Data Exploration and Data Preparation for Business Insights
Join the DZone community and get the full member experience.
Join For FreeWhat Is Data Exploration?
Data Exploration or Exploratory data analysis (EDA) provides a simple set of exploration tools that bring out the basic understanding of real-time data into data analytics. The outcomes of data exploration can be a powerful factor in understanding the structure of data, values distributions, and interrelationships. Data exploration can also be helpful for data scientists to gain proper insights into business data that was not easily seen previously.
Data exploration is the first step in data analytics. Understanding business data is essential for making a well-planned decision, which usually involves summarizing the main features of a data set, such as its size, pattern, characteristics, accuracy, and more.
The entire process is conducted by a team of data analysts using visual analysis tools and some advanced statistical software like R. Data exploration can use a combination of manual methods and automated tools, such as data visualization, charts, and preliminary reports.
What Is Data Preparation?
Data preparation is typically used for proper business data analysis. The data preparation process involves collecting, cleaning, and consolidating data into a file that can be further used for analysis.
Why Data Preparation Is Necessary?
- To filter unstructured, inconsistent, and disordered data.
- Connecting data from real-time multiple data sources.
- For quick reporting of data.
- To handle data collected from a scraped file like PDF document.
The Process of Data Preparation
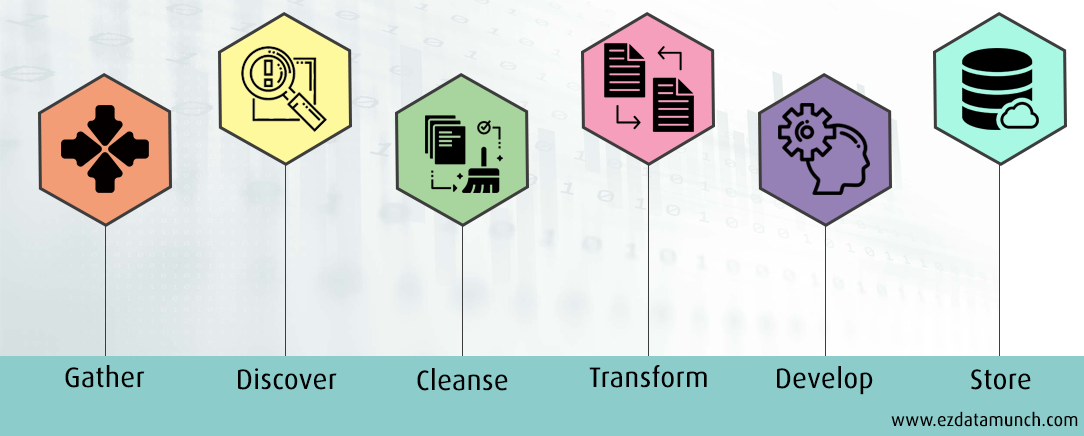
Here, we will discuss the standard data preparation procedure, which has been followed by every business.
Gather Data
This is an initial process for each business. In this phase, it is necessary to collect data from various sources — the sources can be of any type such as from catalogs or ad-hoc can be added.
Discover Data
The next step is discovering the data; here, it is very important to understand the data and categorize it into different datasets. This step might take a long time to filter because of the huge collection of datasets.
Cleaning and Validating Data
This is necessary to remove faulty and critical data that you think may not be useful in the next step. Important steps need to be taken here:
- Removing unnecessary data and outliers.
- Use the appropriate patterns for refining all the data.
- Use the lock to protect your sensitive data.
- Fill the empty space for data flow.
After cleaning the data, it should go through the test team where all the refine data has to be rechecked.
Transforming the Data
Transforming the data defines maintaining the format or value entries in order to meet well define output and can clearly understand the wider audience.
Storing Data
This is the final step after going through all the above processes. Once the data is cleaned, it is ready to offer third-party tools, such as business intelligence tools for analysis.
You may also like: How to do Data Exploration for Image Segmentation and Object Detection
Benefits of Data Preparation
Here are a few benefits of data preparation:
- Quick response in fixing the error before processing
- Producing data by cleaning and reformatting the datasets
- Higher quality data helps you to analyze data more effectively and quickly
Data Exploration Methods
There are two formats of data exploration: automatic and manual. Mostly, analysts preferred automated methods, such as data visualization tools because of their accuracy and quick response. Manual data exploration, on the other hand, methods include filtering and drilling down into data in Excel spreadsheets or writing scripts to analyze raw data sets.
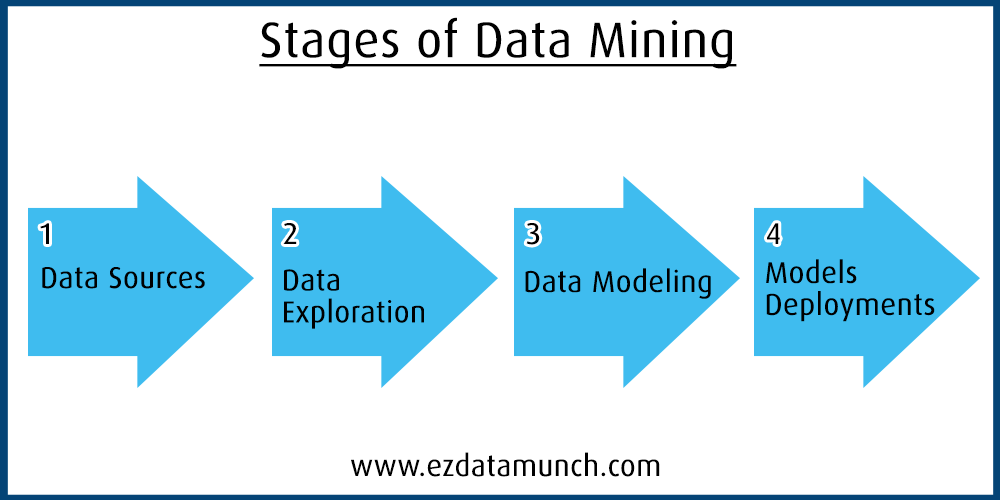
Data exploration plays an essential role in the data mining process. There are several techniques for analyzing data such as:
Univariate analysis: It is the simplest form of analyzing data. Univariate means that there is only one variable in your data.
Bivariate analysis: It is the simplest form of quantitative analysis. It includes the analysis of two variables (as x, y) used for calculating the empirical relationship between two variables.
Multivariate analysis: Multivariate Analysis can be used to refer to any analysis that involves more than one variable (e.g. in Multiple Regression or GLM ANOVA).
Principal components analysis: The analysis and conversion of possibly correlated variables into a smaller number of uncorrelated variables.
The next step after data exploration is data discovery. In this phase, business intelligence tools are used to inspect trends, sequences, and events and create visualizations to present to business managers.
Data Exploration Tools
Many business intelligence tools and data visualization software are available. Some commonly used data analysis tools are Microsoft Power BI, Qlik, and Tableau.
Many business intelligence tools and data visualization software are available. Some commonly used tools used by data analysts are Microsoft Power BI, Qlik, and Tableau.
Data Exploration and Preparation Steps
The quality of the output always depends on the quality of the input. So, make the input value so versatile so that the output remains constant.
Below are the steps to understand, clear, and prepare your data for building your predictive model:
- Variable Identification
- Univariate Analysis
- Bi-variate Analysis
- Missing Values Treatment
- Outlier Treatment
- Variable Transformation
- Variable Creation
Let’s start discussing each step in detail.
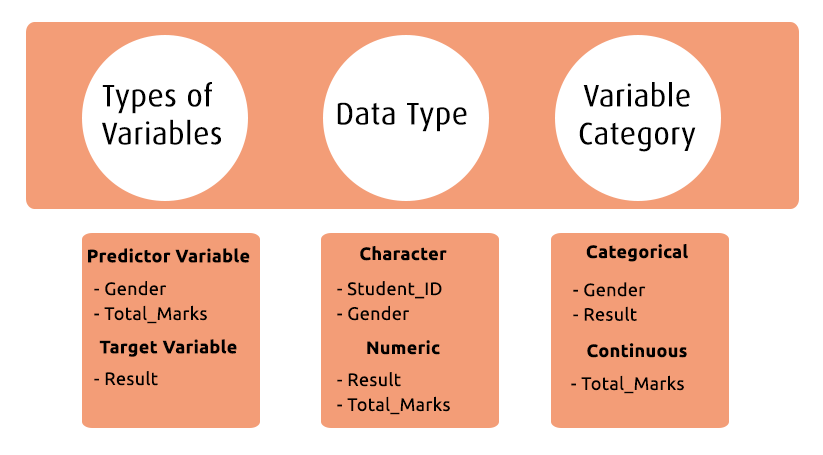
Variable Identification
In this step, you have to first identify the input and output variables. Then, identify the data type and category of the variables. Let's focus more by applying one real-time example
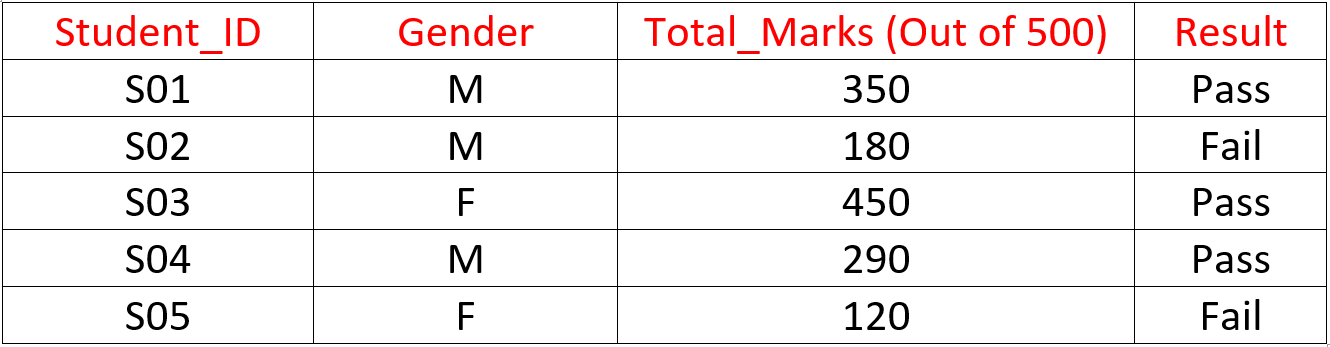
Suppose a school wants to predict the ratio (pass or fail) of student results. Here, you need to collect predictor variables, target variables, data types, and category of the variable.
Below, the variables have been defined in a different category:
Univariate Analysis
In univariate analysis, variables are explored one-by-one. This method depends on whether a variable type is categorical or continuous:
- Categorical Variables: This is also called a discrete variable that has two or more categories (values). It can be measured using two metrics, Count and Count% against each category. A bar chart can be used as a visualization.
- Continuous Variables: A continuous variable is a quantitative variable in which the data is measured in height, weight, or time. Continuous variables can take on almost any numeric value and can be meaningfully divided into smaller increments, including fractions.
Bi-variate Analysis
Bivariate analysis is the analysis of bivariate data. It used to find out if there is a relationship between two sets of values. It usually involves the variables X and Y.
Examples of Bi-Variate Analysis:
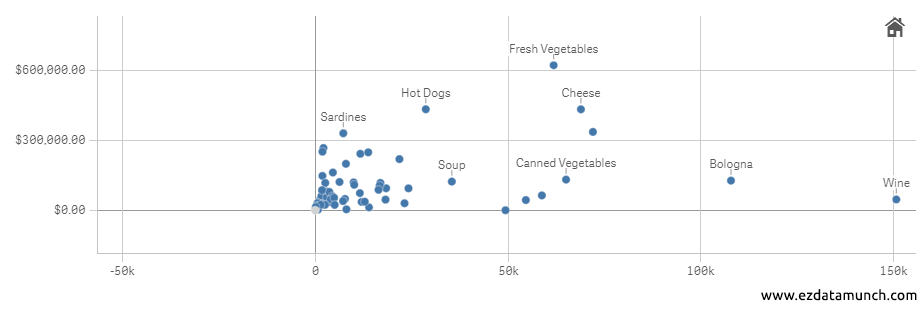
- Scatter Plots
- Regression Analysis
- Correlation Coefficients
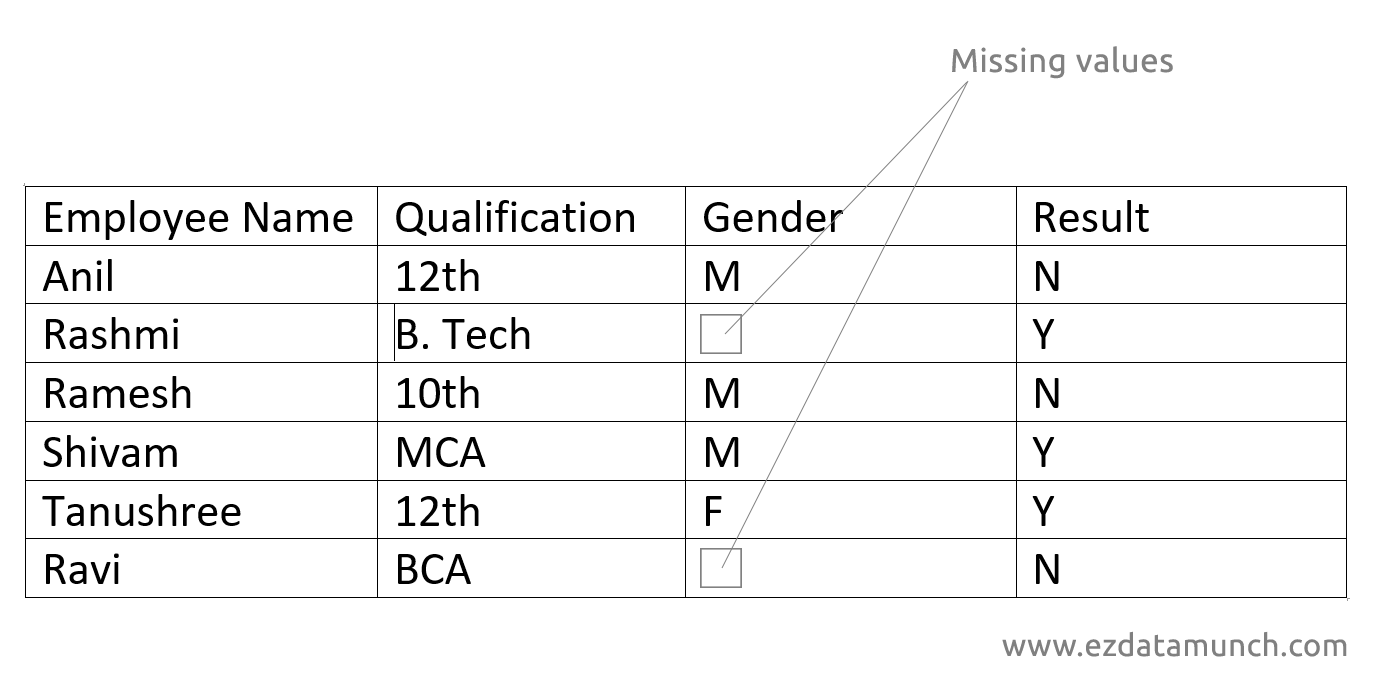
Missing Values Treatment
It is necessary to understand the concept of missing values because if it not handled properly, then inaccurate interference occurs. It can lead to incorrect prediction and classification.
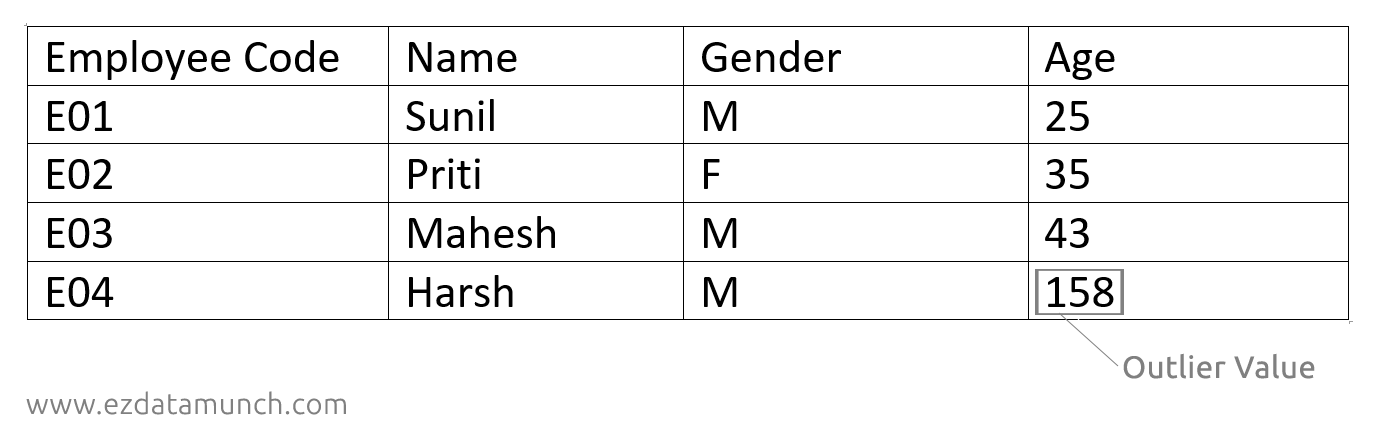
Outlier Treatment
The outlier is a data point that is distant from another different point. These outliers should remove from datasets. This can be identified directly by looking at the data table or worksheet.
Variable Transformation
Data does not always come in a form that is immediately suitable for analysis. We often have to change variables before analysis. A transformation is a recursion of data using a function or some mathematical operation on each observation.
Conclusion
It is clear from the above discussion that by using the right tools, an organization can easily detect and present data effectively. However, as with anything, having a plan and focus yields the best results.
You can use this detail information on data discovery and data preparation before you start analyzing data.
Further Reading
Opinions expressed by DZone contributors are their own.
Comments