Operationalizing Data Quality in Cloud ETL Workflows: Automated Validation and Anomaly Detection
Data quality isn’t an afterthought anymore; it is real-time, embedded, and self-healing. Cloud ETL needs smart checks, not checklists. Trust your data before it lies.
Join the DZone community and get the full member experience.
Join For FreeData quality has shifted from a checkpoint to being an operational requirement. As more and more data warehouses become cloud-native, and the complexity of running real-time pipelines increases, data engineers face a non-trivial problem: how to operationalize quality checks without slowing down the velocity of the ETL workflows. “Traditional post-load checks or static rules” do not suffice. Automated validation and anomaly detection in cloud ETL pipelines need to be performed in a manner that adapts to evolving schemas, variable latency, and dynamic business logic.
Why Reactive Data Quality Is No Longer Enough
In the past, data quality was typically validated at the end of an ETL pipeline, often using standalone validation scripts or manual dashboards. This post-hoc approach worked reasonably well in static, batch-oriented data ecosystems. However, in modern cloud environments where data flows through event-driven, streaming, and micro-batch jobs, such passive controls introduce significant latency and operational risk. By the time an issue is detected — sometimes hours or even days later — the damage may already be done.
Consider the example of a global e-commerce platform during a high-traffic campaign weekend. Due to a schema drift in upstream systems, outlier transactions containing malformed or unexpected data were silently dropped or miscategorized. These discrepancies weren't caught in real time. Instead, they became apparent only after downstream analysts noticed inconsistencies in a BI dashboard. By then, key decisions had already been made based on incomplete data, leading to delayed fraud detection, reputational risk, and ultimately financial write-offs.
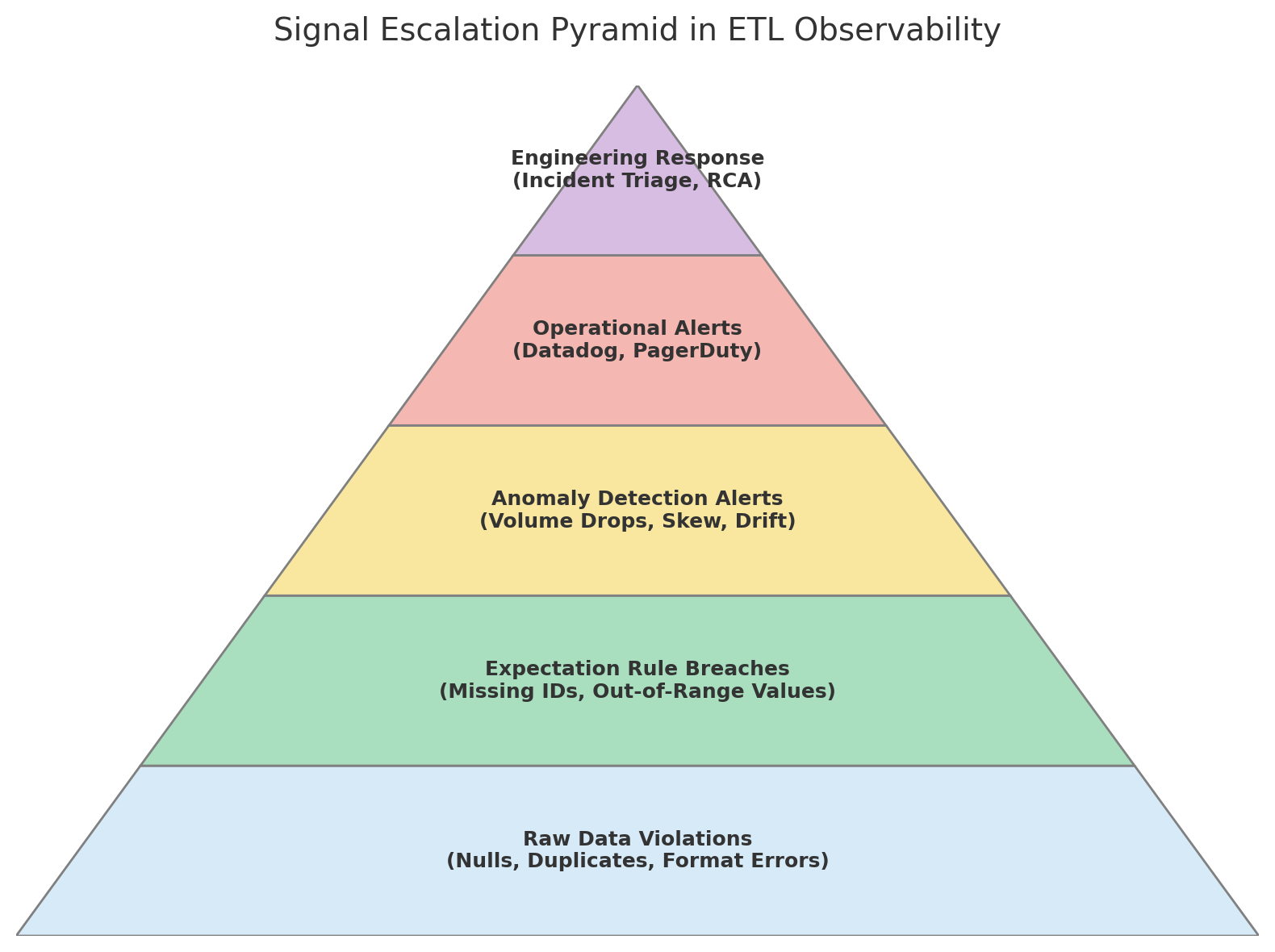
This type of reactive quality control is no longer acceptable in today’s high-speed data environments. Proactive systems are now a core requirement for modern ETL pipelines, especially when operating at scale on platforms like BigQuery, Snowflake, or Redshift. The key shift is embedding validation logic directly within the data orchestration layer — into the DAG (Directed Acyclic Graph) of tools like Apache Airflow or dbt.
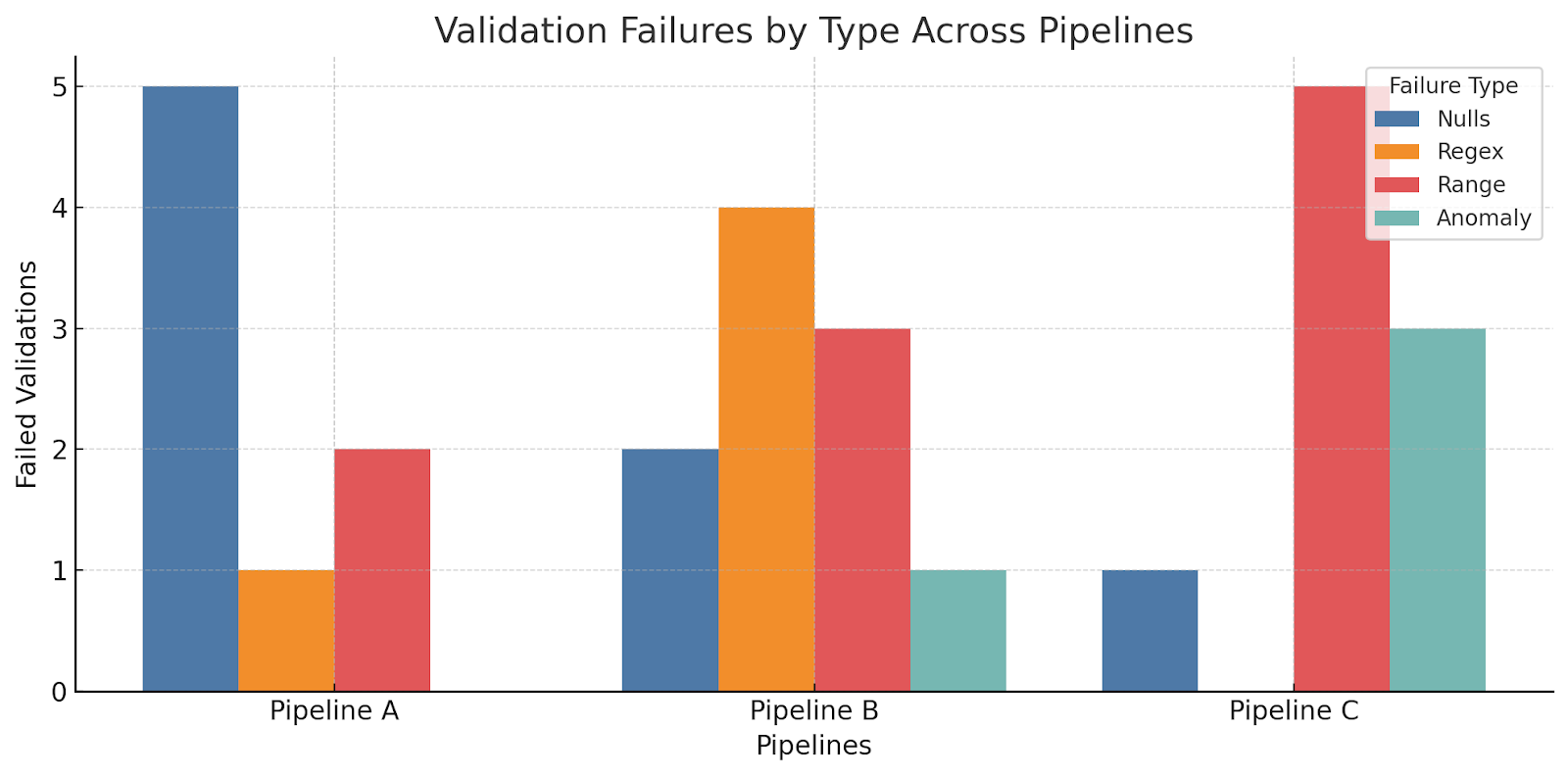
Instead of running a check after data is processed, each transformation step now incorporates column-level profiling, rule-based assertions (such as null value thresholds, regex patterns, or uniqueness constraints), and lightweight statistical checks. This not only validates the structure but also confirms business logic fidelity. If a pipeline step generates data that violates an expectation — for example, a NULL transaction ID in a retail system — it can immediately halt the workflow, trigger an alert, and prevent flawed data from polluting downstream systems.
Proactive validation promotes a “fail-fast” philosophy. It transforms data quality from a downstream concern into a real-time guardrail, protecting dashboards, machine learning models, and operational decisions from preventable errors.
Embedding Automated Validation in Pipeline Logic
Cloud native tools like Apache Airflow, dbt Cloud, or Dataform support embedded testing with DAGs. Take a real-world example where Shopify enforces column-level values for sales data. Shopify uses Great Expectations at the pipeline level in their Airflow DAGs by defining assertions like ‘no NULL in the transaction ID,’ or ‘SKU adheres to standard catalogue pattern.’ However, these are not separate validation jobs, but part of the embedded steps, and a failure can stop downstream data loading or send out a Slack alert before those analysts see a broken report.
This operational integration ensures that pipelines include more than just syntactic success; they also leverage semantic behaviour. The system flags violations before they can hit downstream layers of Looker or Tableau instead of waiting for analysts to report them.
Statistical Anomaly Detection as a Safety Net
Rules have a limit, particularly when changing datasets. Statistical anomaly detection serves as a second layer of defence there, too. Companies such as Intuit leverage anomaly detection to validate ETL by analysing historical distribution patterns and raising an alert when the count of rows, cardinality, or skew is out of skew.
Anomalo and Monte Carlo automatically build historical baselines and identify drift. A great example of this is if you were in a FinOps pipeline working with GCP billing records and suddenly saw a 40% drop in storage records from 1 minute before now. You can see this by comparing the current volume profile against a 14-day rolling median. Schema validation would have missed such drift.
Real-Time Feedback Loops and Engineering Response
The loop is closed by integrating these detections into observability systems. Spotify's pipeline monitoring includes auto-tagged alerts fed into incident response tools. Failed expectations or detected anomalies are logged in Datadog with 'data asset metadata and lineage information', helping on-call engineers quickly identify the impacted table, source system, and downstream dependents.
Besides, failure metadata is logged and used to retrain the anomaly detection threshold and permanently enhance test coverage. Data quality in mature teams becomes a closed programming loop, not a set of one-off rules but a self-improving diagnostic fabric.
Conclusion
Operationalising data quality in cloud ETL workflows involves shifting the posture from reactive inspection to real-time, embedded intelligence. Rule-based validations stop known errors, while anomaly detection surfaces the unknowns. When embedded into orchestration tools, connected to observability platforms, and trained on historical behavior, these systems enable engineers to scale trust as quickly as they scale infrastructure.
Data quality isn’t just a hygiene metric; it’s the foundation of decision integrity. In a world where data drives product personalisation, regulatory reporting, and ML models, building resilient quality pipelines isn’t optional; it’s the cost of doing business at cloud scale.
Opinions expressed by DZone contributors are their own.
Comments