CI/CD With Kubernetes and Helm
DevOps, cloud, and microservices come together for a continuously iterable environment.
Join the DZone community and get the full member experience.
Join For FreeIn this blog, I will be discussing the implementation of CI/CD pipeline for microservices which are running as containers and being managed by Kubernetes and Helm charts
Note: Basic understanding of Docker, Kubernetes, Helm, and Jenkins is required. I will discuss the approach but will not go deep into its implementation. Please refer to the original documentation for a deeper understanding of these technologies.
Before we start designing the pipeline for Kubernetes- and Helm-based architecture, a few things we need to consider are
1. Helm chart code placement
2. Versioning strategy
3. Number of environments
4. Branching model
Helm Chart Code Placement
Helm chart code can be placed along with code or in a separate repo but we ended up keeping it along with the source code. Points which made us inclined to this decision were:
a. If a developer adds some variables which need to be updated in Kubernetes config map or secrets, this knowledge needs to be shared with the owner of the Helm chart repo. This will add make things complex and buggy.
b. CI scripts also need to be updated so they can interact with a different repo either by lambda functions or some other ways.
c. Microservices tends to grow into very large numbers and if we keep the Helm chart in a separate repo we would be requiring 2 times the original repos.
Versioning Strategy
Whenever a new build is deployed in preview or a review version has to be updated so it can reflect what new things it have. Apart from many options we have, like using a third-party service or custom scripts for this, we can also use a simple yet powerful feature of git, the describe command.
This command finds the most recent tag and returns it, adding a suffix on it with the number of commits done after the tag and the abbreviated object name of the most recent commit.
For example, if the tag is 1.0.1 and we have 10 commits after it, git describe will return us 1.0.1–10-g1234.
This number can be used as a version.
Environments
We need multiple environments which can be used for development, testing, staging, production, etc., for shipping our code to production. While we can create as many environments as we need, they do make the development life cycle bit complex. Generally, three types of environments work in most cases, so unless there is a very specific need, we should stick with them.
a. Preview environment, where developers can quickly deploy and test their changes before raising a pull request for review.
b. Staging environment, a pre-production environment where the reviewer hosts the changes for final review with different stakeholders.
c. Production environment, as the name suggests, where our running build lives.
In Kubernetes, there is the concept of namespaces, which can give us isolated environments within the same cluster, similar to what VPC does in AWS. So instead of creating a different cluster for each environment, we can use the same cluster and separate them by namespaces (for production we can have a separate one).
Branching Model
The Vincent Gitit flow model has been widely used in industry, we would be listing out few details in considering this model.
Below is the diagram for flow which has been explained in detail:
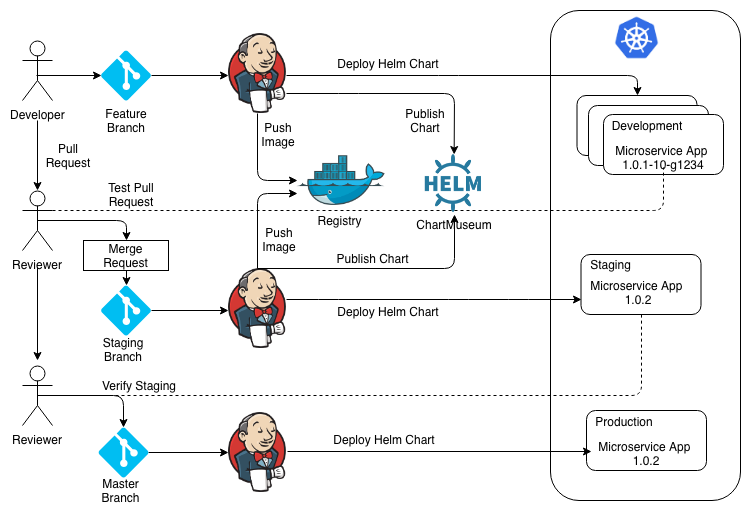
Stage 1: Developer makes changes in the code and tests it locally and then pushes the changes to git which will trigger the Jenkins pipeline. The pipeline will build the new Docker image and tags it with the output of the git describe command and pushes it to Docker registry. The same tag is updated in the Helm chart code and a new chart is pushed as well into the chart museum. In the end, the deployment is done by running the Helm update command against the new version of the chart by Jenkins in development namespace. Finally, the developer raises the pull request.
Stage 2: A reviewer reviews the code and accepts it once he is satisfied and merges into the release branch. The version number also gets updated by removing all the suffixes by incrementing it based on its major/minor/path release, a new Docker image is created with a new tag, and the Helm chart also gets updated with the same tag. Jenkins then runs the Helm update in a staging namespace so it can be verified by others.
Stage 3: If staging looks good, the last step would be to push the changes into production. The Jenkins pipeline won't create new image or chart in this case, it only uses the last Helm chart version and updates the chart in the production namespace.
Overall, CI/CD in general is a complex exercise if the goal is to make it fully automated. Though this article doesn’t cover a lot of details, the information shared can be useful while designing your pipeline. If you are doing this over AWS, spot instances can be used for the preview environment to make it cost-effective.
Published at DZone with permission of Gaurav Vashishth. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments