Configuring Apache SolrCloud on Amazon VPC
Join the DZone community and get the full member experience.
Join For FreeWe are going to construct an Apache SolrCloud (4.1) with 12 node EC2 instance(s) inside Amazon VPC in this post. Since the search data stored inside the SolrCloud is critical, we are going to build High availability at Solr Node level as well as AZ level. This setup will be done inside private subnet of Amazon VPC and will leverage 3 Availability Zones of the Amazon EC2 Region.
Deployment architecture of the setup is given below:

A small brief about setup:
- 3 Zookeepers will be deployed on 3 Availability Zones. ZK EC2 instances will be deployed on the Private subnet of the Amazon VPC.
- 3 Solr Shard EC2 instances will be deployed on Private subnet of Availability Zone 1 inside Amazon VPC.
- 3 Solr Replica EC2 instances will be deployed on Private subnet of Availability Zone 2 inside Amazon VPC.
- 3 Solr Replica EC2 instances will be deployed on Private subnet of Availability Zone 3 inside Amazon VPC.
- EBS optimized + PIOPS EC2 instances can be used for Solr EC2 Nodes
To know more about SolrCloud Deployment best practices on Amazon VPC, Refer article: http://harish11g.blogspot.in/2013/03/Apache-Solr-cloud-on-Amazon-EC2-AWS-VPC-implementation-deployment.html |
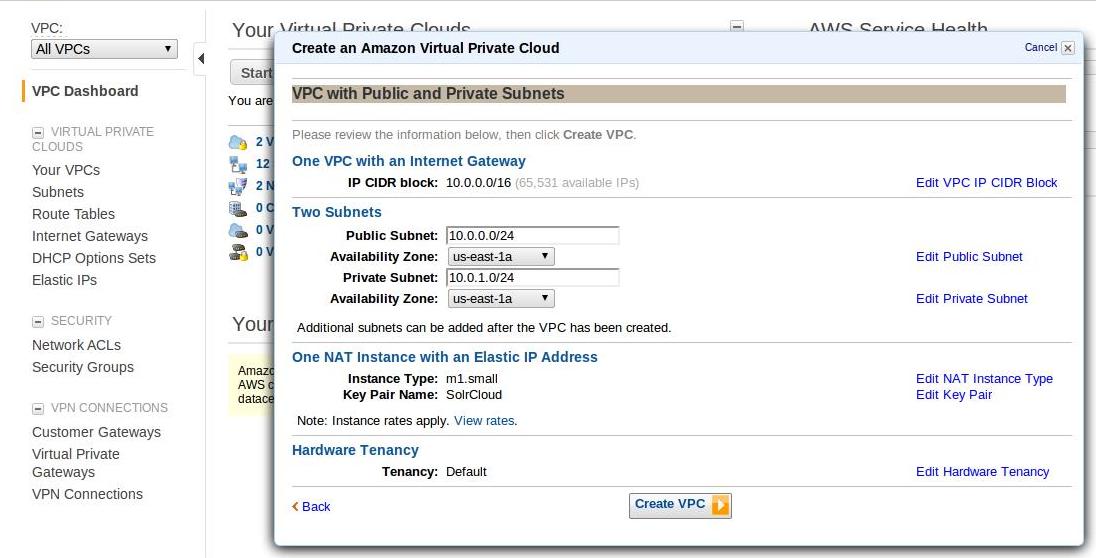
Step 1: Creating Virtual Private Cloud on AWS
Create a VPC with Public and Private Subnets. Assume the Load balancer and Web/App Servers can reside on the public subnet and Apache Solr Cloud will reside on the private subnet of the VPC.

Step 2: Assigning the IP for the Subnets
Create the subnet with its IP range. Chose the Availability zone for this subnet.
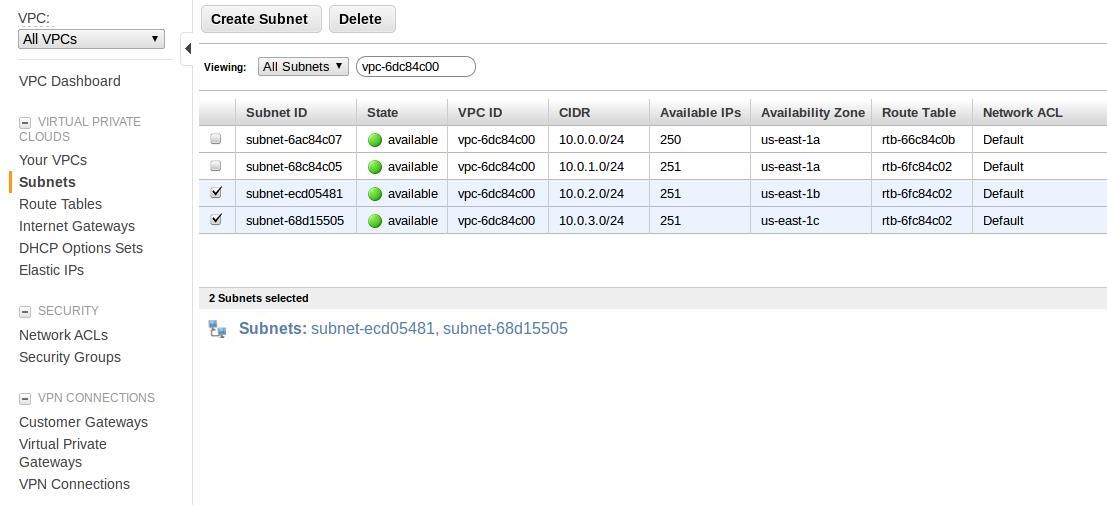
Step 3: Multiple Subnets on Multiple AZ’s
Create multiple subnets in Multiple AZ for building a Highly available setup for SolCloud
Step 4: Install Java for Zookeeper & Solr
Amazon Linux is chosen as the EC2 OS variant. Execute the following instructions on the respective EC2 nodes after their launch. EC2 instances should be launched in Multi-AZ in Multiple VPC Private Subnets.
Solr uses Zookeeper as the cluster configuration and coordinator. Zookeeper is a distributed file system containing information about all the Solr Nodes. Solrconfig.xml, Schema.xml etc are stored in the repository.We have used Oracle-Sun Java over OpenJDK
“sudo -s” “cd /opt” “wget --no-cookies --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2Ftechnetwork%2Fjava%2Fjavase%2Fdownloads%2Fjdk-7u3-download-1501626.html;" http://download.oracle.com/otn-pub/java/jdk/7u13-b20/jdk-7u13-linux-x64.rpm” “mv jdk-7u10-linux-x64.rpm?AuthParam=1357217677_76ec3d8d9a3644f4b9ec1ea79e1fcf33 jdk-7u10-linux-x64.rpm jdk-7u10-linux-x64.rpm” “sudo rpm -ivh jdk-7u10-linux-x64.rpm” “alternatives --install /usr/bin/java java /usr/java/jdk1.7.0_10/jre/bin/java 20000” “alternatives --install /usr/bin/javaws javaws /usr/java/jdk1.7.0_10/jre/bin/javaws 20000” “alternatives --install /usr/bin/javac javac /usr/java/jdk1.7.0_10/bin/javac 20000” “alternatives --install /usr/bin/jar jar /usr/java/jdk1.7.0_10/bin/jar 20000” “alternatives --install /usr/bin/java java /usr/java/jre1.7.0_10/bin/java 20000” “alternatives --install /usr/bin/javaws javaws /usr/java/jre1.7.0_10/bin/javaws 20000” “alternatives --configure java” Add JAVA_HOME in .bash_profile: “vim ~/.bash_profile” export JAVA_HOME="/usr/java/jdk1.7.0_09" export PATH=$PATH:$JAVA_HOME/bin Restart the instance. “init 6” Check the version of Java installed using “java -version” command |
Step 5: Configure the ZooKeeper (v3.4.5) Ensemble:
Since single Zookeeper is not ideal for a large Solr cluster (because of SPOF), it is recommended to configure multiple Zookeepers in concert as an ensemble .In this step we will install and configure 3 ZooKeeper EC2 nodes spanning across 3 different Availability Zones in respective Private Subnets inside a VPC.Zookeeper will be configured on Amazon Linux.
“sudo yum update” “sudo -s” “ cd /opt” “wget http://apache.techartifact.com/mirror/zookeeper/zookeeper-3.4.5/zookeeper-3.4.5.tar.gz” “tar -xzvf zookeeper-3.4.5.tar.gz” “rm zookeeper-3.4.5.tar.gz” “cd zookeeper-3.4.5” “cp conf/zoo_sample.cfg conf/zoo.cfg” Add the following lines in zoo.cfg “vim conf/zoo.cfg” dataDir=/data server.1=[zk-server01-ip]:2888:3888 server.2=[zk-server02-ip]:2888:3888 server.3=[zk-server03-ip]:2888:3888 “cd /opt/zookeeper/data” “vim myid” 1 or 2 or 3 respectively on each ZooKeeper EC2 instances in Multi-AZ #Starting ZooKeeper Program. “bin/zkServer.sh start” |
- Follow the above steps in all the ZooKeeper servers. ReferClustered (Multi-Server) SetupandConfiguration Parameters for understanding
quorum_port,leader_election_portand the filemyid. - Every ZooKeeper node needs to know about every other ZK EC2 node in the ensemble, and a majority of EC2’s (called a Quorum) are needed to provide the service. Make sure the VPC IP of all the Zookeepers are given in every ZK node, like the one in following command.
- server.1=<ip>:<quorum_port>:<leader_election_port>
- server.2=<ip>:<quorum_port>:<leader_election_port>
- server.3=<ip>:<quorum_port>:<leader_election_port>
Step 6: Configuring Solr 4.1 EC2 node
In this step we will install and configure 3 Apache Solr4.1 Shard EC2 instances in a single Amazon AZ and 2 Solr Replicas in another AZ in their respective Private subnets. Please note that we have to specify all the ZooKeeper (ZK) hosts on every Solr instance as below.
Note: Solr gets comes with jetty in default, it is suggested to use tomcat for production nodes.
Perform the following after launching EC2 instances in Multi-AZ in Multiple VPC Private Subnets.
“sudo -s” “yum update” “cd /opt” “wget http://apache.techartifact.com/mirror/lucene/solr/4.1.0/apache-solr-4.1.0.tgz” “tar -xzvf apache-solr-4.1.0.tgz” “rm -f apache-solr-4.1.0.tgz” On Solr Shard/Replica Instances: “cd /opt/apache-solr-4.0.0/example/” “vim /opt/apache-solr-4.0.0/example/solr/collection1/conf/solrconfig.xml” Change <dataDir>/var/data/solr</dataDir> to <dataDir>/data</dataDir> Starting Solr4.1 Shard/Replica Java Program. “java -Dbootstrap_confdir=./solr/collection1/conf -Dcollection.configName=SolrCloud4.1-Conf -DnumShards=3 -DzkHost=[zk-server01-ip]:2181,[zk-server02-ip]:2181,[zk-server03-ip]:2181 -jar start.jar “java -DzkHost= DzkHost=<server1_ip>:<client_port>,<server2_ip>:<client_port>,<server3_ip>:<client_port> -jar start.jar” |
- -DnumShards: the number of shards that will be present. Note that once set, this number cannot be increased or decreased without re-indexing the entire data set. (Dynamically changing the number of shards is part of the Solr roadmap!)
- -DzkHost: a comma-separated list of ZooKeeper servers.
- -Dbootstrap_confdir, -Dcollection.configName: these parameters are specified only when starting up the first Solr instance. This will enable the transfer of configuration files to ZooKeeper. Subsequent Solr instances need to just point to the ZooKeeper ensemble.
- The above command with –DnumShards=3 specifies that it is a 3-shard cluster. The first Solr EC2 node automatically becomes shard1 and the second Solr EC2 node automatically becomes shard2 …. What happens when we launch fourth Solr instance in this cluster? Since it’s a 3-shard cluster, the fourth Solr EC2 node automatically becomes a replica of shard1 and the fifth Solr EC2 node becomes a replica of shard2.
Step 7: AWS Security Group TCP Ports to be enabled:
Configure the following TCP ports on the AWS security group to allow access between Solr and ZK nodes deployed in Multiple AZ.
- Solr Shards/Replicas will connect to ZK through TCP Port 2181
- Solr Web Interface with Jetty container through TCP Port 8983
- Solr Web Interface with Tomcat container through TCP Port 8080
- Every instance that is part of the ZooKeeper ensemble should know about every other machine in the ensemble. We can accomplish this with the series of lines of the form server.id=host:port:port For example,
- server.1=[vpc-ip]:2888:3888
- server.2=[vpc-ip]:2888:3888
- server.3=[vpc-ip]:2888:3888
- TCP Ports 2888, 3888 should be opened for ZK Ensemble.
Opinions expressed by DZone contributors are their own.
Comments