How to Create DSL With ANTLR4 and Scala
Want to learn more about how to create a basic grammar in Scala? Check out this post on how to create DSL with ANTLR4 and Scala.
Join the DZone community and get the full member experience.
Join For Freedomain-specific languages — when done correctly — help a lot with improving developer productivity. the first thing that you need to do while creating a dsl is to create a parser. this parser can take a piece of text and transform it into a structured format (like abstract syntax tree) so that your program can understand and do something useful with it. dsl tends to stay for years. while choosing a tool for creating the parser for your dsl, you need to make sure that it's easy to maintain and evolve the language. for parsing simple dsl, you can just use a regular expression or scala’s in-built parser-combinators. but, for even slightly complex dsl, both of these become a performance and maintenance nightmare.
in this post, we will see how to use antlr to create a basic grammar with antlr and use it in scala. full code and grammar for this post can be found here .
antlr4
antlr can generate lexers, parsers, tree parsers, and combined lexer-parsers. parsers can automatically generate abstract syntax trees that can be further processed with tree parsers. antlr provides a single consistent notation for specifying lexers, parsers, and tree parsers. this is in contrast with other parser/lexer generators and adds greatly to the tool’s ease of use. it supports:
- tree construction
- tree walking
- error recovery
- error handling
- translation
antlr supports a large number of target languages, so the same grammar can be used for both backend parsing or frontend validations. the following languages are supported:
ada, action script, c. c#, d, emacs, elisp, objective c, java, javascript,
python, ruby, perl6, perl, php, oberon, scala.
how antlr works
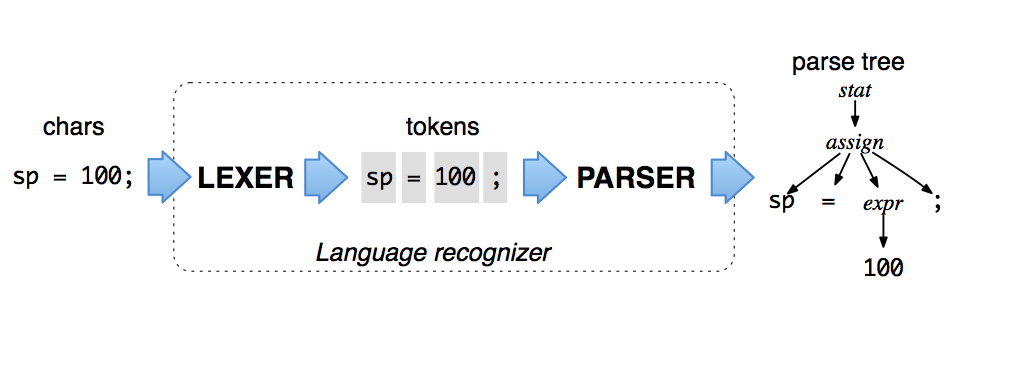
on a high level, here’s what you do to parse something with antlr:
- create lexer rules
- create parser rules that use a lexer output
- use lexer and parser to generate source code for a target language
- use generated sources to convert some raw input into the structured form (ast)
- do something with this structured data
we will begin to understand it with the help of an example. let's say we want to create a dsl for the following arithmetic operation. a valid input (expression) will be:
3 + (4 * 5)
as humans, if we want to evaluate this expression, here’s what we will do:
-
split this expression into different components:
-
in the above example, each character belongs to one of these group
- operands (3, 4, 5)
- operation (+ - * /)
- whitespaces
- this part is called the lexical analysis, where you convert raw text (stream of characters) into tokens.
-
in the above example, each character belongs to one of these group
-
create a relationship between tokens
-
to evaluate it efficiently, we can create a tree-like structure to define the relationship between a different expression like this:
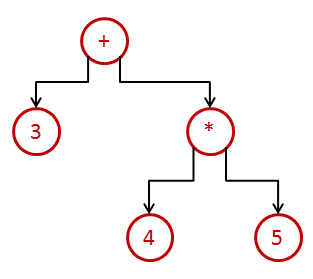
- this is called the ast (abstract syntax tree). this occurs by applying rules that you define in your grammar on the input text. once you have the ast, to evaluate the expression, we need to traverse or ‘walk’ it in a depth-first manner. we start at the root ‘+’ and go as deep into the tree as we can along each child. then, we evaluate the operations as we come back out of the tree.
-
to evaluate it efficiently, we can create a tree-like structure to define the relationship between a different expression like this:
we will now set up the tools and try creating a simple grammar.
setup
ide
antlr provides a gui-based ide for developing grammar. you can download it here . it combines an excellent grammar-aware editor with an interpreter for rapid prototyping and a language-agnostic debugger for isolating grammar errors.
intellij plugin
intellij provides a plugin for antlr. refer to this link for how to add the plugin .
command line setup
you can directly create, test, and debug grammar from the command line, too. here are the steps:
- download the antlr jar
-
create an alias for the command to generate sources:
-
alias antlr4='java -jar /home/sam/softwares/antlr/antlr-4.6-complete.jar'
-
-
create an alias to test your grammar for some input:
-
alias grun='java -cp ".:/home/sam/softwares/antlr/antlr-4.6-complete.jar" org.antlr.v4.gui.testrig'
-
add this in
~/.bashrc
to be able to directly call
antlr4
and
grun
command from anywhere.
creating grammar
a grammar will consist of two parts:
- lexer
- parser
both of these can be defined in the same file, but for maintenance sake, it's better to define it in separate files. let's create a lexer and parser for a dsl, which will allow basic arithmetic operations on two numbers. some valid inputs will be:
127.1 + 2717
2674 - 4735
47 * 74.1
271 / 281
10 + 2
10+2
lexer
definitions in a file named
arithmeticlexer.g4
to extract tokens from the input:
lexer grammar arithmeticlexer;
ws: [ \t\n]+ -> skip ;
number: ('0' .. '9') + ('.' ('0' .. '9') +)?;
add: '+';
sub: '-';
mul: '*';
div: '/';
-
the definition for
wsis telling to skip all the space, tabs and newline chars -
secondly, the definition for
numberis telling to extract all numbers as number token -
add/sub/mul/divdefinition is assigning a named token to respective mathematical operator
now, let's write some
parser
rules in the file are named
arithmeticparser.g4,
which will process tokens that are generated by the lexer and create an ast for a valid input.
parser grammar arithmeticparser;
options { tokenvocab=arithmeticlexer; }
expr: number operation number;
operation: (add | sub | mul | div);
-
expris the base rule and will accept any 2 numbers with one of valid operation. -
operationrule is telling tokens are valid operations
generating sources for a target language
now that we have our grammar, we can generate the lexer and parser source in any of the supported languages. run the following from the command line:
antlr4 arithmeticparser.g4
antlr4 arithmeticlexer.g4
by default, it will generate the sources in java. you can change that by passing the language argument. for example, the following command generates sources in javascript:
antlr4 -dlanguage=javascript arithmeticparser.g4
instead of generating sources individually for lexer and parser, you can do in the same command too:
antlr4 *.g4
after you run the code above, you will see the following java source generated in the same directory:
├── arithmeticlexer.g4
├── arithmeticlexer.java
├── arithmeticlexer.tokens
├── arithmeticparserbaselistener.java
├── arithmeticparser.g4
├── arithmeticparser.java
├── arithmeticparserlistener.java
└── arithmeticparser.tokens
you can also provide a package name for generated sources, which can be seen below:
antlr4 -package arithmetic *.g4
antlr provides two ways to walk the ast -
listener
and
vistor
. antlr doesn’t generate sources for the visitor by default. since we will be using visitor pattern while using it in scala to avoid mutability, let's generate a visitor source too. it can be done by providing the visitor flag, like below:
antlr4 -visitor *.g4
now, you will see the source for the visitor too:
├── arithmeticlexer.g4
├── arithmeticlexer.java
├── arithmeticlexer.tokens
├── arithmeticparserbaselistener.java
├── arithmeticparserbasevisitor.java
├── arithmeticparser.g4
├── arithmeticparser.java
├── arithmeticparserlistener.java
├── arithmeticparser.tokens
└── arithmeticparservisitor.java
next, compile the sources:
javac -cp ".:/home/sam/softwares/antlr/antlr-4.6-complete.jar" *.java
now, you are ready to test any input against your dsl.
testing the dsl
to do that, run the following command:
grun arithmetic expr -tokens
the above command is saying to execute
org.antlr.v4.gui.testrig
on the
arithmetic
grammar and test for a rule named
expr
. then, the
-tokens
flag will allow us to see the tokens generated by the lexer.
next, enter any valid input, like
10 + 3
. then, press
enter
. afterwards, you can press
ctrl+d
. you will see an input like the following:
$ grun arithmetic expr -tokens
10 + 2
^d
[@0,0:1='10',<number>,1:0]
[@1,3:3='+',<'+'>,1:3]
[@2,5:5='2',<number>,1:5]
[@3,7:6='<eof>',<eof>,2:0]
since it didn’t show any error, it means that your input is invalid. each line is showing a token value, token name, and its start and end offset.
in case of an invalid input, antlr will tell you what was it was expecting. this can be seen below:
$ grun arithmetic expr -tokens
10-
line 2:0 missing number at '<eof>'
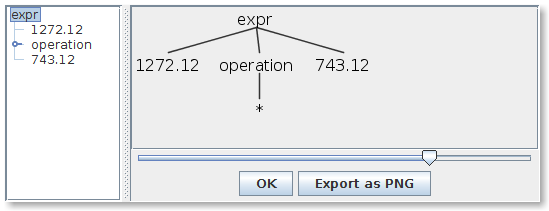
in case of a valid input, in addition to tokens, you can also see the ast by passing the
-gui
flag, as shown below:
$ grun arithmetic expr -tokens -gui
1272.12 * 743.12
^d
[@0,0:6='1272.12',<number>,1:0]
[@1,8:8='*',<'*'>,1:8]
[@2,10:15='743.12',<number>,1:10]
[@3,17:16='<eof>',<eof>,2:0]
using generated sources in code
we will now see how to extend generated interfaces and use it from within the code. as i mentioned above, antlr provides two ways to walk the ast - visitor and listener. we will first see how to use the listener pattern. although the listener method is commonly used by java devs, scala folks will not like it, because it can only return one unit. hence, you will need to use intermediate variables, leading to side-effects. refer to this post for a comparison between the two patterns. you can check out the complete code here .
the first thing that you need to do is add an antlr dependency:
librarydependencies ++= seq(
"org.antlr" % "antlr4-runtime" % "4.6",
"org.antlr" % "stringtemplate" % "3.2"
)
next, you need to import all the generated source in your project and create a parse method that will accept an input expression:
def parse(input:string) = {
println("\nevaluating expression " + input)
val charstream = new antlrinputstream(input)
val lexer = new arithmeticlexer(charstream)
val tokens = new commontokenstream(lexer)
val parser = new arithmeticparser(tokens)
/* implement listener and use parser */
}
- in line 4, we converted the input text to a char stream, because lexer operates at char level.
-
in line 5, we get a lexer object that uses
arithmeticlexer,generated using definitions from ‘arithmeticlexer.g4’ and pass input stream to it. - in line 6, we got all the token obtained by applying lexer rules to the input text.
-
in line 7, we created a parser by applying rules that we defined in
arithmeticparser.g4.
the next thing that we need to do is implement some methods in the
baselistener
interface. let's see the contents of the generated
arithmeticparserbaselistener
:
public class arithmeticparserbaselistener implements arithmeticparserlistener {
//enter and exit methods for grammar rules
@override public void enterexpr(arithmeticparser.exprcontext ctx) { }
@override public void exitexpr(arithmeticparser.exprcontext ctx) { }
@override public void enteroperation(arithmeticparser.operationcontext ctx) { }
@override public void exitoperation(arithmeticparser.operationcontext ctx) { }
//default grammar independent methods
@override public void entereveryrule(parserrulecontext ctx) { }
@override public void exiteveryrule(parserrulecontext ctx) { }
@override public void visitterminal(terminalnode node) { }
@override public void visiterrornode(errornode node) { }
}
for every rule that we defined in
arithmeticparser.g4
, it created a
enter
and
exit
method. since we had two rules,
expr
and
operation
, it created four methods. as the name implies, these will be triggered every time a walker enters and exits a matched rule. for now, let's focus on the entry method of our starting rule,
expr
. this problem can be solved by using the visitor instead of the listener, as discussed earlier in this post.
@override public void enterexpr(arithmeticparser.exprcontext ctx) { }
notice that every rule has a
context
that has all the meta information, as well as the matched input info. also, please note that all methods return
void,
which means that you need to use mutable variables to store computational values, if they need to be shared among different rules or even by the main caller.
now, we will create our own class by extending the
arithmeticparserbaselistener
and implementing the
enterexpr
rule.
class arithmeticlistenerapp extends arithmeticparserbaselistener {
override def enterexpr(ctx: arithmeticparser.exprcontext): unit = {
val exprtext = ctx.gettext
println(s"expression after tokenization = $exprtext")
val operands = ctx.number().tolist.map(_.gettext)
val operand1 = parsedouble(operands.lift(0).getorelse("0.0")).getorelse(0.0)
val operand2 = parsedouble(operands.lift(1).getorelse("0.0")).getorelse(0.0)
val operation = ctx.operation().gettext
calculate(operand1, operand2, operation) match {
case some(result) =>
println(s"result of $operand1 $operation $operand2 = $result")
case none =>
println(s"failed to evaluate expression. tokenized expr = $exprtext")
}
}
def parsedouble(s: string): option[double] = try(s.todouble).tooption
def calculate(op1:double, op2:double, operation:string):option[double] = {
operation match {
case "+" => some(op1 + op2)
case "-" => some(op1 - op2)
case "*" => some(op1 * op2)
case "/" => try(op1 / op2).tooption
case _ =>
println(s"unsupported operation")
none
}
}
}
- in line 4, exprtext will have tokenized text for this rule.
-
in line 7,
exprrule’scontextknows aboutnumberandoperation. sincenumberoccurs twice in the rule, thectx.number()will be a list containing two numbers. -
in line 11, we get a value of the
operationfrom the expr rule’scontext -
we calculate the value, and since there is no way to return it to the caller from the
enterexprmethod, we just print it. we could have stored it in some mutable variable, in case the caller needed it.
now that we have implemented this, we need to use it in the
parse
method that we defined earlier, as shown below:
def parse(input:string) = {
println("\nevaluating expression " + input)
val charstream = new antlrinputstream(input)
val lexer = new arithmeticlexer(charstream)
val tokens = new commontokenstream(lexer)
val parser = new arithmeticparser(tokens)
val arithmeticlistener = new arithmeticlistenerapp()
parser.expr.enterrule(arithmeticlistener)
}
now, let's test it on some input expressions:
val expressions = list(
"127.1 + 2717",
"2674 - 4735",
"47 * 74.1",
"271 / 281",
"12 ^ 3" // unsupported expression
)
expressions.foreach(parse)
you will see following output:
evaluating expression 127.1 + 2717
expression after tokenization = 127.1+2717
result of 127.1 + 2717.0 = 2844.1
evaluating expression 2674 - 4735
expression after tokenization = 2674-4735
result of 2674.0 - 4735.0 = -2061.0
evaluating expression 47 * 74.1
expression after tokenization = 47*74.1
result of 47.0 * 74.1 = 3482.7
evaluating expression 271 / 281
expression after tokenization = 271/281
result of 271.0 / 281.0 = 0.9644128113879004
evaluating expression 12 ^ 3
line 1:3 token recognition error at: '^'
line 1:5 missing {'+', '-', '*', '/'} at '3'
expression after tokenization = 123
unsupported operation
failed to evaluate expression. tokenized expr = 123
i hope this post gave you an idea on how to get started creating your own dsl. check out part two of this post to learn more about listener and visitors in antlr.
Opinions expressed by DZone contributors are their own.
Comments