Data Engineering for AI-Native Architectures: Designing Scalable, Cost-Optimized Data Pipelines to Power GenAI, Agentic AI, and Real-Time Insights
AI-native data platforms demand more than upgrades — learn how teams are building scalable systems for RAG, streaming, embeddings, and orchestration.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2025 Trend Report, Data Engineering: Scaling Intelligence With the Modern Data Stack.
The data engineering landscape has undergone a fundamental transformation with a complete reimagining of how data flows through organizations. Traditional business intelligence (BI) pipelines were built for looking backward, answering questions like "How did we perform last quarter?" Today's AI-native architectures demand systems that can feed real-time insights to recommendation engines, provide context to large language models, and maintain the massive vector stores that power retrieval-augmented generation (RAG).
For data engineers, this evolution has created both opportunity and complexity. The core principles of data quality, observability, and scalable architecture remain as important as ever, but the technical requirements have expanded dramatically. What makes this particularly challenging is that most organizations can't simply rip out their existing data infrastructure and start fresh. A successful approach involves building AI-native capabilities on top of traditional analytics systems. Organizations that successfully build scalable, cost-optimized data platforms capable of supporting both traditional analytics and cutting-edge AI applications will find themselves with a significant competitive advantage. Those that don't risk being left behind as AI capabilities become table stakes across every industry vertical.
This article explores how data engineering teams can navigate this transformation, from redesigning core architecture patterns to implementing the new toolsets and practices required for AI-native data platforms.
The Transformation of Data Architecture for AI
Traditional data architectures were built around the assumption that data would be cleaned, structured, and processed in predictable batches. Your nightly ETL job could take six hours because the BI dashboard only refreshes once a day. AI systems, particularly modern generative and agentic AI applications, operate under completely different assumptions. If you're trying to feed a transformer model with terabytes of training data or build a RAG system that needs to retrieve semantically similar documents in under 100ms, your traditional ETL pipeline and star schema aren't going to cut it. The companies getting AI right aren't just bolting machine learning onto their existing data warehouse. Rather, they're building AI-native architectures from the ground up.
|
Aspect |
Traditional Data Architecture |
AI-Native Data Architecture |
|---|---|---|
|
Data types |
Structured data only (CSV, JSON, SQL tables) |
Multimodal data (text, images, audio, video, sensor data) |
|
Processing model |
Batch processing (ETL pipelines) |
Real-time streaming + batch hybrid |
|
Latency requirements |
Hours to days acceptable |
Milliseconds to seconds required |
|
Processing schedule |
Scheduled jobs (nightly, weekly) |
Event driven, continuous processing |
|
Data storage |
Data warehouses with star schema |
Data lakes + vector databases + feature stores |
|
Storage format |
Relational tables, normalized data |
Object storage (Parquet, Delta Lake, Iceberg) |
|
Query patterns |
SQL-based analytics queries |
Vector similarity search + traditional queries |
|
Infrastructure |
Cloud native, serverless, GPU-accelerated |
Cloud native, serverless, GPU accelerated |
|
Consumption |
BI dashboards, reports |
AI applications, recommendation engines, chatbots |
Table 1. Traditional vs. AI-native data architectures
From Batch to Streaming: Real-Time Data for AI Systems
Modern AI applications, especially those involving recommendation systems, fraud detection, and conversational AI, require continuous learning from fresh data streams. When a user interacts with a ChatGPT-style application, the system needs to understand context, not just from the current conversation but also from real-time signals about user behavior, system performance, and external data sources. This creates a fundamentally different set of requirements than traditional analytics workloads.
Streaming platforms like Apache Kafka and Apache Pulsar provide distributed event streaming capabilities for real-time data processing:
- Kafka uses a log-based architecture with topics partitioned across brokers, supporting configurable consistency levels from at-least-once to exactly-once delivery semantics.
- Pulsar implements a multi-layered design, separating serving from storage through Apache BookKeeper.
- BookKeeper enables infinite retention without performance degradation and native schema registry support for enforcing data contracts across different services and versions.
These are key parts of streaming architectures for generative AI that implement AI-specific patterns. Real-time streams capture user interactions, model outputs, and feedback signals, feeding them immediately to online learning systems and safety monitoring. Meanwhile, batch processes handle compute-intensive operations like embedding generation for RAG systems and large-scale model fine-tuning on accumulated conversation data.
Managing Unstructured Data Workflows
Unstructured data ranging from text and images to audio and video is a first-class citizen in the world of data engineering. Unlike structured data, which fits neatly into rows and columns, unstructured data is inherently messy and diverse. Yet it is precisely this richness that makes it indispensable for training large language models, building multimodal AI systems, and powering next-gen user experiences. Organizations are increasingly investing in data pipelines that can ingest, store, transform, and serve unstructured data reliably.
Modern orchestration tools like Apache Airflow, Dagster, and Prefect are evolving to support these needs, often in combination with cloud-native object storage solutions such as Azure Blob Storage. Processing unstructured data at scale typically involves distributed compute frameworks like Apache Spark or Dask, containerized workloads running on Kubernetes, or GPU-accelerated tasks for specialized transformations. Pipelines are increasingly modular, chaining together tasks such as format normalization, metadata extraction, vectorization, and enrichment. These stages must be resilient, parallelizable, and auditable, thereby capable of handling large volumes while preserving the fidelity and lineage of the original content.
Also bear in mind that the challenge isn't just processing unstructured data. It's also about maintaining quality and provenance throughout the pipeline. When the AI model starts producing biased or incorrect outputs, you need to be able to trace those problems back to specific data sources, processing steps, and transformation logic. This requires a level of observability and metadata management that goes far beyond traditional data engineering practices.
Building Scalable AI Data Infrastructure
The shift toward AI-native architectures demands infrastructure that can simultaneously serve a business analyst running quarterly reports and a research team fine-tuning a foundation model on terabytes of unstructured data. What's particularly challenging is that AI workloads are inherently unpredictable. A traditional ETL pipeline processes the same data volumes at scheduled intervals, but AI training runs can consume massive compute resources for days before completion, while inference workloads might spike suddenly when a new product feature launches. This variability requires infrastructure that can scale both horizontally and vertically without manual intervention, often leveraging cloud-native services that can provision resources on demand.
High-Volume Dataset Strategies for AI Training
Training foundation models and agentic AI systems requires infrastructure that can handle massive, heterogeneous datasets. Object storage systems are favored for their scalability and cost efficiency, supporting large-scale ingestion through batch or streaming pipelines. Columnar formats such as Apache Parquet, combined with partitioning, reduce I/O load and improve access speed for downstream processing.
Data lakes serve as the standard architecture for managing heterogeneous AI datasets, accommodating raw, unstructured data while maintaining essential metadata for governance. Apache Iceberg and Delta Lake provide atomicity, consistency, isolation, and durability (ACID) transactions and time-travel capabilities, enabling dataset versioning and rollback functionality when model performance degrades. Integration with distributed frameworks like Spark and Dask creates sophisticated ETL pipelines that transform raw data into training-ready formats while maintaining provenance tracking for enterprise compliance requirements.
Distributed computing frameworks form the computational backbone for large-scale AI operations, with Ray and Spark dominating based on workload characteristics. Ray excels in fine-grained parallelism and stateful computations for reinforcement learning and agentic systems, while Spark remains preferred for batch processing and supervised learning pipelines. GPU-aware schedulers and CUDA-enabled processing libraries accelerate throughput but require careful memory management and data locality optimization to minimize movement between storage and compute layers.
Vector Databases and Embedding Management
Vector embeddings are numerical representations of data (e.g., text, images, audio) that capture semantic meaning in high-dimensional space, enabling generative AI apps to understand context, perform similarity searches, and retrieve relevant information for tasks like RAG and semantic search. Vector databases like Pinecone, Weaviate, and Chroma solve a fundamental problem: how to efficiently store, index, and query high-dimensional embeddings that represent the semantic meaning of text, images, audio, or any other data types. These databases use specialized indexing algorithms like hierarchical navigable small world (HNSW) or inverted file (IVF) that enable approximate nearest neighbor searches across millions of vectors with low latency.
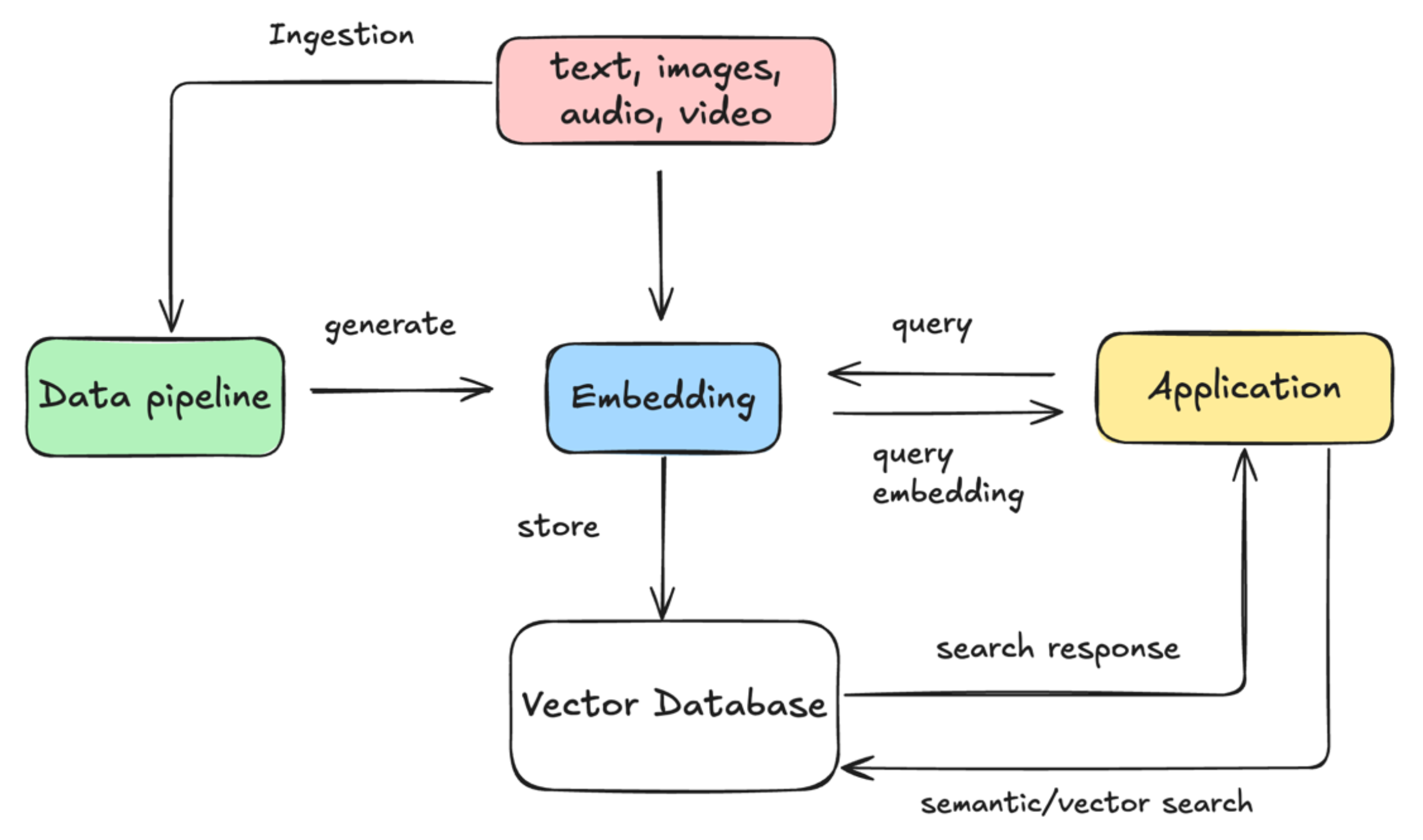
Managing embeddings across diverse models and use cases presents significant complexity. A single organization might use OpenAI's text-embedding-ada-002 for document search, custom-trained image models for visual similarity, and specialized models for code search, each producing vectors with different dimensionalities and semantic characteristics. This needs careful namespace management, version control, and compatibility planning.
During model upgrades or migrations, new or fine-tuned models generate embeddings in different semantic spaces, making existing vectors non-interchangeable. To address this, teams typically version their embedding collections and implement migration strategies such as dual-serving or fallback mechanisms, allowing multiple versions to coexist during phased transitions.
Operationally, embedding management extends beyond storage into the design of efficient generation pipelines. For large datasets, especially with multimodal inputs like images or video, embedding computation is resource intensive. Successful systems often combine batch generation for historical data with real-time streaming for new content, enabling both large-scale reprocessing during model changes and incremental updates as data evolves.
Implementation and Optimization Strategies
The gap between AI ambitions and production reality often comes down to implementation choices that seem minor but compound into major operational headaches. You can architect the most elegant AI-native data platform on paper, but if you can't deploy it reliably, scale it cost effectively, or maintain it without a team of specialists, you've built an expensive science project.
Smart organizations are learning that the key isn't choosing between open-source and commercial solutions. It's understanding where each fits in your specific context. The companies succeeding with AI at scale aren't necessarily the ones with the biggest budgets; they're the ones that have figured out how to balance flexibility, cost, and operational complexity in ways that actually work for their teams.
The most effective AI data platforms share a common trait: They're designed for evolution, not perfection. They anticipate that your AI workloads will change, your data volumes will grow unpredictably, and your team will need to adapt to technologies that don't exist yet. Building for this reality requires a fundamentally different approach to implementation and optimization than traditional data infrastructure.
DataOps for AI: Automation and Orchestration
When your data pipeline breaks at 2 AM because someone changed a schema upstream, you quickly realize that manual processes don't scale with AI workloads. DataOps for AI isn't just about applying DevOps principles to data; it's about recognizing that AI systems have fundamentally different reliability requirements than traditional analytics. Unlike traditional ETL jobs that follow predictable patterns, AI pipelines often involve retraining models based on data quality thresholds, triggering inference updates when embedding models change, or coordinating between multiple agentic systems that need to share state.
The most successful implementations treat AI pipeline orchestration as a first-class engineering discipline. This means version controlling not just your code but also your pipeline definitions, model artifacts, and even the configurations that determine when models get retrained. Companies like Netflix and Uber have shown that you can achieve remarkable reliability by building orchestration systems that understand the relationships between data, models, and business outcomes.
Testing becomes particularly crucial when your pipelines feed AI systems that make autonomous decisions. In addition to unit testing for individual transformations, you need:
- Integration tests that verify end-to-end behavior
- Schema evolution tests that catch breaking changes before they propagate
- Monitoring that can detect subtle data drift that might degrade model performance over time
Your team should be able to deploy changes confidently, understand why failures happen, and recover quickly when things go wrong. This requires building orchestration systems that provide clear visibility into dependencies, explicit control over rollback scenarios, and detailed logging that helps you debug complex interactions between multiple AI systems.
Cross-Functional Collaboration and Governance
The biggest technical challenge in AI data engineering often isn't the technology; it's the organizational complexity that emerges when data engineers, data scientists, ML engineers, and business stakeholders all need different things from the same underlying infrastructure:
- Data scientists want flexibility to experiment with new models and datasets.
- Business stakeholders want reliable and auditable systems that meet compliance requirements.
- Data engineers want maintainable architectures that don't require constant firefighting.
Effective governance starts with establishing clear ownership boundaries through technical mechanisms rather than relying solely on process documentation. This includes implementing automated data quality checks, feature stores that enforce consistent transformations, and metadata systems that track lineage from raw data through model training to business outcomes.
Model governance becomes particularly complex in agentic AI systems where multiple models interact autonomously, requiring frameworks for understanding how changes in one model might affect dependent systems and monitoring that can detect emergent behaviors. Privacy and compliance add another layer of complexity as GDPR right-to-deletion requests become nightmarish when you need to remove specific data points from trained models, embedding stores, and vector databases. The goal is creating collaboration patterns that scale with your AI initiatives by treating governance as an engineering problem that can be solved with the right combination of tooling, automation, and organizational design, enabling teams to move quickly without creating systemic risks.
Conclusion
We're witnessing the emergence of an architectural paradigm where the distinction between "analytics data" and "AI data" is dissolving. Systems like recommendation engines, fraud detection, and chatbots increasingly rely on shared data infrastructure but with vastly different performance and consistency requirements. The path forward is to design data platforms with AI as the primary consumer, retrofitting for traditional workloads rather than the other way around. This shift enables support for evolving needs like large context windows, vector-based retrieval, and complex agentic workflows.
The shift also introduces specific technical demands:
- Cost management must include storage format efficiency, cross-region data movement, and duplication across batch and real-time paths.
- Performance monitoring needs to capture embedding drift, vector index quality, and inference latency under load.
- Orchestration has to coordinate interdependent steps across ingestion, transformation, training, and serving.
These aren't speculative problems; they already surface in production environments that support retrieval-augmented generation, fine-tuned models, and agent-based systems. The organizations that get this right will move beyond efficiency gains to build data architectures that unlock durable AI capabilities.
Additional resources:
- Getting Started With Large Language Models by Tuhin Chattopadhyay, DZone Refcard
- Getting Started With Agentic AI by Lahiru Fernando, DZone Refcard
- Getting Started With Vector Databases by Miguel Garcia Lorenzo, DZone Refcard
- Getting Started With Data Quality by Miguel Garcia Lorenzo, DZone Refcard
- Apache Kafka Patterns and Anti-Patterns by Abhishek Gupta, DZone Refcard
This is an excerpt from DZone's 2025 Trend Report, Data Engineering: Scaling Intelligence With the Modern Data Stack.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments