Exploring Apache Airflow for Batch Processing Scenario
In this article, let's explore a simple use case of processing an input file and writing back to the output file using Apache Airflow.
Join the DZone community and get the full member experience.
Join For FreeApache Airflow is an open-source platform that allows you to programmatically author, schedule, and monitor workflows. It uses Python as its programming language and offers a flexible architecture suited for both small-scale and large-scale data processing. The platform supports the concept of Directed Acyclic Graphs to define workflows, making it easy to visualize complex data pipelines.
One of the key features of Apache Airflow is its ability to schedule and trigger batch jobs, making it a popular choice for processing large volumes of data. It provides excellent support for integrating with various data processing technologies and frameworks such as Apache Hadoop and Apache Spark.
By using Apache Airflow for batch processing, you can easily define and schedule your data processing tasks, ensuring that they are executed in the desired order and within the specified time constraints.
Batch processing is a common approach in big data processing that involves the processing of data in large volumes, typically at regular time intervals. This approach is well-suited for scenarios where data can be collected over a period and processed together as a batch.
Within the fintech sector, batch processing caters to a wide range of applications, including but not limited to authorization and settlement processes, management of recurring payments, enabling reconciliation operations, performing fraud detection and analytic tasks, adhering to regulatory mandates, and overseeing changes to customer relationship management systems.
Let's explore a simple use case of processing an input file and writing back to the output file using Apache Airflow.
To get started with Apache Airflow, you can follow the official documentation for installation and setup.
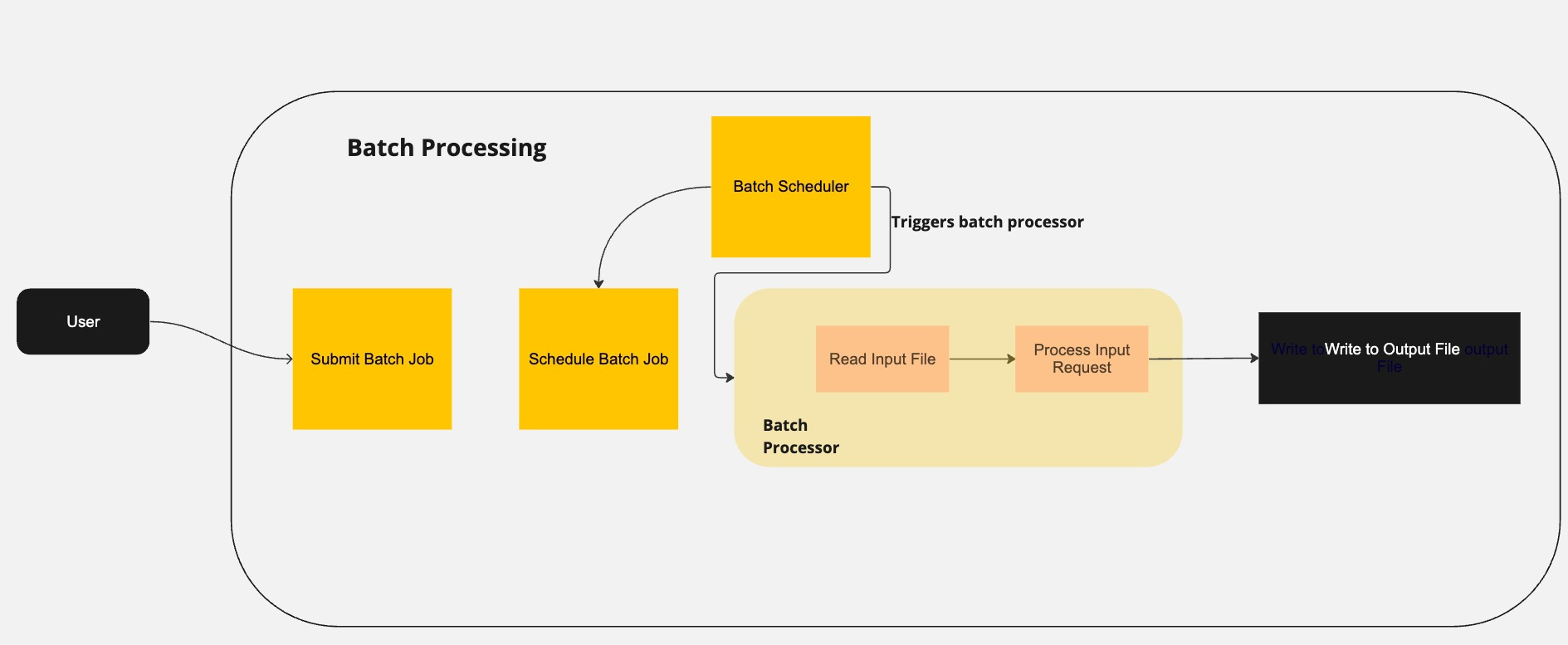
Overview diagram illustrating the basic flow of a batch processing scenario
Setting the Stage
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
# Default arguments for the DAG
default_args = {
'owner': 'airflow',
'start_date': datetime(2021, 1, 1),
'retries': 1,
'retry_delay': timedelta(minutes=5),
}The script begins by importing necessary modules and defining default arguments for the DAG. These default parameters include the DAG owner, start date, and retry settings.
Reading Function: Extracting Data
def read_function(**kwargs):
ti = kwargs["ti"]
# Read from a file (example: input.txt)
with open("path/to/file/input_file.txt", "r") as file:
# Read the remaining lines
lines = file.readlines()
# Push each line to XCom storage
for i, line in enumerate(lines):
ti.xcom_push(key=f"line_{i}", value=line.strip())
# Push the total number of lines to XCom storage
ti.xcom_push(key="num_lines", value=len(lines))The read_function simulates the extraction of data by reading lines from a file (`input.txt`). It then uses Airflow's XCom feature to push each line and the total number of lines into storage, making it accessible to subsequent tasks.
Sample Input File
CardNumber,TransactionId,Amount,TxnType,Recurring,Date
1,123456789,100.00,Debit,Monthly,2023-12-31
2,987654321,50.00,Credit,Weekly,2023-10-15
3,456789012,75.50,Debit,Monthly,2023-11-30
4,555111222,120.75,Credit,Daily,2023-09-30
In the given input file, we can see the handling of a recurring transactions file.
Processing Function: Transforming Data
def process_function(**kwargs):
ti = kwargs["ti"]
# Pull all lines from XCom storage
lines = [ti.xcom_pull(task_ids="read", key=f"line_{i}") for i in range(ti.xcom_pull(task_ids="read", key="num_lines"))]
# Process and print all lines
for i, line in enumerate(lines):
logging.info(f"Make Payment Transaction {i + 1}: {line}")The process_function pulls all lines from XCom storage and simulates the transformation process by printing each line to the console. This task demonstrates the flexibility of Airflow in handling data flow between tasks. The process_function can have multiple implementations, allowing it to either invoke a web service call to execute the transaction or call another DAG to follow a different flow.
Logs
[2023-11-28, 03:49:06 UTC] {taskinstance.py:1662} INFO - Exporting env vars: AIRFLOW_CTX_DAG_OWNER='airflow' AIRFLOW_CTX_DAG_ID='batch_processing_dag' AIRFLOW_CTX_TASK_ID='process' AIRFLOW_CTX_EXECUTION_DATE='2023-11-28T03:48:00+00:00' AIRFLOW_CTX_TRY_NUMBER='1' AIRFLOW_CTX_DAG_RUN_ID='scheduled__2023-11-28T03:48:00+00:00'
[2023-11-28, 03:49:06 UTC] {batch_processing_dag.py:38} INFO - Make Payment Transaction 1: 1,123456789,100.00,Debit,Monthly,2023-12-31
[2023-11-28, 03:49:06 UTC] {batch_processing_dag.py:38} INFO - Make Payment Transaction 2: 2,987654321,50.00,Credit,Weekly,2023-10-15
[2023-11-28, 03:49:06 UTC] {batch_processing_dag.py:38} INFO - Make Payment Transaction 3: 3,456789012,75.50,Debit,Monthly,2023-11-30
[2023-11-28, 03:49:06 UTC] {batch_processing_dag.py:38} INFO - Make Payment Transaction 4: 4,555111222,120.75,Credit,Daily,2023-09-30
[2023-11-28, 03:49:06 UTC] {python.py:194} INFO - Done. Returned value was: NoneWriting Function: Loading Data
def write_function(**kwargs):
ti = kwargs["ti"]
# Pull all lines from XCom storage
lines = [ti.xcom_pull(task_ids="read", key=f"line_{i}") for i in range(ti.xcom_pull(task_ids="read", key="num_lines"))]
# Write all lines to an output file (example: output.txt)
with open("path/to/file/processed.txt", "a") as file:
for i, line in enumerate(lines):
processed_line = f"{line.strip()} PROCESSED"
file.write(f"{processed_line}\n")The write_function pulls all lines from XCom storage and writes them to an output file (`processed.txt`).
Sample Output File After Transaction Is Processed
1,123456789,100.00,Debit,Monthly,2023-12-31 PROCESSED
2,987654321,50.00,Credit,Weekly,2023-10-15 PROCESSED
3,456789012,75.50,Debit,Monthly,2023-11-30 PROCESSED
4,555111222,120.75,Credit,Daily,2023-09-30 PROCESSEDDAG Definition: Orchestrating the Workflow
dag = DAG(
'batch_processing_dag',
default_args=default_args,
description='DAG with Read, Process, and Write functions',
schedule_interval='*/1 * * * *', # Set the schedule interval according to your needs
catchup=False,
)The DAG is instantiated with the name batch_processing_dag, the previously defined default arguments, a description, a schedule interval (running every 1 minute), and the catchup parameter set to False.
Task Definitions: Executing the Functions
# Task to read from a file and push to XCom storage
read_task = PythonOperator(
task_id='read',
python_callable=read_function,
provide_context=True,
dag=dag,
)
# Task to process the data from XCom storage (print to console)
process_task = PythonOperator(
task_id='process',
python_callable=process_function,
provide_context=True,
dag=dag,
)
# Task to write the data back to an output file
write_task = PythonOperator(
task_id='write',
python_callable=write_function,
provide_context=True,
dag=dag,
)Three tasks (read_task, process_task, and write_task) are defined using the PythonOperator. Each task is associated with one of the Python functions (read_function, process_function, and write_function). The provide_context=True parameter allows the functions to access the task instance and context information.
Defining Task Dependencies
# Define task dependencies
read_task >> process_task >> write_taskThe task dependencies are specified using the >> operator, indicating the order in which the tasks should be executed.
Conclusion
In conclusion, Apache Airflow proves to be a flexible open-source tool that is great at managing workflows, especially when it comes to batch processing. It is the best choice for organizations of all sizes because it has features like dynamic workflow definition, support for Directed Acyclic Graphs (DAGs), careful task dependency management, full monitoring and logging, efficient parallel execution, and strong error handling.
Illustrated by a straightforward batch processing scenario, the example emphasizes Apache Airflow's user-friendly interface and its adaptability to a range of data processing needs, showcasing its ease of use and versatility.
Opinions expressed by DZone contributors are their own.
Comments