Creating a Distributed Computing Cluster for a Data Base Management System: Part 1
An introduction to DCC—a proxy-driven way to merge many DB servers into one virtual DBMS—and how it can scale read-heavy workloads with only modest transaction overhead.
Join the DZone community and get the full member experience.
Join For FreeIdeas of creating a distributed computing cluster (DCC) for database management systems (DBMS) have been striking me for quite a long time. If simplified, the DCC software makes it possible to combine many servers into one super server (cluster), performing an even balancing of all queries between individual servers. In this case, everything will appear for the application running on the DCC as if it was running with one server and one database (DB). It will not be dispersed databases on distributed servers, but work as one virtual one. All network protocols, replication exchanges, and proxy redirections will be concealed inside the DCC. At the same time, all resources of distributed servers, in particular RAM and CPU time, will be utilized evenly and in an efficient fashion.
For example, in a cloud data processing center (DPC), it is possible to take one physical super server and divide it into a number of virtual DBMS servers. But the reverse procedure was not possible until now, i.e., it is not possible to take a number of physical servers and merge them into a single virtual DBMS super server. In some specified sense, DCC is a technology that makes it possible to merge physical servers into one virtual DBMS super server.
I will take the liberty to make another comparison: DCC is just the same as the coherent nonuniform memory access (NUMA) technology except that it is used to merge SQL servers. But unlike NUMA, in DCC, software handles the synchronization (coherence) of the data and partly of the RAM, not the controller.
For the sake of clarity, below is a diagram of the well-known connection of the client application to the DBMS server, and the DCC diagram immediately below that. Both diagrams are simplified, just for easy understanding.
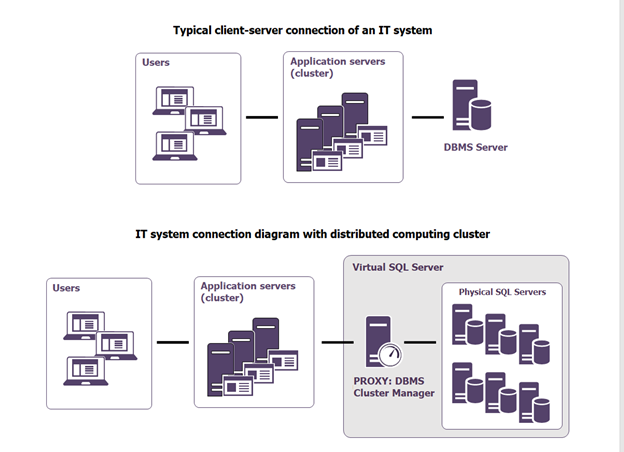
The idea behind the cluster is a decentralized model. In the figure above there is only one proxy server, but in general there can be more than one.
This solution will result in the possibility to increase the DBMS scalability by a substantial margin relative to a typical single-server solution with the most powerful server at the moment. No such solution currently exists, or, at least, no one in my vast professional community is aware of such a solution.
After five years of research, I worked out the logical architecture and interaction protocols in detail and, with the assistance of a handful of development personnel, created a working prototype that is undergoing load tests on a popular 1C8.x IT system under the management of PostgreSQL DBMS. MS SQL or Oracle may be the DBMS. Fundamentally, the choice of DBMS does not affect the ideas I will bring up.
With this article, I am starting a series of articles on DCC, where I will gradually disclose one or another issue and offer solutions to them. I came up with this structure after speaking at one of the IT conferences, where the topic was found to be quite difficult to understand. The first article will be introductory, I will hit the peaks, skip the valleys (emphasizing non-obvious assertions), and outline what's to come in the following publications.
For Which IT Systems DCC Is Effective
The idea of DCC is to create a special software shell, which will perform all write requests simultaneously and synchronously on all servers, and read requests will be performed on a specific node (server) with user binding. In other words, users will be evenly distributed among the servers of the cluster: read requests will be executed locally on the server to which the user is bound, and change requests will be synchronously executed simultaneously on all servers (no logic violations will occur as a result).
Therefore, provided that read requests significantly exceed write requests in terms of load, we get a roughly uniform load distribution among DCC servers (nodes).
Let's first review this question: is the statement that the load of read requests far outweighs the load of write requests correct? To answer this question, it will be helpful to look back a bit at the history of the SQL language: what was the goal and what eventually came to fruition.
A Quick Dive Into SQL
SQL was originally planned as a language that could be used without programming or math skills.
Here's an excerpt from Wikipedia:
Codd used symbolic notation with mathematical notation of operations, but Chamberlin and Boyce wanted to design the language so that it could be used by any user, even those without programming skills or knowledge of math.[5]
For now, it can be argued that programming skills for SQL are still needed, but definitely minimal. Most programmers have studied some basics of query optimization and have never heard of SQL Tuning by Dan Toe. A lot of logic for optimizing queries is concealed inside the DBMS. In the past, for example, MS SQL had a limit of 256 table joins; now in modern IT systems, it is common to have thousands of joins in a query. Dynamic SQL, where a query is constructed dynamically, is used widely and sometimes without much thought. The truth is there is no mathematically accurate model for plotting the optimal plan for executing a complex query. This problem is somewhat similar to the traveling salesman problem, and it is believed to have no exact mathematical solution.
The conclusion is as follows: SQL queries have evolutionarily proven their effectiveness and almost all reporting is generated on SQL queries, which is not the case with business logic and transactional logic. Many of the SQL languages turned out to be not very convenient in terms of programming complex transactional logic. It does not support object-oriented programming and has very clumsy logic constructs. Therefore, it is safe to say that programming has split into two components. Writing a variety of SQL query reports, getting data to a customer or application server, and implementing the rest of the logic in the application-oriented language of the application (no matter if it's a two-tier or three-tier architecture). In terms of load on the DBMS, it looks like a hefty SQL constructs for reading and then lots of small ones for changing.
Let us now consider the issue of load distribution of read-write queries on the DBMS server time wise. First, we need to define what load means and how it can be measured. The load will mean (in the order of priority of description): CPU (processor load), utilized RAM, and load on disk subsystem. CPU will be the main resource in terms of load. Let's consider an abstract OLTP system and divide all SQL calls from a set of parallel threads into two categories Read and Write. Next, based on the performance monitoring tools, plot an integral value such as CPU on a diagram. If the value is averaged for at least 30 seconds, we see that the value of the “Read” diagram is tens or even hundreds of times higher than the value of the “Write” diagram.
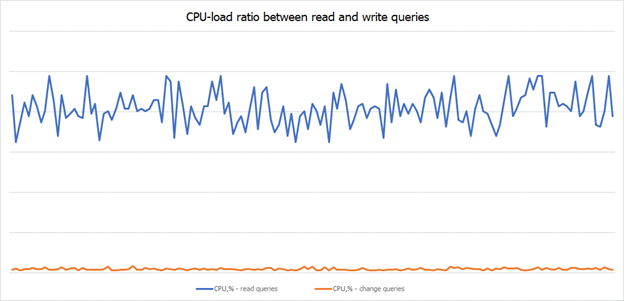
This is because more users per unit of time can execute reports or macro transactions that use hefty SQL constructs on reading. Sure, there may be tasks when the system regularly loads data from replication queues and external systems, period end routine procedures are started, and backup procedures are started. But based on long-term statistics for an overwhelming number of IT systems, the load of SQL constructs on Read exceeds the load on Write by ten folds. Certainly, there may be exceptions, for example, billing systems where the fact of changes is recorded without any complex logic and reporting, but it is easy to check this with a special-purpose software and understand how effective DCC will be for the IT system.
Strategic Area of Application
Currently, DCC will be useful and perhaps vital for major companies with extensive information flows and a strong analytical component. For example, major banks may profit. With the help of relatively small servers, it is possible to compose a DCC, which will be far ahead of all existing supercomputers in terms of power. Needless to say, it won't be all about the pros. The downside will be the increasingly complex part of administering a distributed system and a definitive transaction slowdown. Unfortunately, it is true that the network protocols and logic circuits that DCC utilizes cause transactions to slow down. Currently, the target parameter is a transaction slowdown of no more than 15% in terms of time. But once again I repeat that in this case the system will become much more scalable, all peak loads will be without problems, and on average the transaction time will be less than in the case of using a single server. Therefore, if the system faces no problems with peak loads and strategically it is not expected, DCC will not be effective.
In the future, DCC after the automation of administrative processes and optimization will probably also be effective for medium-sized companies because it will be possible to build a powerful cluster even using PCs with SSD (fast, unreliable, and cheap) disks. Its distributed structure will make it possible to easily disconnect a failed PC and connect a new one right on-the-fly. DCC's transaction control system will prevent data from being incorrectly recorded. Also, geopolitics cannot be ignored. For example, in case of lack of access to powerful servers, DCC will make it possible to build a powerful cluster using servers produced by domestic manufacturers.
Why Transactional Replication Cannot Be Used for DCC
This section requires a detailed description, and I will cover it in a separate article. Here I will point out only these problems:
Many application developers, when using a DBMS, do not even think about what data access conflicts the system resolves within the engine. For example, it is impossible to set up transactional replication, achieve data synchronization across multiple servers, and call it a DBMS cluster. This solution will not resolve the conflict of simultaneous access to a writer-writer type record. Such collisions will certainly lead to a violation of the logic of the system behavior. Existing transaction replication protocols are also costly and such a system will be very much inferior to the single server option.
In total, transactional replication is not suitable for ВСС because:
1. Excessive Costs of Typical Synchronous Transaction Replication Protocols
Typical distributed transaction protocols have too many additional, primarily time-related, network costs. For one network call, up to three additional calls are received. In such a form, the simplest atomic operations degrade dramatically.
2. The Writer-Writer Conflict Is Not Resolved
A conflict happens when the same data is changed simultaneously in different transactions. In terms of past change, the system only “remembers” the absolute last change (or history). The point of the SQL construct for sequential application gets lost. Such replication conflicts sometimes have no solutions at all.
In a separate article, I will give an example of different replication types for PostgreSQL and Microsoft SQL, and I will explain:
- Why they cannot solve the transactional load balancing problem architecturally
- Why it is not solved architecturally at the hardware level
The writer-writer problem is fundamentally unsolvable without a proxy service at the logical level of analyzing the application's SQL traffic.
Exchange Mechanisms (Protocols)
A full architectural description of DCC will be provided in a separate article. For now, let's confine ourselves to a brief summary to outline the issue at hand.
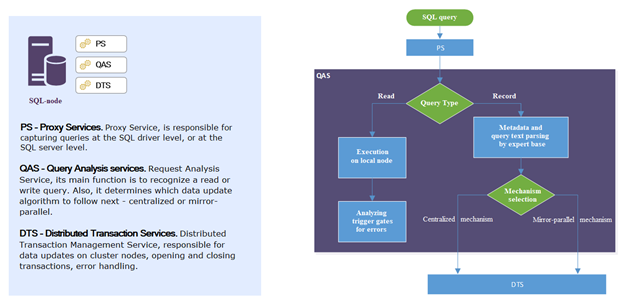
All queries to the DBMS in DCC go through a proxy service. For example, on 1C systems, it can be installed on the application server. The proxy service recognizes whether the query type is Read or Write. And if Read, it sends it to the server bound to the user (session). If the query type is Change, it sends it to all servers asynchronously. It does not proceed to the next query until it receives a positive response from all servers. If an error occurs, it is propagated to the client application and the transaction is rolled back on all servers. If all servers have confirmed successful execution of the SQL construct, only then does the proxy process the next client SQL query.
This is the kind of logic that does not result in logical contradictions. As can be seen, this arrangement incurs additional network and logical costs, although with proper optimization, they are minimal (we seek to achieve no more than 15% of the time delay of transactions).
The algorithm described above is the basic protocol, and it is what we will call mirror-parallel. Unfortunately, this protocol is not logically capable of implementing mirrored data replication for all IT systems.
In some cases, the data might for sure differ due to the specific nature of the system, another protocol is implemented for this purpose — “centralized asynchronous” — which will resolve synchronous information transfer for sure. The next section will cover it.
Why a Centralized Protocol Is Needed in DCC
Unfortunately, in some cases, sending the same structure to different servers gets assuredly different results. For example, when inserting a new record into a table, the primary key is generated based on the GUID on the server part. In this case, based on the definition alone, we will for sure get different results on different servers. As an option, it is possible to train the expert system of the proxy service to recognize that this field is formed on the server, form it explicitly on the proxy, and insert it into the query text.
What if it is impossible to do so for some reason? To resolve such problems, another protocol and server is introduced. Let's call it Conditionally Central. Next, it will be clear that it is not actually a central server.
The protocol algorithm is as follows. The proxy service recognizes that a SQL construct for a change is highly likely to produce different results on different servers. Therefore, it immediately redirects the query to the Conditionally Central server. Then after it is executed, using replication triggers, retrieve the changes that the query resulted in and send asynchronously all those changes to the remaining servers. And then proceed to execute the next command.
Similar to the mirror-parallel protocol, if at least one of the servers encounters an error, it is redirected to the client and the transaction is rolled back.
In this protocol, any collisions are completely prevented, data will always be guaranteed to be synchronous, and there will be almost no distributed deadlocks. But there is an essential downside: Due to its specific nature, the protocol imposes the highest runtime costs. Therefore, it will only be used in exceptional cases, otherwise no target delay parameters of no more than 15% will be even possible.
Mechanisms for Ensuring Integrity and Synchrony of Distributed Data at the Transaction Level in DCC
As we discussed in the previous section, there are logical (e.g., NEWGUID) SQL operations on change that, when executed simultaneously on different servers, will for sure take different values.
Let us rule out all sorts of random functions and fluctuations. Let's assume we have explicit arithmetic procedures, e.g.
UPDATE Summary Table
SET Total = Total+Delta
WHERE ProductID = Y.Certainly, such an arrangement in a single-thread option will lead to the same result and the data will be synchronous, because there are always laws of mathematics. But, if such constructs are executed in multithread mode by varying the Delta value, thread tangling may occur due to violation of the chronology of query execution. Which will lead to either deadlocks or data synchronization violations. In fact, it may turn out that the results of transactions on different servers may differ. Sure, it will be a rare occurrence, and it can be reduced by certain actions, but it cannot be completely ruled out, as well as it cannot be completely resolved without significant performance degradation. Such algorithms do not exist as a matter of fact, just as there is no such thing as fully synchronous time for multiple servers or network queries that are executed for sure for a certain amount of time.
Therefore, DCC has a distributed transaction management service and, in particular, a transaction hash-sum check is mandatory. Why hash-sum? Because it is possible to quickly check the content of these changes on all servers. If everything matches, the transaction is confirmed, and if not, it is rolled back with a corresponding error.
More details will follow in a separate article. In terms of mathematics, there are some interesting similarities with quantum mechanics, in particular with the transactional-loop theory (there is such a marginal theory).
The Issue of Distributed Deadlocks in DCC
This problem is that one of the key problems in DCC and in terms of risks of DCC implementation is the most dangerous. This is due to the fact that the occurrence of distributed deadlocks in DCC is a consequence of thread confusion due to the change in the chronology of SQL queries execution on different servers. This situation occurs due to uneven load on servers and network interfaces. In this case, unlike local deadlocks, which require at least two locking objects to occur, there can be only one object in a distributed deadlock.
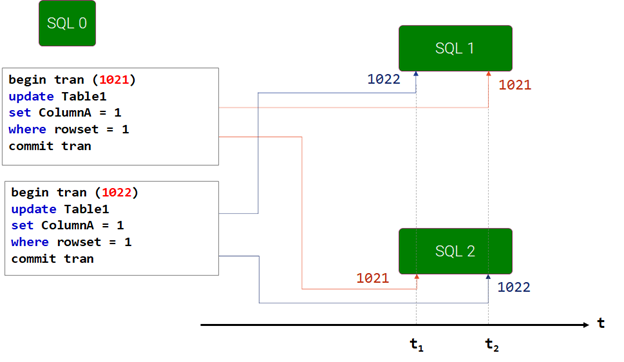
To reduce distributed deadlocks, several process challenges need to be addressed, one of them being the allocation of different physical network interfaces for writing and reading. After all, if we consider the ratio of CPU operations like Read to Write, there will be a ratio of one order, but for network traffic, the ratio will start from two orders of magnitude, more than hundreds of times. Therefore, by splitting these operations (Read-Write) on physically different channels of network communications, we can guarantee a certain time of delivery of Write-type SQL queries to all servers.
Also, the fewer locks there are in the system, the less likely distributed deadlocks are in data. However, using DCCs as an additional benefit, it is possible to expand such bottlenecks, if any, in the system at the level of settings.
If distributed deadlocks still occasionally occur, there is a special DCC service that monitors all blocking processes on all servers and resolves them by rolling back one of the transactions.
More details will follow in a separate article.
Special Features of DCC Administration
Administration of a distributed system is certainly more complicated than that of a local system, especially with the requirements of operation 24/7. And all potential DCC users are just the proud owners of IT systems with 24/7 operation mode.
Immediate problems include distributed database recovery and hot plugging of a new server to the DCC. Prompt data reconciliation in distributed databases is also necessary, despite transaction reconciliation mechanisms. Performance monitoring tasks and, in particular, the aggregation of counter data across related transactions and cluster servers in general begin to emerge. There are some security issues with setting up a proxy service. A full list of problems and proposed solutions will be in a separate article.
Parallel Computing Technologies as a Solution to Increase the Efficiency of DCC Use
For a scalable IT system, high parallelism of processes within the database is essential. For parallel reporting, as a rule, this issue does not occur. For transactional workloads, due to historical vestiges of suboptimal architecture, locks at the level of changing the same records (writer-writer conflict) are possible. If the IT system can be changed and there is open-source code, then the system can be optimized.
And if the system is closed, what shall we do in this case? In case of using DCC, there are opportunities at the level of administration to circumvent such restrictions. Or at least expand the possibilities. In particular, through customizations, we can enable changing the same record without waiting for the transaction to be committed — if a dirty read is possible, of course. At the same time, if the transaction is rolled back, the change data in the chronological sequence are also rolled back.
This situation is exactly appropriate, for example, for tables with aggregation of totals. I already have solutions for this problem, and I believe that regardless of using DCC, it is necessary to expand administrative settings of the DBMS, both Postgres and MSSQL (haven't investigated the issue on Oracle).
More details will follow in a separate article.
It is also necessary to disclose the topic of dirty reading in DCC and possible minor improvements taking this into account, such as the introduction of virtual locks.
Plan for the Following Publications on the Topic of DCC
Article 2. DCC load-testing results
Article 3. Why transactional replication can't be used for DCC
Article 4. Brief architectural description of the DCC
Article 5. The purpose of a centralized protocol in DCC
Article 6: Mechanisms for ensuring integrity and synchronization of distributed data at the transaction level in DCC
Article 7. The problem of distributed deadlocks in DCC
Article 8. Special features of DCC administration
Article 9: Parallel computing technologies as a tool to increase the efficiency of DCC utilization
Article 10. Example of DCC integration with 1C 8.x
Opinions expressed by DZone contributors are their own.
Comments