Compliance Automated Standard Solution (COMPASS), Part 5: A Lack of Network Boundaries Invites a Lack of Compliance
In this article, we share our experience in authoring compliance policies that go deeper than configuration management.
Join the DZone community and get the full member experience.
Join For Free(Note: A list of links for all articles in this series can be found at the conclusion of this article.)
This post is part of a series dealing with Compliance Management. The previous post analyzed three approaches to Compliance and Policy Administration Centers. Two were tailored CPAC topologies that support specialized forms of policy. The third CPAC topology was for cloud environments and the attempt to accommodate the generic case of PVPs/PEPs with diverse native formats across heterogeneous cloud services and products. It is easy to see how these approaches can be used for configuration checks, but some controls require implementation that relies on higher-level concepts. In this article, we share our experience in authoring compliance policies that go deeper than configuration management.
There are numerous tools for checking the compliance of cloud-native solutions, yet the problem is far from being solved. We know how to write rules to ensure that cloud infrastructure and services are configured correctly, but compliance goes deeper than configuration management. Building a correct network setup is arguably the most difficult aspect of building cloud solutions, and proving it to be compliant is even more challenging.
One of the main challenges is that network compliance cannot be deduced by reasoning about the configuration of each element separately. Instead, to deduce compliance, we need to understand the relationships between various network resources and compute resources.
In this blog post, we wanted to share a solution we developed to overcome these challenges because we believe this can be useful for anyone tackling the implementation of controls over network architectures. We are specifically interested in the problem of protecting boundaries for Kubernetes-based workloads running in a VPC, and we focus on the SC-7 control from the famous NIST 800-53.
Boundaries are typically implemented using demilitarized zones (DMZs) that separate application workloads and the network they’re deployed in from the outside (typically the Internet) using a perimeter network that has very limited connectivity to both other networks. Because no connection can pass from either side without an active compute element (e.g., a proxy) in the perimeter network forwarding traffic, this construct inherently applies the deny by default principle and is guaranteed to fail secure in case the proxy is not available.
Modern cloud-native platforms offer a broad range of software-defined networking constructs, like VPCs, Security Groups, Network ACLs, and subnets that could be used to build a DMZ. However, the guideline for compliance programs like FedRAMP is that only subnets are valid constructs for creating a boundary.
Encapsulating the general idea of boundary protection is too difficult, as there are numerous ways to implement it and no way to automate enforcement and monitoring for violations. Instead, we have architectural guidelines that describe a particular method for building a compliant architecture using DMZs. This post shows how to automate compliance checking against a specific architectural design of DMZs. The core ideas should be easily transferable to other implementations of boundary protection.
Our goal is to control access to public networks. The challenge is determining which parts of the architecture should have access to the external network. The solution is to have humans label network artifacts according to their intended use. Is this for sensitive workloads? Is this an edge device? Given the right set of labels, we can write rules that automatically govern the placement of Internet-facing elements like gateways and verify that the labeling is correct.
As we’ve established earlier, DMZs provide us with the right set of attributes for creating a boundary. If we can label networks such that we can infer the existence and correctness of a DMZ within the network design, we’ve essentially validated that there is a network boundary between two networks that fulfills the deny-by-default and fail-secure principles, thereby proving compliance with SC7(b).
A DMZ fundamentally divides the application architecture into three different trust-zones into which applications could be deployed. Suppose we can reason about the relationship between trust-zones and the placement of applications in trust-zones. In that case, we should be able to infer the correctness of a boundary.
Our boundary design consists of three trust-zones.
- A private trust-zone is a set of subnets where compute elements are running the application.
- The edge trust-zone is a set of subnets that provide external connectivity, typically the Internet.
- The public trust-zone is everything else in the world.
While the ideas and concepts are generic and will work for virtual machines and Kubernetes or other compute runtimes, we’ll focus on Kubernetes for the remainder of this article.
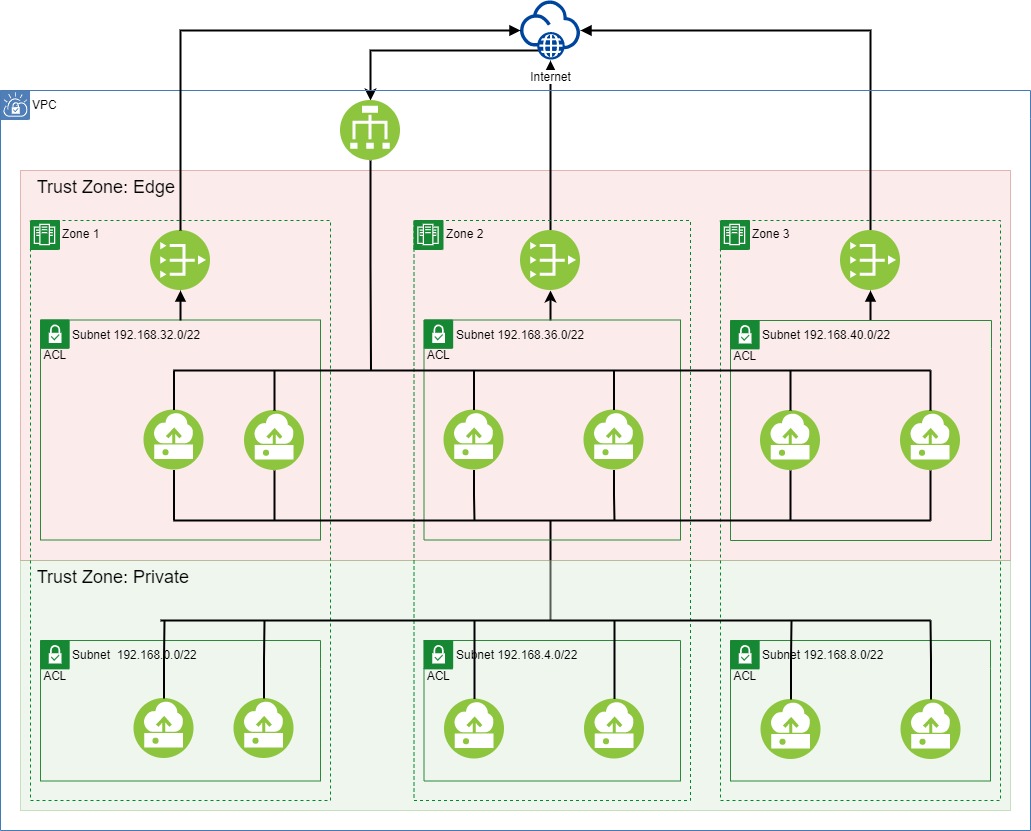
Using the Kubernetes approach for taints and tolerations, we can control in which trust-zone workloads can be deployed. Since the edge trust-zone is critical for our boundary, we use an allow-list that defines what images can be placed in the edge trust-zone. The following set of rules (some would call them “controls”) encapsulate the approach we described above.
- R1[Tagging]: Each subnet must be labeled with exactly one of the following: ‘trust-zone:edge,’ ‘trust-zone:private’
- R2[PublicGateway]: A public gateway may only be attached to subnets labeled ‘trust-zone:edge’
- R3[Taint]: Cluster nodes running in a subnet labeled ‘trust-zone:edge’ must have a taint ‘trust-zone=edge:NoSchedule’
- R4[Tolerance]: Only images that appear on the “edge-approved” allow list may tolerate ‘trust-zone=edge:NoSchedule’
If all rules pass, then we are guaranteed that application workloads will not be deployed to a subnet that has Internet access. It is important to note that to achieve our goal, all rules must pass. While in many compliance settings, passing all checks except for one is fine, in this situation, boundary protection will be guaranteed only if all four rules pass.
Whenever we show people this scheme, the first question we get asked is: what happens if subnets are labeled incorrectly? Does it all crumble to the ground? The answer is: no! If you label subnets incorrectly, at least one rule will fail. Moreover, if all four rules pass then, we have also proven that subnets were labeled correctly. So let’s break down the logic and see how this works.
Assuming that all rules have passed, let’s see why subnets are necessarily labeled correctly:
- Rule R1 passed, so we know that each subnet has only one label. You couldn’t have labeled a subnet with both “edge” and “private” or anything similar.
- Rule R2 passed, so we know that all subnets with Internet access were labeled “edge.”
- Rule R3 passed, so we know that all nodes in subnets with Internet access are tainted properly.
- Rule R4 passed, so we can conclude that private workloads cannot be deployed to subnets with Internet access.
It is still possible that a subnet without Internet access was labeled “edge”, so it cannot be used for private workloads. This may be a performance issue but does not break the DMZ architecture.
The above four rules set up a clearly defined boundary for our architecture. We can now add rules that enforce the protection of this boundary, requiring the placement of a proxy or firewall in the edge subnet and ensuring it is configured correctly. In addition, we can use tools like NP-Guard to ensure that the network is configured not to allow flows that bypass the proxy or open up more ports than what is strictly necessary.
The edge trust-zone, however, needs broad access to the public trust-zone. This is due to constructs like content delivery networks that use anycast and advertise thousands of hostnames under a single set of IPs. Controlling access to the public trust-zone based on IPs is thus impractical, and we need to employ techniques like TLS Server Name Indicator (SNI) on a proxy to scope down access to the public trust-zone from other trust-zones.
Of course, different organizations may implement their boundaries differently. For example, in many use cases, it is beneficial to define separate VPCs for each trust-zone. By modifying the rules above to label VPCs instead of subnets and checking the placement of gateways inside VPCs, we can create a set of rules for this architecture.
To validate that our approach achieves the intended outcome, we’ve applied it to a set of VPC-based services. We added our rules to a policy-as-code framework that verifies compliance. We implemented the rules in Rego, the policy language used by the Open Policy Agent engine, and applied them to Terraform plan files of the infrastructure. We were able to recommend enhancements to the network layout that further improve the boundary isolation of the services. Going forward, these checks will be run on a regular basis as part of the CI/CD process to detect when changes in the infrastructure break the trust-zone boundaries.
Below are the links to other articles in this series:
- Compliance Automated Standard Solution (COMPASS), Part 1: Personas and Roles
- Compliance Automated Standard Solution (COMPASS), Part 2: Trestle SDK
- Compliance Automated Standard Solution (COMPASS), Part 3: Artifacts and Personas
- Compliance Automated Standard Solution (COMPASS), Part 4: Topologies of Compliance Policy Administration Centers
- Compliance Automated Standard Solution (COMPASS), Part 6: Compliance to Policy for Multiple Kubernetes Clusters
- Compliance Automated Standard Solution (COMPASS), Part 7: Compliance-to-Policy for IT Operation Policies Using Auditree
Opinions expressed by DZone contributors are their own.
Comments