Cyclop: A Web Based Editor for Cassandra Query Language
Cyclop is a web-based tool for querying Cassandra databases with features like syntax highlighting and query completion.
Join the DZone community and get the full member experience.
Join For FreeCassandra is one of the most popular open source NoSQL databases, but it’s only a few years old, and therefore tools support is still limited, especially when it comes to free open source software.
If you are working with Cassandra, sooner or later you will have to analyse its content on a remote cluster. Most of the available tools are desktop applications that connect to Cassandra over its protocol. Getting such access might be a hard task, because usually databases are installed in restricted networks in order to minimize data breach risk. Security policies are changing frequently to cover new findings, and the fact that you have access to your database today does not necessarily mean that it will last long.
Gaining access over SSH and the command line interface should be easier, but I do not have to convince anyone that using a terminal to query database content is painful, especially when it holds wide rows!
But there is one solution that is almost always available: web based applications! Every company knows how to secure them, how to run penetration tests, locate security leaks, and so on…. Actually it does not matter what happens behind the scenes. You, the end user, always has access to such an application – at least in theory.
Here comes the good news: Cyclop is 100% web based, and it’s based on the latest Wicket release! Once you’ve managed to install it, you can query your database from a web browser and still enjoy native application feeling (it’s almost fully based on AJAX, so page reloads are rare).
There is also another cool thing: if your security experts will run penetration tests against Cyclop they will come up with findings like Database Script Injection. This will be the first time in your life when you can honestly say: “It’s not a bug, it’s a future!”. Anyway – I would suggest to restrict access to Cyclop to some trusted networks. It’s definitely not a usual web application, but once you have managed to deploy it, you can enjoy simple access to your data over CQL.
User Management
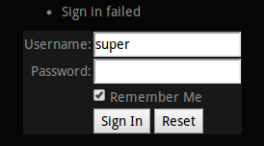
Cyclop does not manage users – it passes authorization and authentication to Cassandra. Once a Cassandra session has been opened, it’s being stored in an HTTP session, and that’s it. From now on, each query will be passed to Cassandra over its active session, and the result is successful or not – based on access rights defined in Cassandra for this particular user.
Providing support for persistent data like query history gets a bit tricky if there is no such thing as user. We could reference the credentials used to open the Cassandra session, but it’s a common use case that many users share them – like “read only user for IT on third floor”.
As you might have noticed, the UUID is a solution to all our problems, and this time it worked too! Cyclop generates a random cookie based on UUID and stores it in the browser. This is the replacement solution for missing user management. We do not recognize the user itself, but the browser. Of course a valid Cassandra session is always required, so it’s not possible that an unauthorized user could access restricted data (like query history) only because he has access to the browser, or “knows” the cookie value, he would have to log in in the first place.
User preferences cover things like the amount of rows in the result table, import settings or button state. Those are stored in the browser as a cookie in JSON format. Firstly, there is no security issue, because it’s not sensitive data, secondly we can access it directly from JavaScript.
Query Editor
Query Completion
- Completion is supported for almost the whole CQL 3 syntax
- Completion Hint shows all possible keywords that are valid for the actual query position. Tables, keyspaces and columns are grouped together and sorted. Groups are also highlighted with a different font color

- If the keyspace has been set in the previous query (“use cqldemo” in the screen shot below), the completion for the following queries will be narrowed to tables from this keyspace, assuming that the keyspace is not explicitly provided in the query

- Completion contains only tables that belong to the keyspace provided in the current query

- Completion contains only columns of a table that has been provided in current query

- Query syntax help has been copied from the Cassandra documentation. It is decorated with color highlighting matching the Completion Hint colors

Keyboard Navigation
- Enter – confirms currently highlighted completion
- Tab – next completion value
- Ctrl+Enter – executes query
- ESC – cancel completion
Query Results Table

- The results table is column-oriented, it’s reversed when compared to traditional SQL editors – rows are displayed horizontally, and columns vertically. When scrolling the page from left to right you will switch between rows. Scrolling from top to bottom shows the follow-up columns
- Columns are displayed in the order returned by the query, but in addition they are grouped into two sections divided by a blue separator line. The top of the table contains “static columns” – their values are not empty in multiple rows returned by the executed query. The second section contains columns, whose value is non-empty only for a single row. Cassandra supports dynamic columns, and the idea is to have “static” columns at the top of the table, and “dynamic” ones at the bottom, because those are mostly empty
- The table header for each row displays the partition key value, assuming the query returns it
- Long text is trimmed in order to fit into table cells. Such cells have a blue icon in the left top corner. Clicking on it opens a pop-up containing the whole text
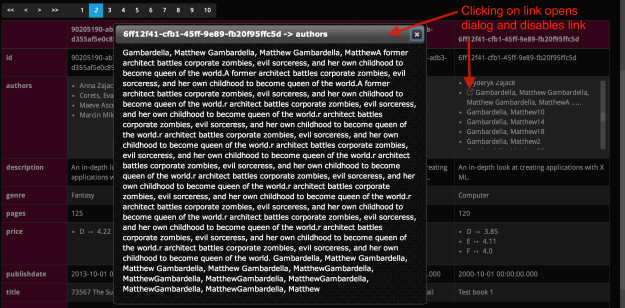
Query History
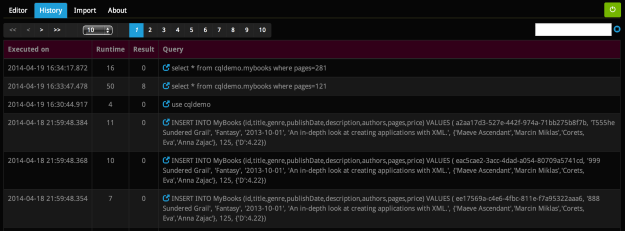
- The history contains the last 500 queries that have been successfully executed from this particular browser (we recognize users based on persistent cookies)
- Each entry in the history contains the query itself, the runtime and response size
- Next to the query there is a blue icon. Clicking on it will trigger a redirect to the editor and paste the query into it, so you can execute it again
History Filtering
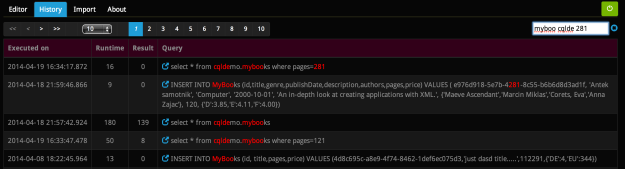
- The filter supports live update – you get results while typing. Just remember that words shorter than three characters will be ignored
- Multiple keywords are joined by OR. This means that the filter result will contain queries with at least one keyword
- Pressing Enter resets the filter (you can also click on the “clean” icon)
- You can specify multiple keywords in the filter. Is such case the top of the filtered history will contain queries with most hits. This builds groups, like queries with four hits, then three, and in the end those with a single hit. The queries within those groups are sorted by execution time
Data on the server
The history itself is stored on server in the file: [fileStore.folder]\QueryHistory-[User-UUID].json. The file itself contains the serialized history in JSON form. The solution is also secure, so you can use Cyclop from any computer without restrictions. A random cookie is the only information stored in the browser – but this does not matter, because the history can be viewed only by authenticated users.
Export
Query results can be exported to a CSV file. You can influence its format trough a configuration file
Import
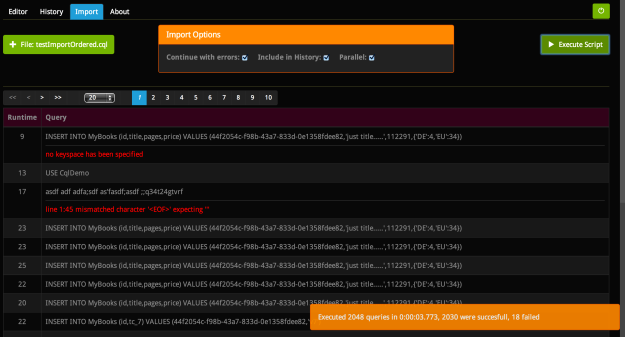
It’s meant to import files containing CQL queries separated by ;\n. A single query can span multiple lines. Results of the import are displayed in a table which contains each single query, the runtime and eventually an error – in this case the row is highlighted in red. You can also specify a few options, so that script execution will break (or not) after the first error, or executed queries can be included in the query history, or parallel import. The last option will divide the import file into chunks (6 by default) and execute each one in a separated thread. Be aware that queries will be executed in unspecified order.
Installation
- Download the last release: https://github.com/maciejmiklas/cyclop/releases/latest
- Edit the property file:
cyclop/src/main/resources/cyclop.propertiesand set connection settings for CassandraProperties filescassandra.hosts: localhost cassandra.port: 9042 cassandra.useSsl: false cassandra.timeoutMilis: 3600000 -
You can also overwrite each property from
cyclop.propertiesby setting it as jvm parameter. For example to connect to a different Cassandra host set:-Dcassandra.hosts=server1,server2. This gives you a simple possibility to change properties after the war file has been assembled. - Optionally change logger settings by editing
logback.xml. By default it logs to/var/lib/tomcat7/logs/cyclop-${time}.log - Build war file:
mvn package - Drop war file into tomcat
The created war can connect only to one Cassandra cluster. In order to serve multiple clusters from one Tomcat you have to deploy a few cyclop war archives, each one with a different cassandra.hosts value
Technical Details
The project can be found on github: https://github.com/maciejmiklas/cyclop
It’s based on the following technologies:
- web app – v3.x
- Maven – v3.x
- Spring – v3.x
- Wicket – v6.x
- wicket-auth-roles – v6.x
- bootstrap – v3.x (theme: cyborg from bootswatch)
- jQuery UI – v1.10.x
- cassandra-driver-core – v1.x
- slf4j/logback – v1.7.x
- hibernate validator – v4.x
- guava – v15.x (Cassandra 2.0 does not work with v16)
Live Demo
There is a demo deployment of Cyclop, so that you can get a first impression. I’m hosting it at home, so it can be down sometimes because I have no static IP, and when it changes propagation takes some time.
Different links below contain different queries. Clicking on a link will open Cyclop and paste into its editor the query from the link. Try to edit those queries using Cyclop’s editor to see how the code completion is working. The provided user has read-only access, so only part of the functionality is available.
- User: democasusr, Password: Cassandra123 written backwards (32…aC)
- http://maciejmiklas.no-ip.biz/cyclop
- http://maciejmiklas.no-ip.biz/cyclop/main/ced?cql=select%20*%20from%20cqldemo.mybooks
- http://maciejmiklas.no-ip.biz/cyclop/main/ced?cql=select%20id%2Cauthors%2Cgenre%20from%20cqldemo.mybooks%20where%20pages%20%3D%20121
- http://maciejmiklas.no-ip.biz/cyclop/main/ced?cql=select%20id%2Cauthors%20from%20cqldemo.mybooks%20where%20id%3D6ff12f41-cfb1-45ff-9e89-fb20f95ffc5d
- http://maciejmiklas.no-ip.biz/cyclop/main/ced?cql=select%20*%20from%20system.schema_columnfamilies
Published at DZone with permission of Comsysto Gmbh. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments