Cloud Native Deployment of Flows in App Connect Enterprise
The aim of this article is to demonstrate ways to link the logical and operational deployment patterns, i.e., create operational optimization without losing logical design.
Join the DZone community and get the full member experience.
Join For FreeIBM App Connect Enterprise (ACE) is a powerful and widely used integration tool. Developers create integration flows by defining an entry point that receives a message, then processing that message, and finishing by sending or placing the transformed message. Flows consist of a series of nodes and logical constructs. ACE is powerful and flexible — there are many nodes provided specifically to interact with the systems being integrated, however there are also nodes that can run a script or Java code. Because of this, ACE can do pretty much anything, and as such could be considered (although this is not its intended purpose) as an application runtime environment.
An ACE flow is a deployable unit that is inherently stateless, although it can manage its own state. In a traditional server environment, many flows are deployed on an integration server and their execution can be managed and scaled using the workload management features. This makes ACE a natural fit for a Kubernetes environment.
It is therefore tempting to consider an ACE flow as a microservice and deploy each flow to a cloud in that way. Whilst this is certainly possible, there are many considerations to ensure a successful deployment of ACE on Kubernetes.
The Problem
Deployment Overhead
Deploying many microservices can result in increased resource overhead compared to traditional application server architectures. Each microservice requires its own operating system and instance of whatever runtime it is using. In ACE terms, this means creating many integration servers with one flow on each. However, an integration server itself requires resources.
Consider an application with 100 flows deployed on a server with 4 CPUs and 8GB of RAM. Some of the flows are used heavily throughout the business day, but some are only called once a day for a batch job in the evening. During high usage the busy flows can consume most of the CPU. At peak times they will slow down a bit because they compete for CPU, but this is okay because the CPU can manage many threads. The flow instances handling the batch job will remain idle, consuming no CPU until they are needed when the busy flows are idle.
In ACE 12.0.5 and above, the effective minimum CPU requirement is 0.1 CPU and 350MB of memory, so in an application with 100 flows that’s a minimum of 10 CPUs and 35GB of memory which is a significant increase in terms of both infrastructure and license cost. Not only that, but in this example every flow has the minimum allocated CPU at all times, which is nowhere near enough for the busy flows and far more than the once-per-day flows need.
Logical vs. Operational Optimization
It is possible to analyze the requirements of all your flows and group together flows based on release schedule, demand profile, common connections/assets and so on (see section Efficiency of Scaling Grouped Flows). These criteria would be purely operational, and this could be an entirely valid way of doing it. However, there would be no relationship between where a flow is deployed and its function. Pods and deployments would not have names that identified their functions. This may be possible in a highly automated DevOps setup, but this may not be ideal for most projects.
On the other hand, deploying one flow per pod maps deployments perfectly to logical functions — your flow and its pod would have a name relating to its function. Generally modern apps rely on naming conventions and design related to logical function to reduce the need for documentation and make the project as easy and transparent as possible to work on. Software applications are created and maintained by humans after all, and humans need things to be clear and straightforward from a human perspective. But as we have seen this is not necessarily feasible in a large ACE project. The aim of this document is to demonstrate ways to link the logical and operational deployment patterns — in other words, to create operational optimization without losing logical design.
ACE vs. Other Runtimes
If microservices can be deployed in their own pods and scaled as required, what is the difference between ACE and other microservice runtimes such as Open Liberty or NodeJS?
- Start-up time and cost: Integrations deployed in BAR files need to be compiled before use. If uncompiled BAR files are deployed this adds a CPU spike on start-up. This can also be picked up by the horizontal pod autoscaler.
- License cost: Since ACE is proprietary software it adds license cost.
Performance Planning
Pods vs. Instances
One of the key concepts of cloud-native microservice architecture is that multiple instances of a service can exist, and state should be stored outside the instance. This means that as many instances as are needed can be deployed. This can be determined at design time, and can be altered whilst running either as a manual operation or automatically according to load.
In Kubernetes, a microservice is represented as a deployment, and this creates a given number of pods which are service instances. The number of pods can be scaled up or down.
A Kubernetes cluster should have multiple worker nodes, to provide redundancy. Because it is a distributed system, there should also be an odd number of nodes, so that if one fails the other two still constitute a quorum. In practice, this means three worker nodes. This then dictates that deployments should have three pods — one on each node — to spread the load appropriately. It is possible to configure deployments to deploy more pods (via a horizontal pod autoscaler or HPA) to provide more processing power when demand is high.
Pod Scaling vs. ACE Workload Management
ACE includes native workload management features, one of which is the ability to create additional instances of a deployed message flow within the integration server in the pod as opposed to more pods. Additional instances correspond to additional processing threads. It is possible to start with zero additional instances (i.e., one instance) and set the integration server to create new instances on demand up to a maximum value. The additional instances will be destroyed when no longer needed, and their onward connections (e.g., to a DB) will be closed, however the RAM will not be released back to the OS. So whilst pod CPU usage will return to lower levels RAM will not. This may or may not be a problem depending on your constraints — RAM usage does not affect license cost, however the infrastructure still needs to be provisioned and paid for. Therefore, the additional instances property should be carefully considered in conjunction with Kubernetes pod scaling.
Additional flow instances are much more resource-efficient than additional pods containing integration servers. The number of additional instances must be determined in conjunction with the number of CPUs allocated to the pod:
- If a flow is an asynchronous process, e.g., reading from a queue and writing to another, then it can be busy almost all the time assuming the processing done by the flow is CPU intensive. If that is the case then the total number of flow instances (bear in mind that zero additional instances means one total instance) should match the number of CPUs configured on the pod.
- However, if a flow is a synchronous process e.g., it calls a downstream HTTP service or a database, then the flow will be blocked waiting for that downstream service to complete, during which time the thread would be idle. If a flow spends 50% of its time idle waiting for a downstream response and 50% of its time processing the results, then two flow instances (i.e. one additional) can be configured in a pod that has one CPU. Of course, you could create two pods instead of two flow instances, but this is much less efficient because of the overhead of running second pod and an entire integration server inside it.
For a synchronous flow, the following equation is a good starting point if you can measure the CPU utilization when running a single instance:
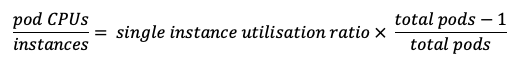
If you are analyzing performance using timings printed out in debugging statements or the user trace features, or using the CP4I tracing tool, then you should know how long the total flow execution takes and how long is spent waiting for a downstream service call. If so, then the equation can be written as follows:
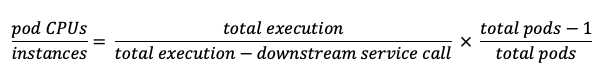
If pods are configured like this, then the CPU of the pod should be well utilized, but not so much so that a single pod restarting or failing will cause the others to be overloaded. Of course, if a flow is configured to have two flow instances, then each new pod results in two more flow instances at a time.
The benefit of using the HPA for scaling over is that when load decreases the additional pods will be destroyed, which will release resources. The disadvantage is that more resources are required for the extra pod overhead. In general, the workload management properties should be used for modest scaling, and the HPA used sparingly for highly elastic demand — for example, a bank that needs to deploy large numbers of pods at the end of each month for paydays, or for a retailer needing to handle a Black Friday sale.
When using the HPA, it is important to realize that ACE integration servers can have high start-up CPU load if BAR files are not pre-compiled, or if flows are written with start-up tasks e.g., cache building, resource loading etc. The HPA may pick up this high CPU usage on start-up and start deploying more pods, which will then need to start up as well — and this could cause runaway resource consumption. To overcome this, configure a stabilization window on your HPA.
Performance tuning is of course a complex subject, and a detailed description of ACE performance tuning is outside the scope of this document.
Scheduled Scaling
An alternative to using the HPA is to use a tool like KEDA to provide scaling based on events such as external messages, or according to a schedule. For example, an e-commerce organization could scale-up pods in advance of a product being released or a discount event. This has the benefit of being proactive rather than reactive, like the HPA.
Grouping Flows Operationally
With a typical application containing many hundreds of flows we know that we will need to group them together on the same integration servers and therefore pods. There are several operational and deployment/packaging criteria that can be used for this.
- Group integrations that have stable and similar requirements and performance.
- Group integrations with common technical dependencies. A popular use case is dependency on MQ.
- Group integrations where there are common cross dependencies, i.e., integrations completely dependent on the availability of other integration.
- Group integrations that have common integration patterns, e.g., sync vs. async. Synchronous calls between flows are much better done in the same integration server because they can use the callable flow pattern rather than HTTP interaction which would be much less efficient.
- Group integrations with common or similar scalability model is needed.
- Group integrations with common or similar resilience (high availability) model is needed.
- Group integrations with common or similar shared lifecycle. A common situation where this may occur is where integrations use shared data models, libraries, etc.
- Group integrations that require common Integration Server runtime components i.e., C++, JVM, NodeJS, etc. to leverage and optimize deployment using the new Dynamic Resource Loading feature.
Logical Patterns for Grouping Flows
Large enterprise applications depend on consistent design principles for manageability and quality. Choosing specific design patterns for implementation helps this greatly. Integration flows can be deployed anywhere and will still work, however this kind of deployment will make it hard to create logical groupings. Here we will look at patterns into which integration flows fit; if the physical deployments follow the logical architecture the flows will be easier to manage.
Here are some examples of ideas that could help to group flows by business function and/or integration style, so that they will still fit into a microservice concept.
Composite Service
Consider a system where ACE is acting as a wrapper for downstream services. Each flow invokes a single operation on a downstream service. Related flows, for example, flows that invoke database stored procedures to create, update or delete customer records, can be grouped into a single Application and deployed on their own integration server. When considered this way, the deployed integration server becomes the customer management service. Workload management can be used statically (i.e., selecting "deploy additional instances at startup") to set the number of instances for each thread relative to the others, if some flows need to handle more traffic than others.
Message Hub/Broker
If your application has flows that place messages onto queues or Kafka topics, it might be worth considering these as related functions and grouping them all into a single Application deployed in a single pod, called a Message Hub or Broker.
Business Function
Grouping by business functional area into single services reduces scaling flexibility, which ultimately results in less efficiency — if one flow is overloaded and a new pod is scaled up, then new capacity for other flows may be created and not needed. But, if suitable CPU request and limits are configured, and workflow management, this may ultimately be more efficient in terms of absolute CPU use.
Efficiency of Scaling Grouped Flows
In an ideal microservice environment, each flow would be a microservice that could be scaled independently. However, due to the inherent overhead of integration server pods, this is not efficient as we have seen. If flows are grouped together though, then when scaling one flow you may end up with instances of other flows that you don’t need. This is also inefficient. But in some circumstances it may still be more efficient than multiple pods.
Consider two flows, A and B each in their own pod. Each might initially be using only a negligible amount of CPU, but the minimum requirement for each pod is 0.1 so that is the CPU request. Replicated across three nodes that means 0.6 CPU request. Let’s assume that the flows are single threaded, so the limit for each pod should be 1 CPU. That means that the upper limit is 6 CPU. Now, if flow A becomes very busy that means a maximum of 3.3 CPU used by both flows — 3 from three instances of flow A and the original 0.3 from three instances of flow B. If it becomes even busier, you can scale deployment A up by one pod so there are four flow A pods, and this means the total CPU is now 4.3 CPU.
If flows A and B are both deployed in the same pod, then when traffic is low the total request is only 0.3 CPU. When flow A becomes busy, this becomes 3 CPU. When it scales up to 4 pods, the total is 4 CPU. Flow B has been deployed twice but since it is not using significant CPU flow A still has the resources it needs.
In this scenario, the extra overhead of deploying the two flows independently is greater than the cost of duplicating flow B unnecessarily.
Node Level Licensing
IBM licenses pods based on the specified CPU limits. However, if ACE pods are restricted to running on a single worker node IBM will not charge more than the CPUs available to that node. This means that pod affinity can be used to deploy ACE only on certain nodes. If no CPU limits are set, then any of the pods can use as much CPU resources as are available to the node, and the node’s operating system can schedule the threads as it sees fit in the same way that it does in a non-container environment. This can be a useful technique when doing a lift-and-shift migration from a non-container environment.
Published at DZone with permission of Ben Cornwell. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments