Event-Driven Architecture as a Strategy
Event-driven architecture provides five key benefits to modern application architecture: scalability, resilience, agility, data sharing, and cloud enabling.
Join the DZone community and get the full member experience.
Join For FreeEvent-driven architecture, or EDA, is an integration pattern where applications are oriented around publishing events and responding to events. It provides five key benefits to modern application architecture: scalability, resilience, agility, data sharing, and cloud-enabling.
This article explores how EDA fits into enterprise integration, its three styles, how it enables business strategy, its benefits and trade-offs, and the next steps to start an EDA implementation.
Although there are many brokers you can use to publish event messages, the open-source software Apache Kafka has emerged as the market leader in this space. This article is focused on a Kafka-based EDA, but much of the principles here apply to any EDA implementation.
Spectrum of Integration
If asked to describe integration a year ago, I would have said there are two modes: application integration and data integration. Today I’d say that integration is on a spectrum, with data on one end, application on the other end, and event integration in the middle.

Data integration is patterns for getting data from point A to point B, including ETL, managed file transfer, etc. They’re strong for BI reporting, ML pipelines, and other data movement tasks, but weaker than application integration for many B2B partnerships and applications sharing functionality.
Event integration has one foot in data and the other in application integration, and it largely gets the benefits of both. When one application subscribes to another app’s events, it can trigger application code in response to those events, which feels a bit like an API from application integration. The events triggering this functionality also carry with them a significant amount of data, which feels a bit like data integration.
EDA strikes a balance between the two classic integration modes. Refactoring traditional application integrations into an event integration pattern opens more doors for analytics, machine learning, BI, and data synchronization between applications. It gets the best of application and data integration patterns. This is especially relevant for companies moving towards an operating model of leveraging data to drive new channels and partnerships. If your integration strategy does not unlock your data, then that strategy will fail. But if your integration strategy unlocks data at the expense of application architecture that’s scalable and agile, then again it will fail. Event integration strikes a balance between both those needs.
Strategy vs. Tactic
EDA often begins with isolated teams as a tactic for delivering projects. Ideally, such a project would have a deliberative approach to EDA and a common event message broker, usually cloud-native brokers on AWS, Azure, etc. Different teams select different brokers to meet their immediate needs. They do not consider integration beyond their project scope. Eventually, they may face the need for enterprise integration at a later date.
A major transition in EDA maturity happens when the investment in EDA shifts from a project tactic to enterprise strategy via a common event bus, usually Apache Kafka. Events can take a role in the organization’s business and technical innovation across the enterprise. Data becomes more rapidly shareable across the enterprise and also between you and your external strategic partners.
EDA Styles
Before discussing the benefits of EDA, let’s cover the three common styles of EDA: event notification, event-carried state transfer, and event sourcing.
Event Notification
This pattern publishes events with minimal information: the event type, timestamps, and a key-value like an account number or some other key of the entity that raised the event. This informs subscribers that an event occurred, but if subscribers need any information about how that event changed things (like which fields changed, etc.), it must invoke a data retrieval service from the system of record. This is the simplest form of EDA, but it provides the least benefit.
Event-Carried State Transfer
In this pattern, the events carry all information about the state change, typically a before and after image. Subscribing systems can then store their cache of data without the need to retrieve it from the system of record.
This builds resilience since the subscribing systems can function if the source becomes unavailable. It helps performance, as there’s no remote call required to access source information. For example, if an inventory system publishes the full state of all inventory changes, a sales service subscribing to it can know the current inventory without retrieving from the inventory system — it can simply use the cache it built from the inventory events, even during an inventory service outage.
It also helps performance because the subscriber’s data storage can be custom-tuned just for that subscriber’s unique performance needs. Using the previous example, perhaps the inventory service is best suited using a relational database, but the sales service could get better performance from a no-SQL database like MongoDB. Since the sales services no longer need to retrieve from the inventory service, it’s at liberty to use a different DBMS than the inventory service. Additionally, if the inventory service is having an outage, the sales service would be unaffected since it pulls inventory data from its local cache.
The cons are that lots of data is copied around and there is more complexity on the receivers since they have to sort out maintaining all the state they are receiving.
Event Sourcing
With event-carried state transfer, you saw how the system of record can be reproduced from the event stream. Suppose your broker is a persistent event stream, meaning messages are never deleted. This is a feature that distinguishes Kafka from traditional message brokers. Now the event broker could be the system of record — that is event sourcing. All applications reconstruct an entity’s current state by replaying the events. This is the most mature version of EDA but it’s also the most difficult to implement and manage.
It creates a strong audit since we can see all events that led to the current state. We can recreate historic states for debugging purposes by replaying the event log up to a prior point in time. It also enables ephemeral working copies of the application state, such as in-memory databases and caches that can be recreated on the fly by replaying the event stream. This can become the backbone for microservices, CQRS, or the saga data consistency pattern.
A challenge is that clients need to deal with changes in the event schema over time. Even if the schema changed several years ago, you can’t replay that event stream unless your code can still interpret the old, obsolete schema. There may also be challenges in physically deleting data for legal compliance purposes since event streams are usually immutable other than appending new events. Very few companies embrace event sourcing due to these challenges.
Reading event stream data can be challenging. With databases, you don’t see incomplete transactions due to committing/rollback functionality. Materializing data from an event stream could include an incomplete transaction. For example, make a purchase that’s been requested but it’s not yet been determined that there’s enough inventory for it to be successful. The purchase event will be in the event stream, even though we don’t yet know if the purchases will succeed or fail.
Also, the fact that you must materialize the stream into a database means a bug in the code for materializing the stream into a database could result in bad data. Though to be fair, fixing the bug, purging the database, and re-materializing the stream would instantly correct the bad data.
Benefits
EDA offers five key benefits:
- Scalability
- Resilience
- Agility
- Unlocking data
- Accelerating a pivot to public cloud
Scalability and Resilience
One EDA resilience pattern is reducing data retrievals. With event-carried state transfer or event sourcing, each event carries all information about the state change that the subscribers could need. This allows subscribers to reproduce the state of the system of record without having to go back to another system of record and do a retrieval request. This reduces the load on the system of record and reduces the risk of widespread outages, as discussed above.
EDA can be used on its own or to support a microservices architecture. Its scalability and resilience benefits are especially valuable in supporting a microservices architecture.
A microservice is a service that’s tightly scoped, loosely coupled, independently deployable, and independently scalable. Because they’re tightly scoped and loosely coupled, they’re easier to manage as a product with a standing team for faster delivery. You also get greater agility, since smaller deployable code packages result in smaller regression testing. Smaller units running on private cloud containers have more scalability, allowing you to scale up hardware for the one service without having to scale up a giant monolith. For example, suppose the inventory retrieval service of your warehouse application is getting pounded with too much load. In a monolithic app, you have to add more instances of the whole warehouse application to scale it up. If the inventory retrieval service were a microservice, it would be independent of the rest of the warehouse application and you could scale up new instances of inventory retrieval service without scaling up the rest of the warehouse application.
Microservices don’t have a centralized database, because shared databases make them no longer independently deployable nor independently scalable. This creates a challenge of how microservices can share data without creating a complex, brittle web of interdependent services. Resilience is more important in distributed applications because each call between two separate services is potentially a new network failure point that didn’t exist when the application was a single giant monolith. Problems include:
- Fragility since an outage or performance degradation in service will cascade into all the clients invoking that service.
- A client must wait for a service call to finish, even if it could process other tasks, otherwise, you must build a multi-threaded client with all the complexity that entails.
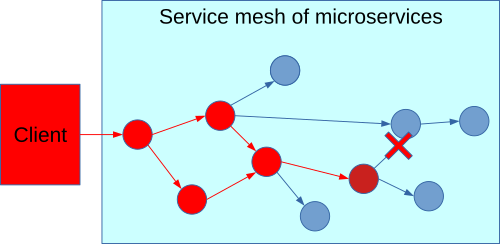
Those limitations can constrain the responsiveness and scalability that your IT department needs to meet business demands. EDA has emerged as a pattern to solve this communication challenge. For example:
- When an event is published to a message broker, a failure in the subscriber does not cascade into the event producer like happens with a service call failure. When that failure is recovered, the subscriber resumes reading messages from the message broker and continues where it left off.
- Clients and servers are also isolated from variations in their performance. Unlike asynchronous service calls, if a message recipient slows down or if the message-producing client scales up faster than the recipient can handle, it does not affect the message-producing client’s ability to scale.
- Subscribers are isolated from each other. Multiple subscribers to the same event stream can process events in parallel, even if one of the other subscribers is having an outage or slowdown.
- Event producers can move on to their next task without waiting for consumers to receive the event and even without the consumer being online, allowing for more parallel asynchronous processing.
Agility
EDA opens an integration pattern called choreography, which can increase agility by reducing dependencies between teams. For example, suppose you have the following flow:
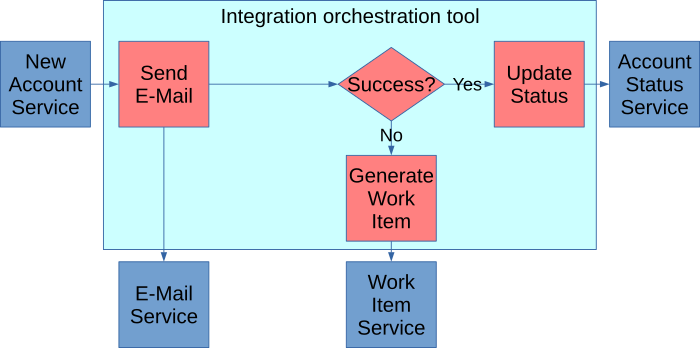
This is called orchestration. When a new account is established, a central integration tool like an ESB or iPaaS orchestrates an e-mail. If that e-mail fails, the integration tool triggers a work item for manual review. If it succeeds, it triggers a status change in the account.
Suppose the business says they want to capture the results of that e-mail success or failure — to gain insights for predicting when an e-mail may fail before attempting to send an e-mail:
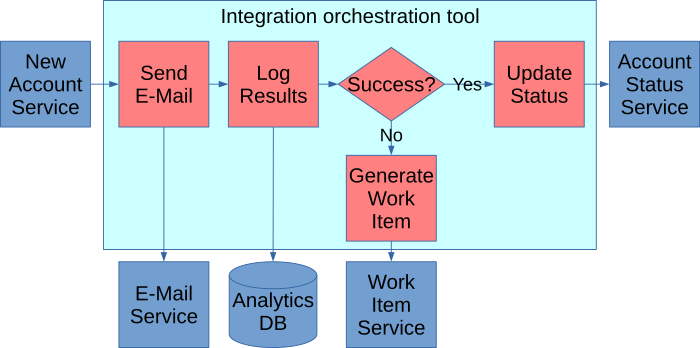
One challenge is that the team that owns the analytics database probably doesn’t own this integration orchestration tool, so it requires one team to reach out to another to get this work done. The second issue is that we’ve inserted a step in the middle of this code, meaning you need to assign testers to this project to regression test the steps downstream from the code insertion.
Here you see the same thing performed via an event-driven architecture.
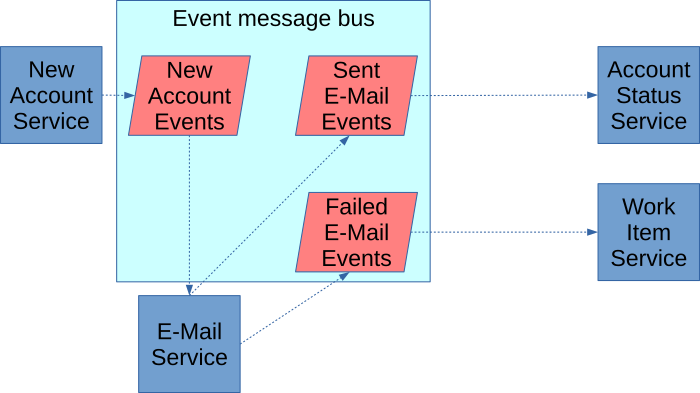
In this case, the new business application publishes an event that a new account has been established. The email application subscribes, knowing that it must send a confirmation email to all newly established accounts. Because it’s using the event-carried state transfer pattern, the e-mail application has all information about that account in the event message to send an e-mail. When an e-mail succeeds or fails, it publishes that event to the broker. From there, the process to update the account status subscribes to the success event stream, and the work item process subscribes to the failure. This publishes/subscribe model is called choreography.
Now when the business introduces this new requirement, we simply subscribe to the analytics database to the two relevant services, as shown here:
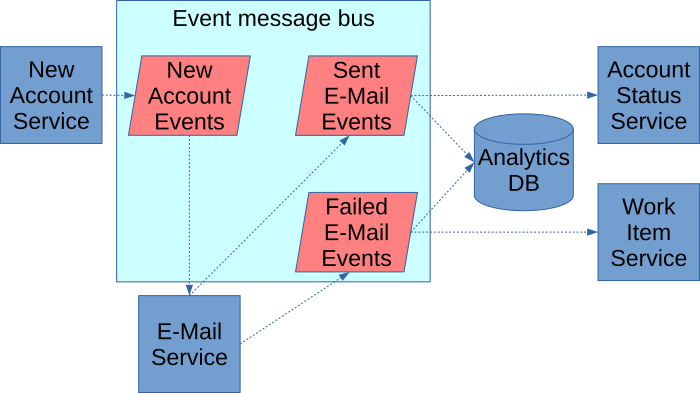
As you can see, since this does not insert code in the middle of a flow, the regression testing need goes away. Also, if you have a self-service model, the BI team could tap into this data without involving IT. Even without self-service, IT provisioning an access key to the event broker will much faster than IT implementing a code change like with orchestration.
This also demonstrates that every event stream is a potential future business enablement. A project launches and says, “If only I had purchase and inventory data.” If that data is already available through an event stream, the project can simply subscribe to that stream rather than building a whole new data pipeline. Hence, even applications that are not event-driven can benefit from subscribing to the event-streams of other EDA applications.
For example, Capital One launch many projects by first going to a dashboard of ready-built events streams, then tapping into the streams that provide the data that the project needs and starting the coding from there.
Unlock Your Data
In the previous example, you saw how data is unlocked by tapping into existing data streams. You build a stream for a specific client, but then anyone else who needs it can tap into it. This could include B2B partners via replication. It’s easy to replicate data between Kafka clusters: it’s just a short config file using tools like Mirror Maker or Confluent Replicator. Many startup companies use Kafka for their data integration, making this a viable option for many partnerships.
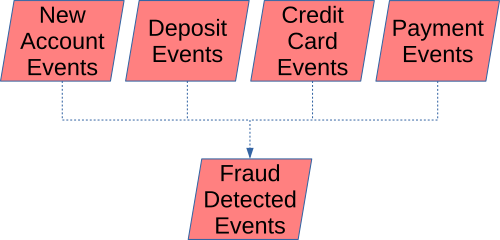
Event streams can be combined to form “complex events” and a view of the whole enterprise. For example at a bank, some mix of events from the same customer across several banking applications might indicate fraud that would not be visible when looking at one application in a silo. Kafka stream processing tools can join events from different event streams to publish a “fraud activity” event for further investigation.
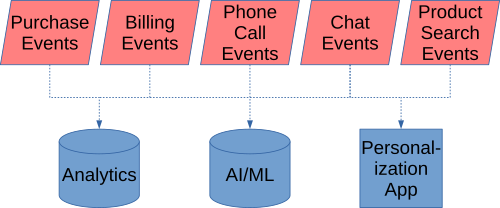
You can use event streams to get company-wide insights by feeding events from several applications into analytics, ML tools, and other applications like CRM personalization. This gives insights for the whole enterprise rather than just one specific application. For example, collecting all events about a customer’s activity: sales, billing, phone calls, chats, and other activity spanning all of the customer’s accounts. This can give a 360-degree view of a customer and let you derive top predictive variables about customers from activity spanning the enterprise.
Besides benefiting your business internally, it could also provide insights you can monetize with partners who share your customer base.
Finally, other applications (such as CRM personalization) can respond in real-time to customer activities occurring anywhere in the enterprise.
Pivot to Cloud
Kafka can easily replicate events so on-premises and public cloud applications all see each other's events. This enables faster adoption of the public cloud. For example, suppose you need to migrate a legacy on-premises application to a public cloud. A common challenge to this is "data gravity," where all the data flowing in and out of that application is tied to on-premises applications. When data is published to Kafka, using the replication features described above makes that data equally available in all data centers and clouds. This eliminates the data gravity problem - data consumers all see the same data, regardless of where they're hosted.
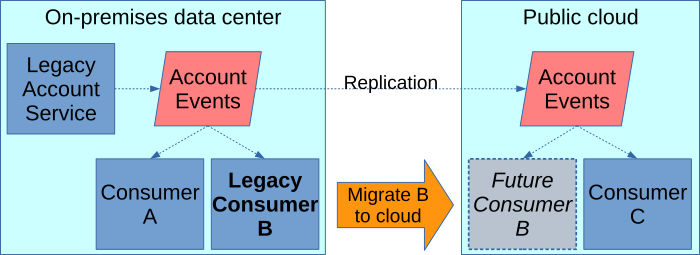
Legacy data producers can also more easily move to the public cloud without effecting its on-premises data consumers by reversing the direction of the replication. For example, if the legacy account service application in the image above were to move to the public cloud, it would look like the following, with no impact on its remaining on-premises consumer.
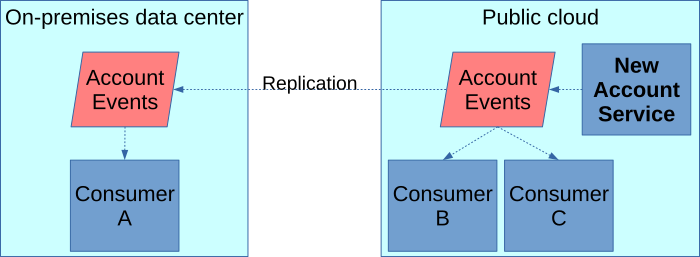
Furthermore, companies that embrace iPaaS will likely have a connector in their iPaaS tool for Kafka or other popular event brokers, allowing developers to read and write event messages using low code configuration for their cloud applications.
Challenges
Like everything in IT architecture, EDA is not a silver bullet. It has its limitations and trade-offs.
APIs vs. EDA
EDA compliments APIs but doesn't replace them. There are many cases where an API is better suited than EDA. Event publishers don't care who's subscribed and cannot receive a response. It's poorly suited to when the publisher does require a response or some other coupling with the subscriber. In this case, use APIs instead. For example, web or mobile UIs should use APIs, because they're requesting data and need a response. Or, if you're uploading a file to a vendor and require an acknowledgment that the file was accepted, use an API.
One way to think of APIs and EDA is that the couple in opposite directions. An API service doesn't care what clients call it, while an event producer does not care what services are on its receiving end. If you have a process where you want to swap it's invoking clients in and out, an API will work but an EDA will not. On the contrary, if you have a data-producing process where you want to swap in and out of its receiving services, an EDA will work much better than an API.
Other Trade-Offs
Although teams obtain more independence, the infrastructure to support it (like Kafka) can be quite complex.
EDA is eventually consistent. It is unsuitable when continuous consistency of the data is a must. Even when eventual consistency is acceptable, eventual consistency is a major shift from how IT traditionally handles data. It requires a challenging mindset change for developers and data architects, and it pushes many traditional data architects out of their comfort zone.
Finally, since EDA makes the overall system so decentralized and decoupled, it can be hard to understand the big picture of the system. Specifically, tracing where an event went and all the things it subsequently triggered can be challenging. Strong monitoring and logging will be required for the optimal supportability of EDA.
Real-World Example
Let’s move from theory to a real-world story of EDA success. Centene is a $60 billion managed care enterprise that offers health insurance and acts as an intermediary for government health insurance programs like Medicaid. A challenge they faced was how to share data while experiencing rapid growth and aggressive marketing and advertising strategy.
- Having a monolithic database from which everyone retrieved data didn't scale and became a single point of failure.
- Batch file transfers had consistency problems since data took a long time to get where it was going. It was also taxing on databases to query whole databases to create the daily batch data dumps.
- APIs to fetch data taxed their API server. They also found it costly to refactor legacy applications, such as turning COBOL services into an API. Often times publishing events from a legacy application to Kafka was a much cheaper refactor. APIs also raised availability questions: what if only 3 of the 4 data retrieval APIs succeed? Scalability was limited to the weakest performing API.
Centene solved those data-sharing challenges with EDA. Once this architecture was in place, they saw additional business benefits. They were able to build larger complex events by combining events or by detecting the absence of an expected event at the same time as another event. It also allowed their systems to know why something was happening and react to it in real-time. Finally, they enforced schema validation on event messages and found that it improved the quality of the data shared with their partners.
Next Steps
To make your next step into EDA, first, engage each of your lines of business to evaluate key events in the customer value chain that would have strategic value being published on an enterprise event broker.
At the same time, communicate the value of EDA to your IT organization. Emphasize its strengths but be clear on its weaknesses. Work with IT to identify applications that could more easily move to and benefit from EDA.
Use those two discussions to identify where an EDA investment will provide the most value and build a plan - what applications will publish what data, who will subscribe, and which of the above five benefits is driving the investment.
Invest in the infrastructure needed for EDA. Specifically, you will need strong observability tools, as described in the trade-offs discussion and one or more event brokers.
Which broker(s) you use will depend on various factors:
- Will you embrace EDA as a project tactic or enterprise strategy?
- Are you in public cloud, on-premises, or hybrid of both?
For enterprise strategy, a uniform broker for the whole enterprise will have more value, whereas a tactical approach could see different teams using different brokers.
If you're in one public cloud, there are many tools the cloud providers offer to facilitate EDA: SQS/SNS, Kinesis, EventBridge, Service Bus, etc. You may be able to settle on one of these. If you're in a hybrid or multi-cloud environment and many of your events will be crossing cloud boundaries, a uniform tool like Kafka will be better suited to eliminate the need to mediate between several incompatible brokers. For an on-premises only situation, given the complexity of standing up some message brokers, consider using a vendor that provides features and support that will lessen the burden on your infrastructure and operations team.
Conclusion
In sum, EDA provides a new tool in your IT architecture toolbox for building modern systems that need scalability, resilience, and agility. It helps unlock data to build new data-driven channels and data-driven partnerships. It can help you pivot to the cloud. While it has some trade-offs, the value it provides can be quite significant.
The journey towards EDA can be a long one, but the rewards will be key for building IT systems that out-compete in the marketplace.
Published at DZone with permission of David Mooter. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments