and get the full member experience.
Join For FreeThe Architect's Dilemma: When Perfect Designs Meet Reality
Our beautifully designed architecture diagrams are lies.
Not intentional ones, but lies nonetheless. They show clean boxes with arrows between them, depicting a world where services always respond, networks never partition, and databases never lock up.
But real systems are messier. Your authentication service will eventually have a bad deploy. That third-party API you depend on will rate-limit you without warning. A network switch will fail in a way that creates partial connectivity. And when these things happen, they'll happen in combination, creating failure modes you never imagined.
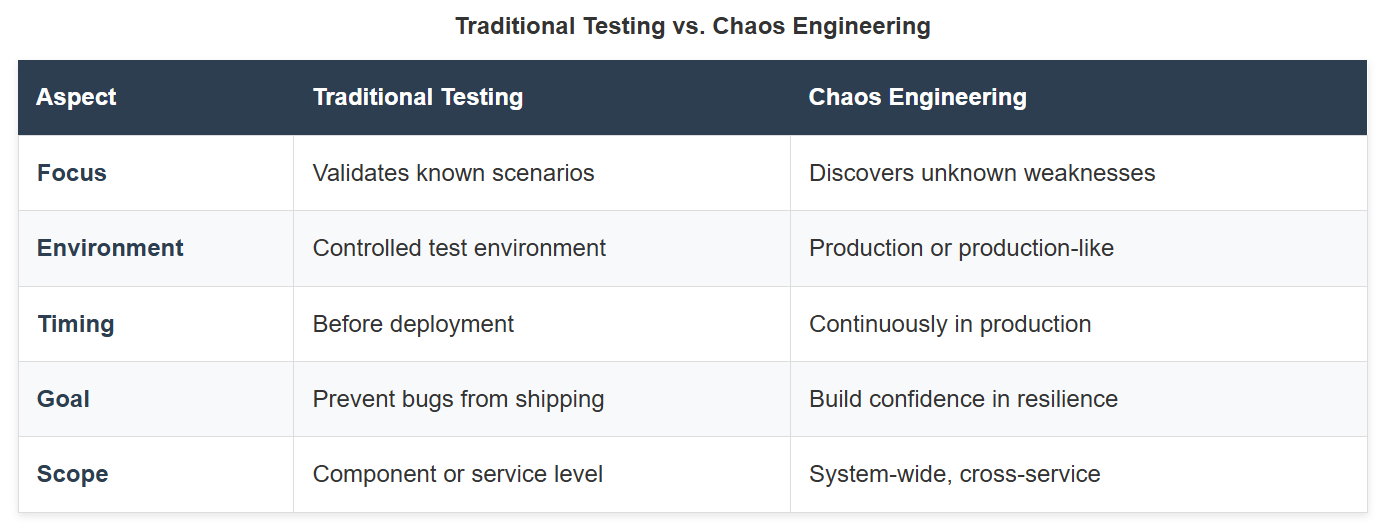
The False Comfort of Testing
Traditional testing gives us false confidence. Unit tests verify that individual components work. Integration tests check that services can talk to each other. Load tests prove we can handle traffic. But none of these tells us what happens when things go wrong in production.
I've seen systems with 95% test coverage completely fall apart when a single Redis instance became unavailable. The tests all passed because they never tested the failure scenarios that actually matter.
Architectural Principles for Chaos-Ready Systems
Chaos engineering isn't something you bolt onto a system after it's built. It's a design philosophy that influences every architectural decision you make. Here are five core principles that should guide your designs:
Assume Every Dependency Will Fail
When you draw that arrow from Service A to Service B, ask yourself "What happens when Service B is down? What happens when it's slow? What happens when it returns garbage data?"
- Timeouts are mandatory: Every external call gets a timeout. No exceptions. Start with 3 seconds for synchronous calls.
- Circuit breakers everywhere: For any service-to-service communication, when I see code making HTTP calls without a circuit breaker, that's a code review blocker.
- Fallback strategies upfront: Design the degraded experience when dependencies are unavailable, don't add it later.
- Bulkheading isolates failures: A slow database query shouldn't exhaust your entire connection pool.
Design for Observable Failure
You can't fix what you can't see. Observability in chaos engineering goes beyond standard metrics. You need to understand not just that something failed, but how that failure propagated through your system.
- Distributed tracing is non-negotiable: Use OpenTelemetry with clear span annotations for every external call, fallback execution, and circuit breaker state change.
- Structured logging with correlation IDs: When chaos strikes, quickly answer: which users were affected?
- Error budgets as first-class metrics: Track error budgets against SLOs for quantifiable system health.
Embrace Eventual Consistency
Strong consistency is the enemy of availability. The CAP theorem isn't just academic theory; it's a fundamental constraint. Most business requirements that claim to need strong consistency actually just need bounded inconsistency with clear resolution strategies.
- Event sourcing: Instead of updating state directly, emit events. This makes your system naturally resilient to partial failures.
- Saga patterns: Break long-running processes into steps with compensating transactions.
- CRDTs for multi-region data: Mathematically guarantee eventual consistency without coordination.
Implement Adaptive Capacity
Static capacity planning fails in the real world. Your system needs to automatically adjust based on current conditions, especially during partial failures.
- Queue-based auto-scaling: Scale out before you exhaust resources, not after.
- Dynamic rate limiting: Intelligently shed load when under stress.
- Backpressure mechanisms: Push back upstream when at capacity.
Build Runbook Automation into the Architecture
The best runbooks are the ones you never execute manually. Build in the remediation steps when designing your system.
- Automatic rollback mechanisms
- Self-healing infrastructure
- Traffic shifting capabilities
- Automated cache warming
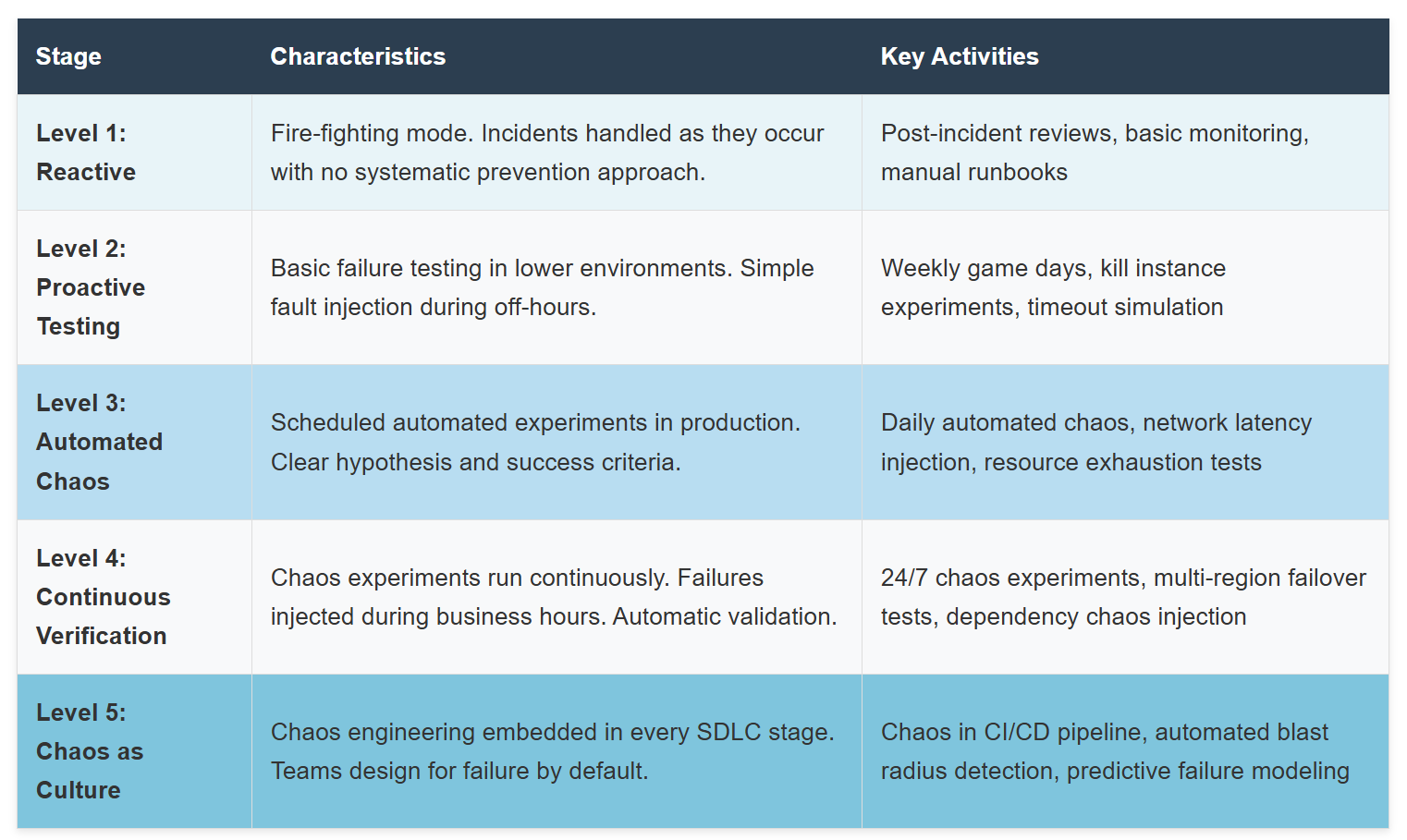
The Chaos Engineering Maturity Model
You don't go from zero to full-scale chaos engineering overnight. Here's a practical maturity model mapping to real organizational capability:
Architecture Patterns for Chaos Resilience
The Bulkhead Pattern: Isolating Failure Domains
Named after the compartments in a ship's hull, bulkheads prevent a failure in one part from cascading everywhere. The key insight is resource isolation.
- Separate thread pools for different downstream dependencies
- Database connection pooling per feature or tenant
- Separate deployments for critical vs. non-critical features
The Trade-Off
Bulkheads increase resource overhead by about 20%, but prevent total system failures.
The Retry Storm Prevention Pattern
It's one of the most dangerous failure modes: a service goes down momentarily, thousands of clients immediately retry, and when the service comes back up, it's instantly overwhelmed and crashes again.
- Exponential backoff with jitter: Add randomization so clients don't all retry simultaneously
- Circuit breaker with half-open state: Only send a single request to test health before flooding with traffic
- Token bucket rate limiting: Service protects itself even if clients misbehave
- Request hedging: Send requests to multiple backends simultaneously

The Regional Failover Architecture
True resilience means surviving regional failures. Here's the pragmatic approach:
- Active-active for stateless services: All regions serve traffic all the time
- Active-passive for stateful services: One region primary, others warm standbys
- Global load balancer with health checks: Route traffic away from failing regions within seconds
- Data replication strategy: Async for most data, sync for critical financial data
Implementing Your First Chaos Experiment
Step 1: Start with a Hypothesis
Don't randomly break things. Form a falsifiable, specific hypothesis. Examples:
- "If we terminate one payment service instance, the load balancer will route traffic to healthy instances within 30 seconds, and no payment requests will fail."
- "If the recommendation service has 500ms latency, the product page will still load within 2 seconds by falling back to cached recommendations."
Step 2: Define Blast Radius and Rollback
- Start small: Don't take down the entire service; kill one instance. Target 1% of traffic.
- Define abort conditions: Error rate above 1%? Response time above 5 seconds?
- Have a rollback script ready: One command stops the experiment and restores normal operations.
- Communicate: Use a dedicated Slack channel for chaos experiments.
Step 3: Instrument and Monitor
Key metrics to track:
- Request success rate at each layer
- Latency percentiles (especially P99)
- Circuit breaker state changes
- Fallback invocation counts
- Queue depths and backlogs
Step 4: Execute the Experiment
Run during business hours with your team watching. If you only test when traffic is low, you won't learn how your system behaves under real conditions.
- Take baseline reading of all metrics
- Announce the start in the team channel
- Inject the failure
- Watch metrics closely for 5-10 minutes
- Immediately rollback if abort conditions are met
- Monitor for another 10 minutes post-experiment
- Announce completion and initial results
Step 5: Analyze and Document
The real learning happens in analysis. Document:
- Was the hypothesis correct? If not, why?
- What unexpected behaviors did you observe?
- Were there close calls or near-misses?
- What architectural improvements would increase resilience?
- What monitoring gaps did you discover?
Key Insight: Failed experiments are often the most valuable because they reveal blind spots.
War Stories: Real Chaos Experiments
The Database Connection Pool Disaster
Hypothesis: The application can handle a database restart without user-facing errors.
Reality: The connection pool detected failures and aggressively retried. Within 30 seconds, all database connections are exhausted. The database came back up, but was immediately overwhelmed. Response times spiked to 60+ seconds.
Lessons: Connection pool retry needs exponential backoff with jitter. Implemented gradual connection pool warming: start with 1 connection, double every 5 seconds until reaching the target.
The Cascading Timeout Failure
Hypothesis: The Product page will degrade gracefully when the recommendation service becomes slow.
Reality: 3-second timeout per attempt, but the retry logic tried three times. Total latency: 9+ seconds. Application servers started queuing requests. Within 2 minutes, the entire application is effectively down.
Fixes: Total timeout budget across all retries. Circuit breaker after 3 consecutive timeouts. Separate request queue for non-critical features. Load shedding returns cached data when the queue depth exceeds the threshold.
The Chaos Budget: Quantifying Acceptable Risk
Similar to an error budget, the chaos budget is a quantifiable measure of how much chaos your system should tolerate. If you have 99.9% uptime SLA, you have 43 minutes of acceptable downtime per month. Your chaos budget is a portion of this.
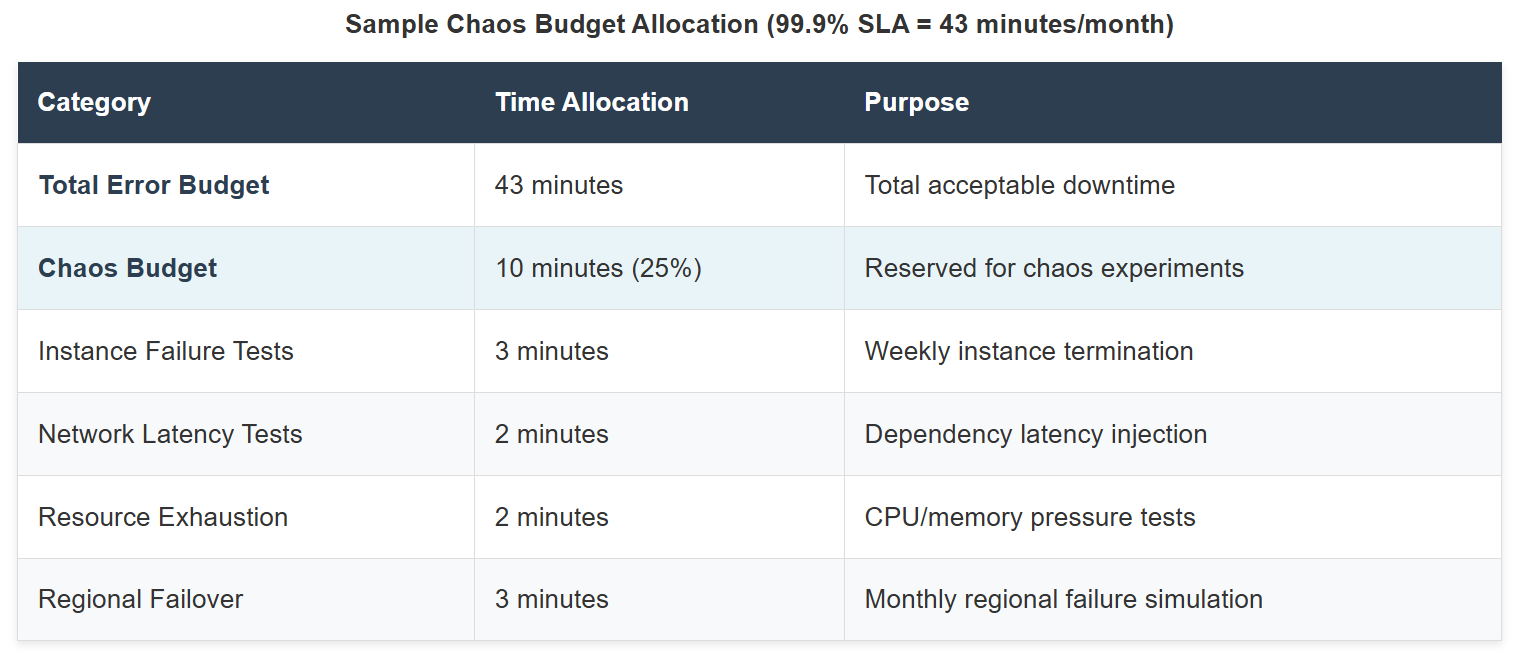
Budget allocation framework:
- Reserve 20-30% of the error budget for chaos experiments
- Start experiments with 1% traffic exposure
- Set impact limits: no single experiment should consume more than 5% of the total chaos budget
- Track actual impact vs. budget
Tools and Technologies
Infrastructure-Level Chaos
- Chaos Mesh: Kubernetes-native, comprehensive failure injection (my go-to for K8s)
- AWS Fault Injection Simulator: Native AWS integration for basic infrastructure chaos
- Gremlin: Commercial solution with great UI and safety features
Application-Level Chaos
- Toxiproxy: Lightweight proxy for network-level failures (my favorite)
- Chaos Monkey for Spring Boot: JVM ecosystem integration
- Chaos Toolkit: Language-agnostic, declarative approach
My Minimal Chaos Engineering Stack
- Toxiproxy for application-level network failures
- Simple bash scripts to terminate instances
- Prometheus + Grafana for observability
- Feature flags for controlling experiment blast radius
- Slack webhooks for experiment notifications
Common Pitfalls to Avoid
Testing in Unrealistic Environments
Production has emergent behaviors that only appear under real load. Start in production with very limited blast radius (0.1% of traffic).
Not Having a Clear Abort Strategy
Define thresholds before starting: error rate threshold, latency threshold, impact threshold, and maximum experiment duration.
Ignoring the Human Element
Chaos engineering is also about organizational resilience. Are runbooks accessible? Can team members find the right person to escalate to? Game days test both systems and coordination.
Death by a Thousand Timeouts
Work backward from user experience. Distribute timeout budget across the call chain. Pass remaining budget as a header. Fail fast when there's no time left.
Treating Chaos Engineering as One-Time Event
Your system changes constantly. Schedule regular experiments (weekly minimum). Automate common experiments. Include chaos in CI/CD pipeline.
Conclusion: Embrace the Chaos
Failure is not the enemy. Ignorance of failure is. Every complex system will fail. Your database will have an outage. Your cloud provider will have issues. A dependency will return errors. These aren't possibilities; they're certainties. The question isn't whether failure will happen, but whether you'll be ready when it does.
Chaos engineering moves you from hoping your system is resilient to proving it is. It transforms architecture from a static exercise into a dynamic practice of continuous validation.
Start small. Run your first experiment this week. Kill a single instance and watch what happens. Document what you learn. Then do it again next week with something different. Over time, you'll build both system resilience and organizational confidence.
The systems that survive in production aren't the ones that never fail. They're the ones that fail gracefully, recover quickly, and learn from every failure. Build systems that embrace chaos, and you'll sleep better at night.
Opinions expressed by DZone contributors are their own.
Comments