Data Governance: Data Integration (Part 4)
It's important to have a strong data governance framework in place when integrating data from different source systems. Learn more!
Join the DZone community and get the full member experience.
Join For FreeWhat Is Data Governance?
Data governance is a framework that is developed through the collaboration of individuals with various roles and responsibilities. This framework aims to establish processes, policies, procedures, standards, and metrics that help organizations achieve their goals. These goals include providing reliable data for business operations, setting accountability, and authoritativeness, developing accurate analytics to assess performance, complying with regulatory requirements, safeguarding data, ensuring data privacy, and supporting the data management life cycle.
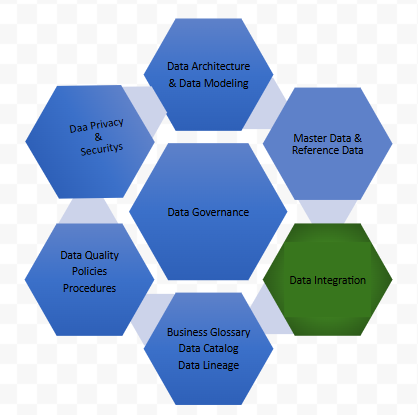
Creating a Data Governance Board or Steering Committee is a good first step when integrating a Data Governance program and framework. An organization’s governance framework should be circulated to all staff and management, so everyone understands the changes taking place.
The basic concepts needed to successfully govern data and analytics applications. They are:
- A focus on business values and the organization’s goals
- An agreement on who is responsible for data and who makes decisions
- A model emphasizing data curation and data lineage for Data Governance
- Decision-making that is transparent and includes ethical principles
- Core governance components include data security and risk management
- Provide ongoing training, with monitoring and feedback on its effectiveness
- Transforming the workplace into collaborative culture, using Data Governance to encourage broad participation
What Is Data Integration?
Data integration is the process of combining and harmonizing data from multiple sources into a unified, coherent format that various users can consume, for example: operational, analytical, and decision-making purposes.
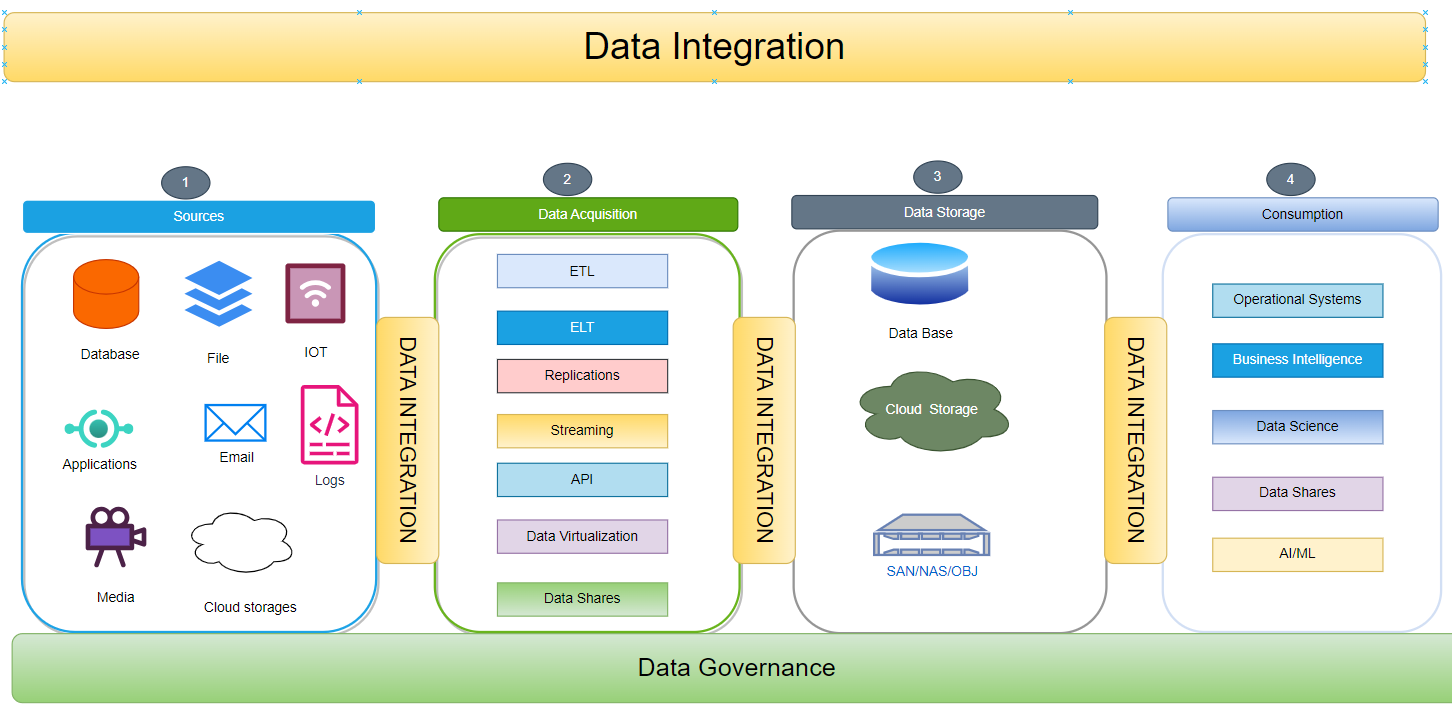
The data integration process consists of four primary critical components:
1. Source Systems
Source systems, such as databases, file systems, Internet of Things (IoT) devices, media continents, and cloud data storage, provide the raw information that must be integrated. The heterogeneity of these source systems results in data that can be structured, semi-structured, or unstructured.
- Databases: Centralized or distributed repositories are designed to store, organize, and manage structured data. Examples include relational database management systems (RDBMS) like MySQL, PostgreSQL, and Oracle. Data is typically stored in tables with predefined schemas, ensuring consistency and ease of querying.
- File systems: Hierarchical structures that organize and store files and directories on disk drives or other storage media. Common file systems include NTFS (Windows), APFS (macOS), and EXT4 (Linux). Data can be of any type, including structured, semi-structured, or unstructured.
- Internet of Things (IoT) devices: Physical devices (sensors, actuators, etc.) that are embedded with electronics, software, and network connectivity. IoT devices collect, process, and transmit data, enabling real-time monitoring and control. Data generated by IoT devices can be structured (e.g., sensor readings), semi-structured (e.g., device configuration), or unstructured (e.g., video footage).
- Media repositories: Platforms or systems designed to manage and store various types of media files. Examples include content management systems (CMS) and digital asset management (DAM) systems. Data in media repositories can include images, videos, audio files, and documents.
- Cloud data storage: Services that provide on-demand storage and management of data online. Popular cloud data storage platforms include Amazon S3, Microsoft Azure Blob Storage, and Google Cloud Storage. Data in cloud storage can be accessed and processed from anywhere with an internet connection.
2. Data Acquisition
Data acquisition involves extracting and collecting information from source systems. Different methods can be employed based on the source system's nature and specific requirements. These methods include batch processes, streaming methods utilizing technologies like ETL (Extract, Transform, Load), ELT (Extract, Load, Transform), API (Application Programming Interface), streaming, virtualization, data replication, and data sharing.
- Batch processes: Batch processes are commonly used for structured data. In this method, data is accumulated over a period of time and processed in bulk. This approach is advantageous for large datasets and ensures data consistency and integrity.
- Application Programming Interface (API): APIs serve as a communication channel between applications and data sources. They allow for controlled and secure access to data. APIs are commonly used to integrate with third-party systems and enable data exchange.
- Streaming: Streaming involves continuous data ingestion and processing. It is commonly used for real-time data sources such as sensor networks, social media feeds, and financial markets. Streaming technologies enable immediate analysis and decision-making based on the latest data.
- Virtualization: Data virtualization provides a logical view of data without physically moving or copying it. It enables seamless access to data from multiple sources, irrespective of their location or format. Virtualization is often used for data integration and reducing data silos.
- Data replication: Data replication involves copying data from one system to another. It enhances data availability and redundancy. Replication can be synchronous, where data is copied in real-time, or asynchronous, where data is copied at regular intervals.
- Data sharing: Data sharing involves granting authorized users or systems access to data. It facilitates collaboration, enables insights from multiple perspectives, and supports informed decision-making. Data sharing can be implemented through various mechanisms such as data portals, data lakes, and federated databases.
3. Data Storage
Upon data acquisition, storing data in a repository is crucial for efficient access and management. Various data storage options are available, each tailored to specific needs. These options include:
- Database Management Systems (DBMS): Relational Database Management Systems (RDBMS) are software systems designed to organize, store, and retrieve data in a structured format. These systems offer advanced features such as data security, data integrity, and transaction management. Examples of popular RDBMS include MySQL, Oracle, and PostgreSQL. NoSQL databases, such as MongoDB and Cassandra, are designed to store and manage semi-structured data. They offer flexibility and scalability, making them suitable for handling large amounts of data that may need to fit better into a relational model.
- Cloud storage services: Cloud storage services offer scalable and cost-effective storage solutions in the cloud. They provide on-demand access to data from anywhere with an internet connection. Popular cloud storage services include Amazon S3, Microsoft Azure Storage, and Google Cloud Storage.
- Data lakes: Data lakes are large repositories of raw and unstructured data in their native format. They are often used for big data analytics and machine learning. Data lakes can be implemented using Hadoop Distributed File System (HDFS) or cloud-based storage services.
- Delta lakes: Delta lakes are a type of data lake that supports ACID transactions and schema evolution. They provide a reliable and scalable data storage solution for data engineering and analytics workloads.
- Cloud data warehouse: Cloud data warehouses are cloud-based data storage solutions designed for business intelligence and analytics. They provide fast query performance and scalability for large volumes of structured data. Examples include Amazon Redshift, Google BigQuery, and Snowflake.
- Big data files: Big data files are large collections of data stored in a single file. They are often used for data analysis and processing tasks. Common big data file formats include Parquet, Apache Avro, and Apache ORC.
- On-premises Storage Area Networks (SAN): SANs are dedicated high-speed networks designed for data storage. They offer fast data transfer speeds and provide centralized storage for multiple servers. SANs are typically used in enterprise environments with large storage requirements.
- Network Attached Storage (NAS): NAS devices are file-level storage systems that connect to a network and provide shared storage space for multiple clients. They are often used in small and medium-sized businesses and offer easy access to data from various devices.
Choosing the right data storage option depends on factors such as data size, data type, performance requirements, security needs, and cost considerations. Organizations may use a combination of these storage options to meet their specific data management needs.
4. Consumption
This is the final stage of the data integration lifecycle, where the integrated data is consumed by various applications, data analysts, business analysts, data scientists, AI/ML models, and business processes. The data can be consumed in various forms and through various channels, including:
- Operational systems: The integrated data can be consumed by operational systems using APIs (Application Programming Interfaces) to support day-to-day operations and decision-making. For example, a customer relationship management (CRM) system may consume data about customer interactions, purchases, and preferences to provide personalized experiences and targeted marketing campaigns.
- Analytics: The integrated data can be consumed by analytics applications and tools for data exploration, analysis, and reporting. Data analysts and business analysts use these tools to identify trends, patterns, and insights from the data, which can help inform business decisions and strategies.
- Data sharing: The integrated data can be shared with external stakeholders, such as partners, suppliers, and regulators, through data-sharing platforms and mechanisms. Data sharing enables organizations to collaborate and exchange information, which can lead to improved decision-making and innovation.
- Kafka: Kafka is a distributed streaming platform that can be used to consume and process real-time data. Integrated data can be streamed into Kafka, where it can be consumed by applications and services that require real-time data processing capabilities.
- AI/ML: The integrated data can be consumed by AI (Artificial Intelligence) and ML (Machine Learning) models for training and inference. AI/ML models use the data to learn patterns and make predictions, which can be used for tasks such as image recognition, natural language processing, and fraud detection.
The consumption of integrated data empowers businesses to make informed decisions, optimize operations, improve customer experiences, and drive innovation. By providing a unified and consistent view of data, organizations can unlock the full potential of their data assets and gain a competitive advantage.
What Are Data Integration Architecture Patterns?
In this section, we will delve into an array of integration patterns, each tailored to provide seamless integration solutions. These patterns act as structured frameworks, facilitating connections and data exchange between diverse systems. Broadly, they fall into three categories:
- Real-Time Data Integration
- Near Real-Time Data Integration
- Batch Data Integration
1. Real-Time Data Integration
In various industries, real-time data ingestion serves as a pivotal element. Let's explore some practical real-life illustrations of its applications:
- Social media feeds display the latest posts, trends, and activities.
- Smart homes use real-time data to automate tasks.
- Banks use real-time data to monitor transactions and investments.
- Transportation companies use real-time data to optimize delivery routes.
- Online retailers use real-time data to personalize shopping experiences.
Understanding real-time data ingestion mechanisms and architectures is vital for choosing the best approach for your organization.
Indeed, there's a wide range of Real-Time Data Integration Architectures to choose from. Among them most commonly used architectures are:
- Streaming-Based Architecture
- Event-Driven Integration Architecture
- Lambda Architecture
- Kappa Architecture
Each of these architectures offers its unique advantages and use cases, catering to specific requirements and operational needs.
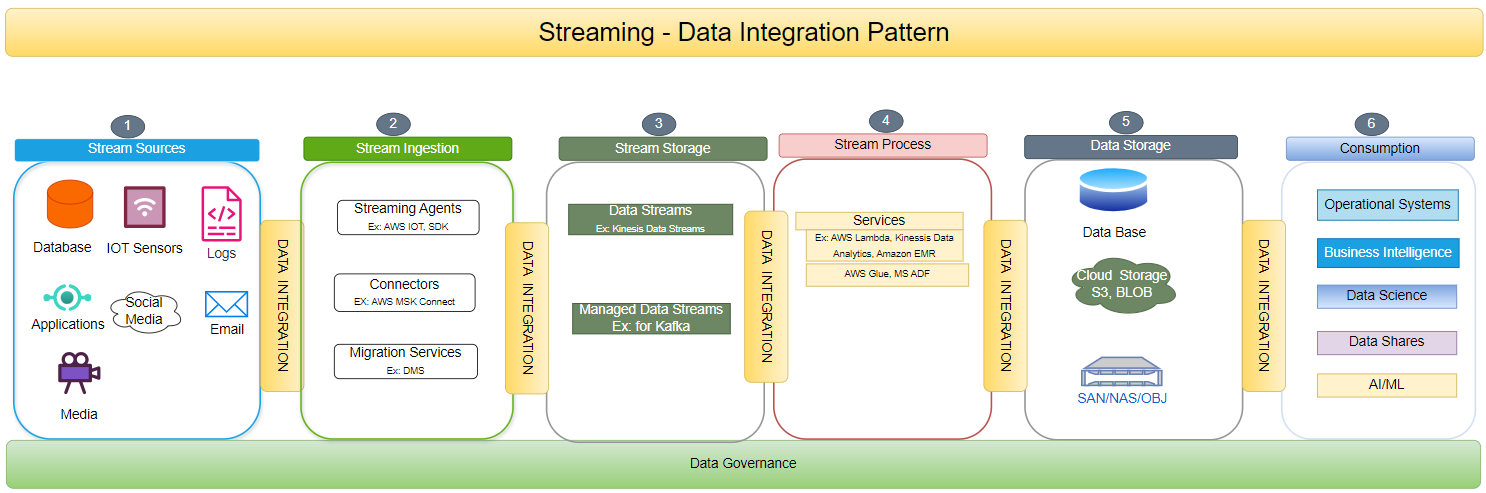
a. Streaming-Based Data Integration Architecture
In a streaming-based architecture, data streams are continuously ingested as they arrive. Tools like Apache Kafka are employed for real-time data collection, processing, and distribution.
This architecture is ideal for handling high-velocity, high-volume data while ensuring data quality and low-latency insights.
Streaming-based architecture, powered by Apache Kafka, revolutionizes data processing. It involves continuous data ingestion, enabling real-time collection, processing, and distribution. This approach facilitates real-time data processing, handles large volumes of data, and prioritizes data quality and low-latency insights.
The diagram below illustrates the various components involved in a streaming data integration architecture.
b. Event-Driven Integration Architecture
An event-driven architecture is a highly scalable and efficient approach for modern applications and microservices. This architecture responds to specific events or triggers within a system by ingesting data as the events occur, enabling the system to react quickly to changes. This allows for efficient handling of large volumes of data from various sources.
c. Lambda Integration Architecture
The Lambda architecture embraces a hybrid approach, skillfully blending the strengths of batch and real-time data ingestion. It comprises two parallel data pipelines, each with a distinct purpose. The batch layer expertly handles the processing of historical data, while the speed layer swiftly addresses real-time data. This architectural design ensures low-latency insights, upholding data accuracy and consistency even in extensive distributed systems.
d. Kappa Data Integration Architecture
Kappa architecture is a simplified variation of Lambda architecture specifically designed for real-time data processing. It employs a solitary stream processing engine, such as Apache Flink or Apache Kafka Streams, to manage both historical and real-time data, streamlining the data ingestion pipeline. This approach minimizes complexity and maintenance expenses while simultaneously delivering rapid and precise insights.
2. Near Real-Time Data Integration
In near real-time data integration, the data is processed and made available shortly after it is generated, which is critical for applications requiring timely data updates. Several patterns are used for near real-time data integration, a few of them have been highlighted below:
a. Change Data Capture — Data Integration
Change Data Capture (CDC) is a method of capturing changes that occur in a source system's data and propagating those changes to a target system.
b. Data Replication — Data Integration Architecture
With the Data Replication Integration Architecture, two databases can seamlessly and efficiently replicate data based on specific requirements. This architecture ensures that the target database stays in sync with the source database, providing both systems with up-to-date and consistent data. As a result, the replication process is smooth, allowing for effective data transfer and synchronization between the two databases.
c. Data Virtualization — Data Integration Architecture
In Data Virtualization, a virtual layer integrates disparate data sources into a unified view. It eliminates data replication, dynamically routes queries to source systems based on factors like data locality and performance, and provides a unified metadata layer. The virtual layer simplifies data management, improves query performance, and facilitates data governance and advanced integration scenarios. It empowers organizations to leverage their data assets effectively and unlock their full potential.
3. Batch Process: Data Integration
Batch Data Integration involves consolidating and conveying a collection of messages or records in a batch to minimize network traffic and overhead. Batch processing gathers data over a period of time and then processes it in batches. This approach is particularly beneficial when handling large data volumes or when the processing demands substantial resources. Additionally, this pattern enables the replication of master data to replica storage for analytical purposes. The advantage of this process is the transmission of refined results. The traditional batch process data integration patterns are:
Traditional ETL Architecture — Data Integration Architecture
This architectural design adheres to the conventional Extract, Transform, and Load (ETL) process. Within this architecture, there are several components:
- Extract: Data is obtained from a variety of source systems.
- Transform: Data undergoes a transformation process to convert it into the desired format.
- Load: Transformed data is then loaded into the designated target system, such as a data warehouse.
Incremental Batch Processing — Data Integration Architecture
This architecture optimizes processing by focusing only on new or modified data from the previous batch cycle. This approach enhances efficiency compared to full batch processing and alleviates the burden on the system's resources.
Micro Batch Processing — Data Integration Architecture
In Micro Batch Processing, small batches of data are processed at regular, frequent intervals. It strikes a balance between traditional batch processing and real-time processing. This approach significantly reduces latency compared to conventional batch processing techniques, providing a notable advantage.
Pationed Batch Processing — Data Integration Architecture
In this partitioned batch processing approach, voluminous datasets are strategically divided into smaller, manageable partitions. These partitions can then be efficiently processed independently, frequently leveraging the power of parallelism. This methodology offers a compelling advantage by reducing processing time significantly, making it an attractive choice for handling large-scale data.
Conclusion
Here are the main points to take away from this article:
- It's important to have a strong data governance framework in place when integrating data from different source systems.
- The data integration patterns should be selected based on the use cases, such as volume, velocity, and veracity.
- There are 3 types of Data integration styles, and we should choose the appropriate model based on different parameters.
Opinions expressed by DZone contributors are their own.
Comments