Indexing Across Data Models: From Tables to Documents to Text
Learn how database indexes — hash, B-tree, R-tree, bitmap, inverted, and vector — boost query performance across relational, NoSQL, and search systems.
Join the DZone community and get the full member experience.
Join For FreeEvery modern software application relies on a database to persist and manage its data. The choice of database technology is largely influenced by the application’s data model and its read and write throughput.
For large datasets, query efficiency is critical. An inefficient query that works on a small dataset can quickly turn into a performance bottleneck when scaled to hundreds of thousands or millions of data points. While query optimization helps, it alone cannot guarantee high throughput. Factors such as data modeling, normalization, partitioning strategies, indexing, and even hardware resources all play a role in determining how quickly a system can serve reads and process writes.
In this article, we will focus on indexes — one of the most powerful techniques for improving overall database performance. We’ll explore what indexes are, how they work, and how they can dramatically influence both read and write throughput in real-world systems.
Indexes
Imagine you are visiting a library to find a book to read. The library has organized its books into sections, e.g., science, fiction, or autobiographies. If you are interested in fiction, you head straight to that section, skipping the others.
Within the fiction section, suppose the books are arranged alphabetically by title on different racks. If you are looking for a book that starts with “L,” you would go directly to the rack labeled “L” instead of scanning every shelf.
This is similar to how indexes work in databases. Just like the sections in a library help you quickly find the right book, a database index helps the system quickly find the right data — without searching through everything.
Imagine if the library didn’t have any sections or alphabetical arrangement. You would have to check each book one by one until you find the one you are looking for. The bigger the library, the longer it would take.
In computing terms, this kind of search is called O(n) — which means the time it takes grows in direct proportion to the number of items. So, if the library doubles in size, your search time roughly doubles too!
That’s why indexes are so important in databases — they help avoid this slow, manual search and make data retrieval efficient and much faster.
Definition
In its minimalistic form, an index can be defined as —
An additional metadata, derived from primary data, serving as an indicator to efficiently locate the data.
In the library analogy, the category and title-wise section serves as the metadata to quickly locate the required book.
A typical index has the following characteristics:
- Indexes only utilize the primary data without affecting it, i.e., whether indexed or not, the primary data stays as-is.
- While indexes improve read, they lower the write throughput as the indexes require updates for every change in primary data.
- There could be multiple indexes on the same data for different ways of lookup. E.g., a book could be indexed independently based on its category, title, author, publisher, etc. The index could even be a combination of these, which is termed a composite index.
- Most indexes are to be chosen manually so that the application is in control instead of the tools themselves.
Type of Indexes
As the primary purpose of an index is to boost reads, the read (or query) pattern determines the index type or its structure for optimal results. For key-value data, a hash-based index would suffice if data is queried via its key only. In case the query requires multiple attributes of data (i.e., value), then indexes based on Log-structured merge-tree (LSM) or B-Tree are utilized. Moreover, if a multi-dimensional range query is required, then R-Tree-based indexes are required.
Let's explore various index types and their corresponding use cases.
Hash Index
Hash indexes use a hash function to map keys to a hash bucket. This enables constant time, i.e., O(1), lookup for an exact match. It is best suited for key-value type data lookup with unique keys.
Since hashing doesn’t maintain order, hash indexes are unsuitable for any range-based queries.
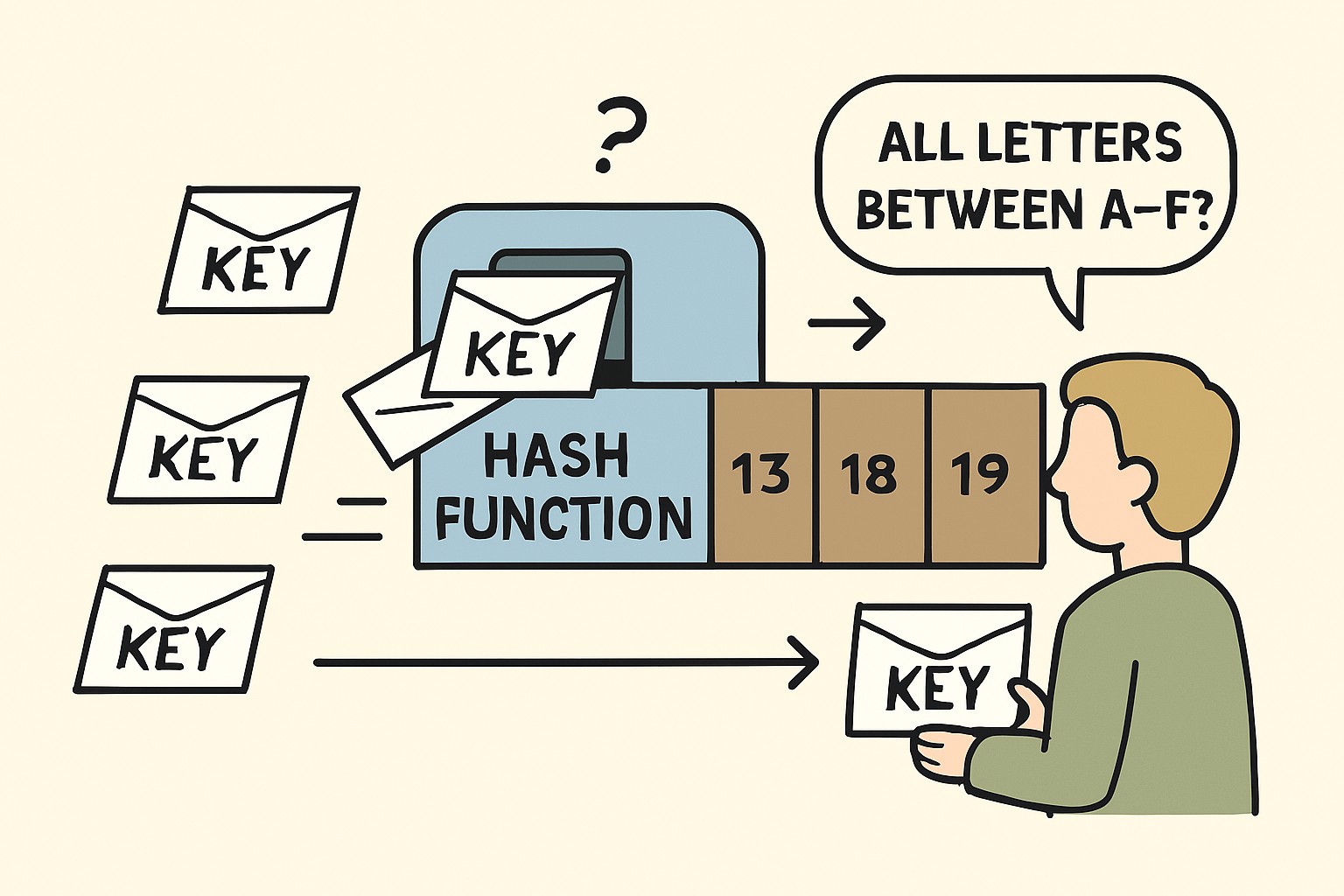
Typical Hash Indexes
Popular tools that utilize hash-based indexes include MySQL Memory (HEAP) Engine, which defaults to hash indexes for in-memory tables; Redis, known for its core data structures that deliver microsecond-level access; and PostgreSQL, which serves as an alternative to default B-trees and is optimized for equality checks.
Log-Structured Merge Tree (LSM)
LSM tree indexes maintain an in-memory index structure for all the writes, which is often a balanced tree, like a red-black tree. To provide durable storage of writes, they are also updated sequentially as write-ahead logs. On reaching a certain threshold, this in-memory index data is flushed to disk as an immutable, sorted file called a Sorted String Table (SSTable), which acts as the core index.
To serve any reads first in-memory index is consulted, followed by SSTables. To add more efficient lookup, Bloom filters are utilized to rule out SSTables that may not have the requested data. Moreover, the background process ensures the stale entries are periodically purged from SSTables via merge and compaction.
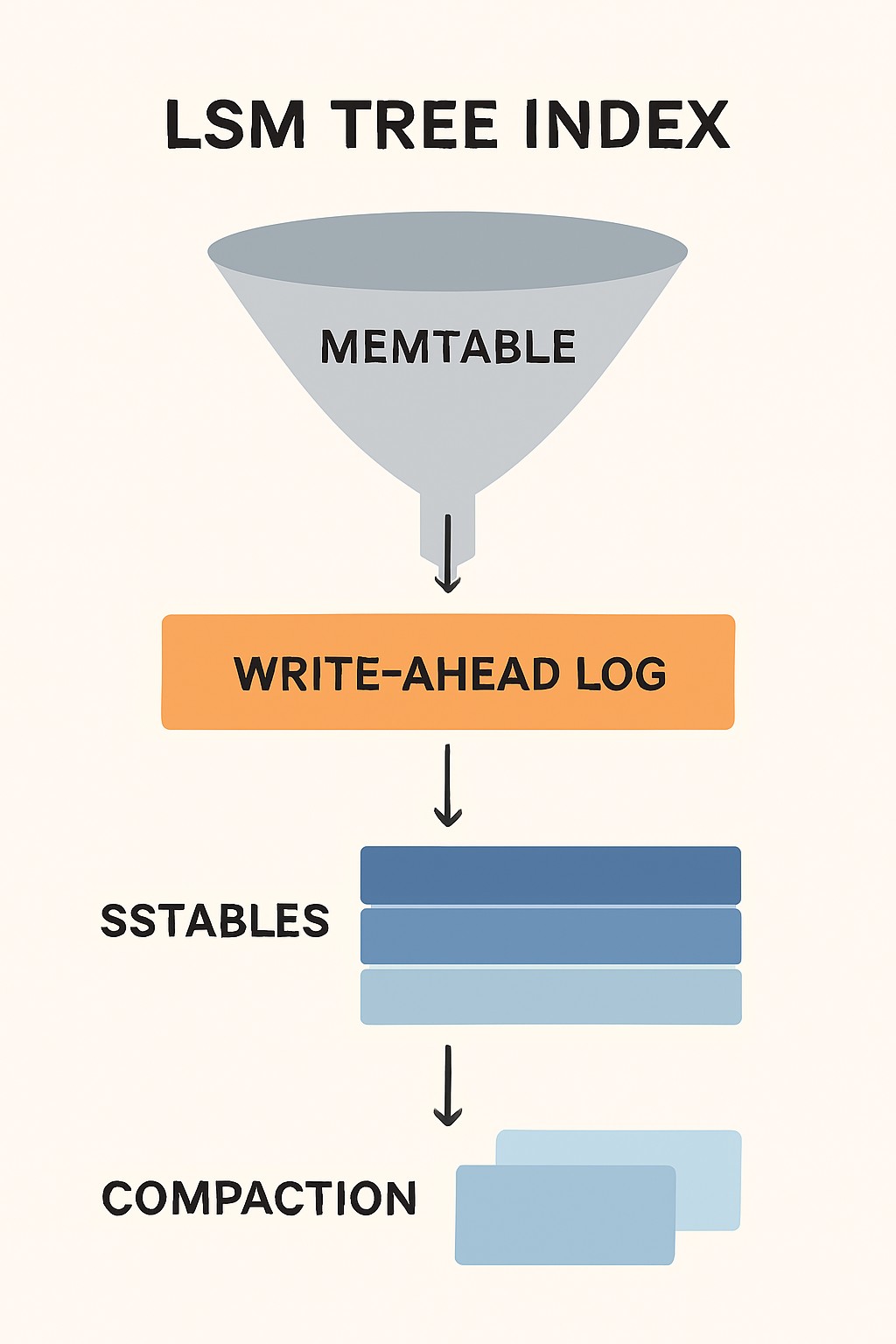
Typical Log-Structured Merge-Tree Indexes
As the LSM tree is designed for write-heavy workloads to achieve excellent write throughput, these indexes are suitable for large-scale key-value stores only (e.g., Cassandra, LevelDB, RocksDB).
Depending upon the data spread across multiple SSTables, the read throughput may be slower than that of other indexes.
Note: Apache Lucene utilizes LSM for fuzzy text search up to a certain edit distance.
B-Tree
A B-tree is a balanced tree structure where data is stored in sorted order across nodes called pages. Each node may have multiple children, ensuring the tree remains shallow and lookups are fast.
Searching, inserting, and deleting involve traversing from the root down to the leaf, usually in O(log n) time.
A B‑tree index is much like a library index — instead of scanning every book, follow the guideposts until you locate the exact book you need.
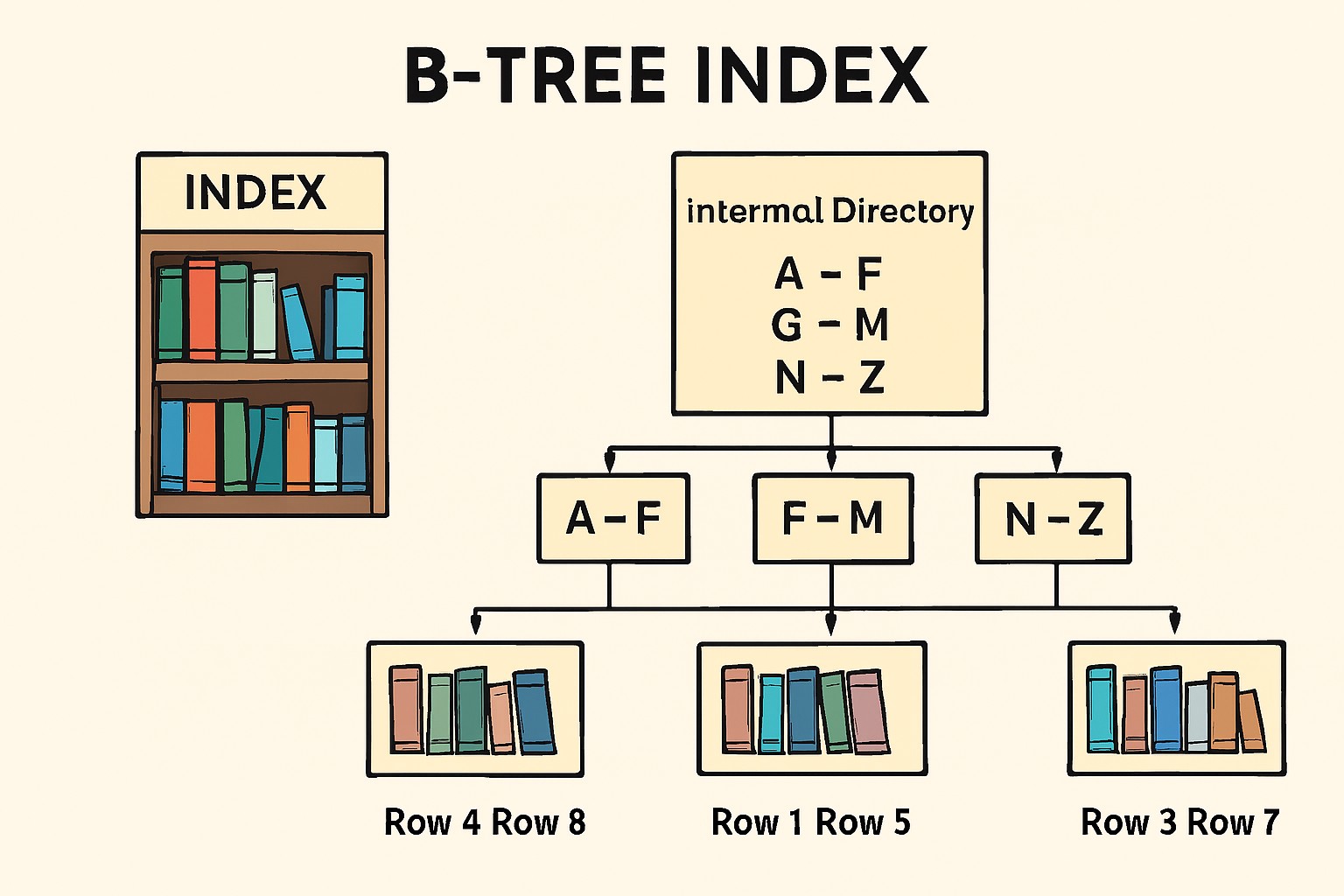
Typical B-Tree Indexes
A B-tree is ideal for read-heavy workloads and range queries. Thus, this is the most common index in relational databases (e.g., MySQL — InnoDB, PostgreSQL, Oracle) where predictable query performance is critical.
It's imperative to note that most databases use a B+ tree variant instead, where only leaf nodes store row pointers, and internal nodes only guide navigation. This makes range scans even faster.
Rectangle-Tree (R-Tree)
A rectangle-tree (R-tree) is a hierarchical, balanced tree structure designed to index multi-dimensional spatial data like points, rectangles, polygons, or geographic coordinates. R-tree can be considered as the spatial equivalent of a B-tree, which is for one-dimensional data only.
In an R-tree, each node represents a minimum bounding rectangle (MBR) or Bounding Box (BBOX) that encloses its children. The root node covers the entire dataset, and internal nodes contain the MBRs pointing to child nodes. The leaf nodes store actual object data or its references.
So when a range or geo-spatial query is made, only the relevant bounding rectangles are traversed. Thu,s eliminating the full traversal. R-tree search, insert/delete is O(log n) with worst case as O(n) only if bounding boxes overlap heavily.
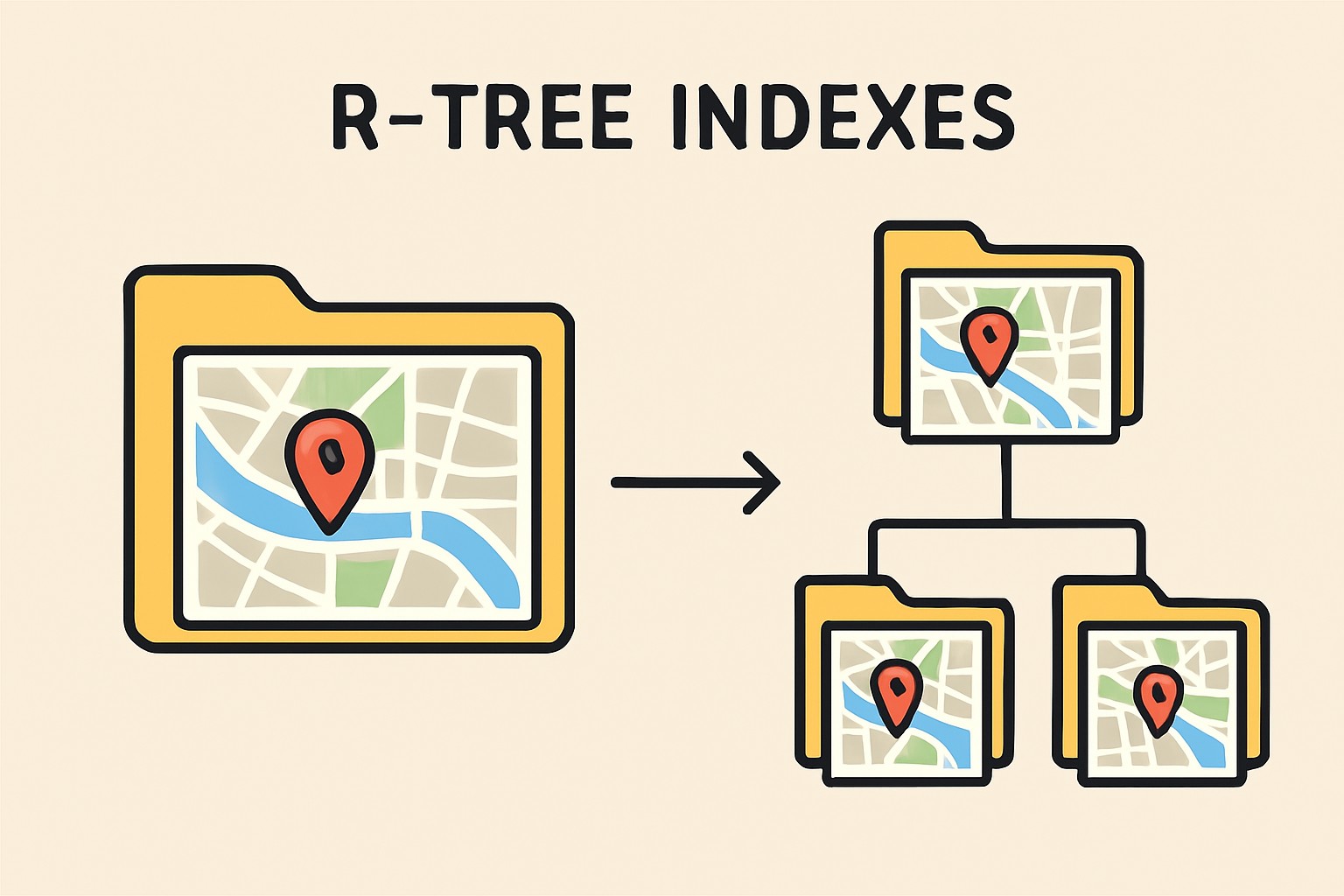
Typical Rectangle Tree Indexes
R-tree is most efficient for range queries such as “all restaurants within 2 km” or searching for nearest-neighbor, like “closed hospital from current location.”
PostgreSQL (with PostGIS) uses R-tree-over-GiST spatial indexes for geospatial queries. SQLite has a built-in R-tree module for geometry-heavy apps. Many GIS systems, including ArcGIS, QGIS, and other mapping platforms, rely on R-trees for fast rendering and querying.
Note: Elasticsearch uses a BKD tree to support geospatial query indexing. Internally, this BKD tree is converted to an R-tree.
Bitmap Index
A bitmap index is a special type of database index that uses bit arrays (bitmaps) instead of traditional tree structures. Each distinct value in a column gets its own bitmap (a sequence of 1s and 0s), where each bit corresponds to a row. 1 represents the row containing the value, and 0 represents the row that does not contain the value.
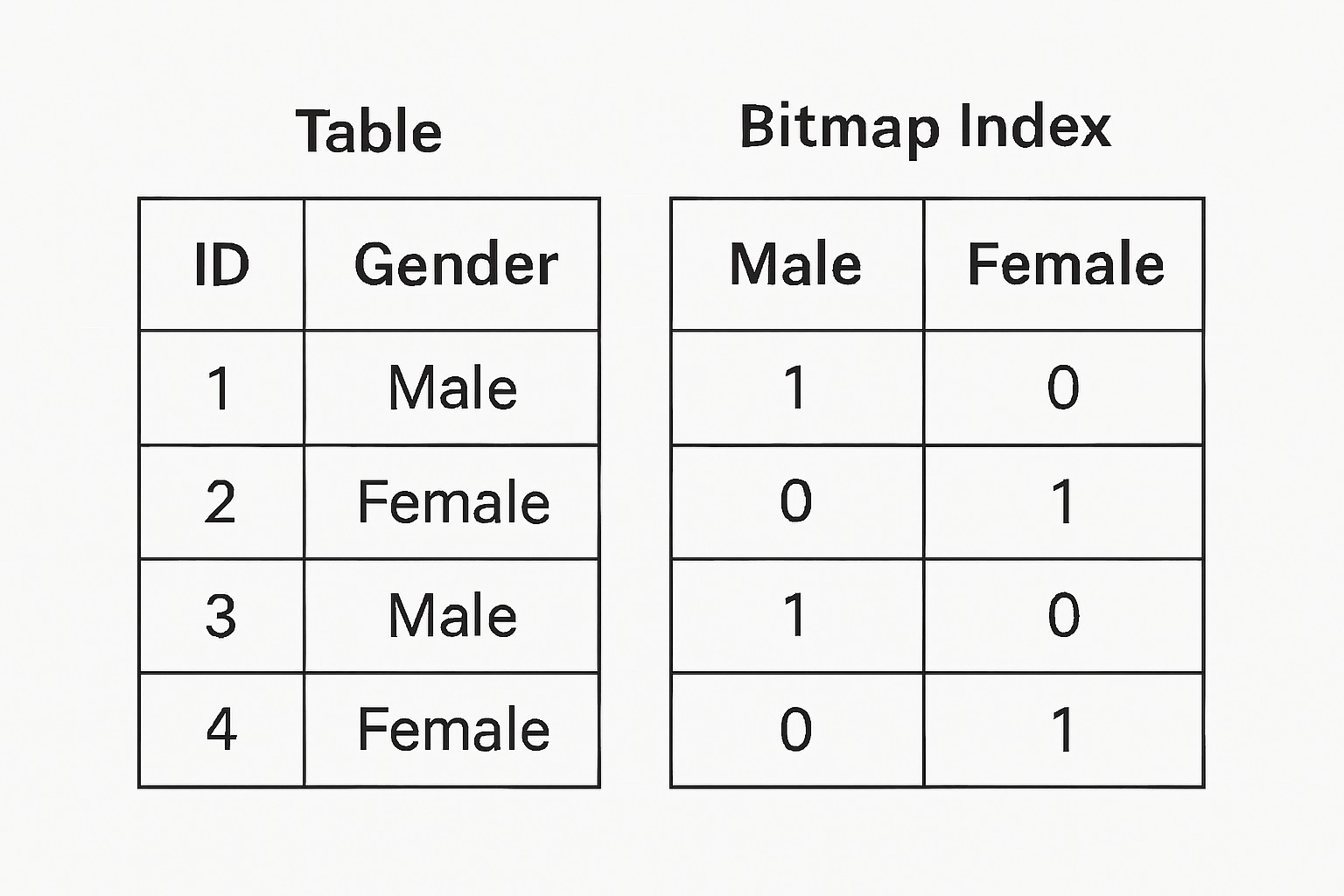
Typical Bitmap Indexes
Bitmap indexes are best suited for low-cardinality columns, i.e., with few distinct values, e.g., gender, boolean flags, marital status, region codes, etc. Moreover, any bitwise operations (AND, OR, NOT) on bitmaps are extremely efficient.
Bitmap indexes are commonly used in data warehouses and read-heavy systems where queries often combine multiple filters.
Oracle Database offers native bitmap indexing while PostgreSQL supports bitmap scans (but not persistent bitmap indexes by default). Apache Hive and Spark SQL use bitmap-based techniques in their respective query optimization layers.
Inverted Index
An inverted index is a data structure that maps terms (words) to the list of documents (or locations) where they appear. In an inverted index, each unique word in the dataset is stored once. Before being stored, the word is normalized, i.e., transformed to lowercasing, stemming, or removed if it's a stop word.
Against the word, a list of document IDs (and sometimes positions) where that word occurs is stored. This enables the query to return the documents quickly where the specified word is present.
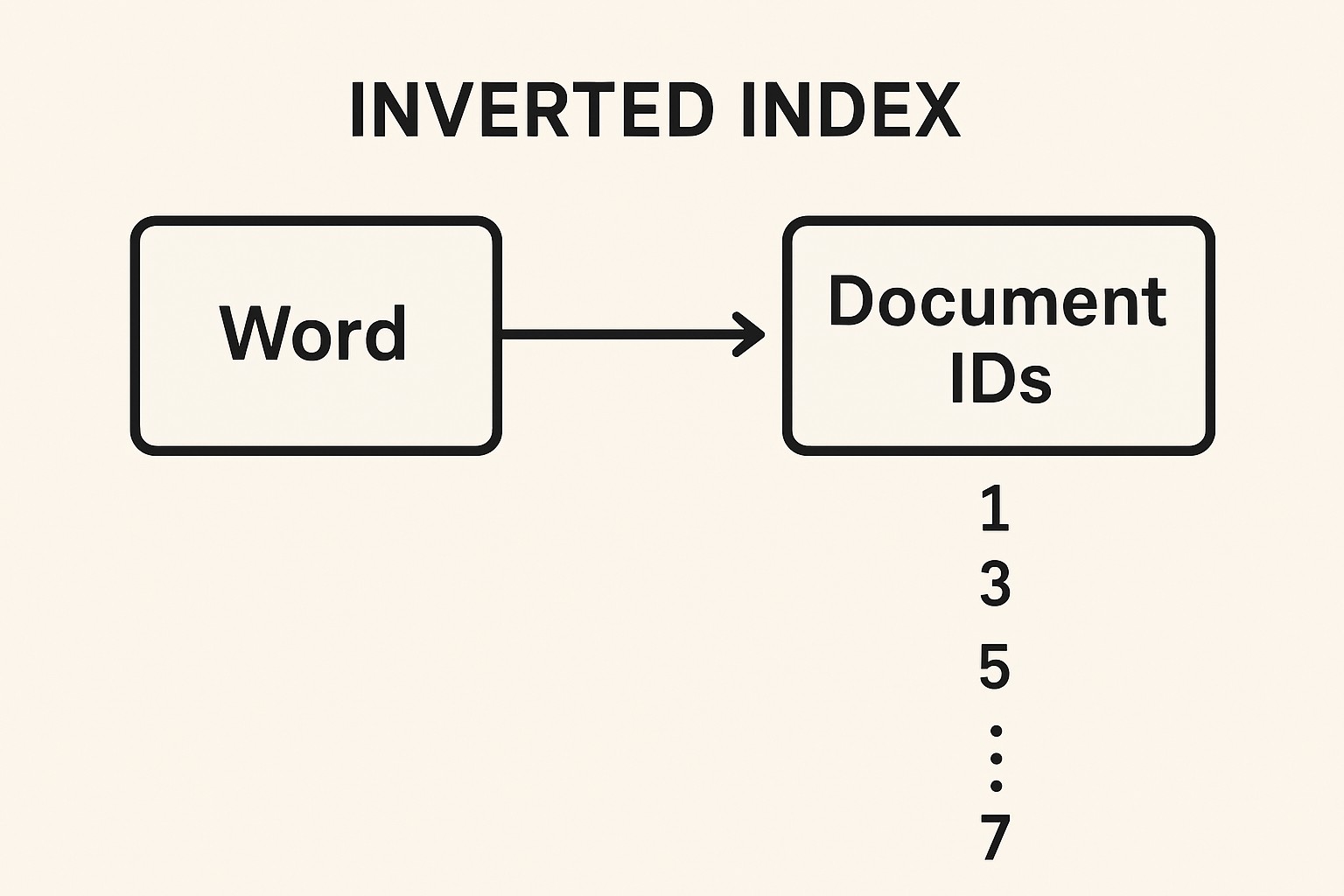
Typical Inverted Indexes
Inverted indexes are the backbone of modern search engines. They are used in log aggregation platforms (e.g., Splunk, ELK stack) to query terabytes of machine data in near real time. Moreover, some RDBMS (like PostgreSQL’s GIN index) and NoSQL systems (Elasticsearch, Apache Lucene, Solr, etc.) use inverted indexes too for full-text search.
Vector Index
A vector index is a data structure designed to store and search high-dimensional vectors efficiently. Instead of exact matches (like traditional indexes), they enable similarity search — finding items, e.g., “Find me all the products in the image that look like this one,” or “Suggest songs that feel like this track.” While B-Trees unlocked fast relational queries, Vector indexes are unlocking fast semantic queries.
Vector indexes handle such high-dimensional vector embeddings via mathematical representations of text, images, audio, or user behavior. At their core, vector indexes organize embeddings in a way that makes Approximate Nearest Neighbor (ANN) search efficient.
Typical implementations include Inverted File Index (IVF), Hierarchical Navigable Small World Graph (HNSW), and Product Quantization (PQ).
Typical Vector Indexes
Typical usage of Vector indexes includes recommendation systems, computer vision — such as image or video retrieval by “visual similarity” — and AI memory and retrieval-augmented generation (RAG), where large language models (LLMs) retrieve relevant context from vast knowledge bases.
Several modern tools and databases implement vector indexing under the hood, e.g., Facebook AI Similarity Search (FAISS) — an open-source library for ANN search, and Annoy (Spotify) — optimized for recommendation systems.
Secondary Index
A secondary index is an additional index created on a non-primary key attribute(s) of a table. Unlike the primary index (which is tied to the primary key and usually unique), a secondary index can be built on any column(s), even those with duplicate values. Whenever data is inserted, updated, or deleted, the secondary index must also be updated — so there is a trade-off between faster reads and slower writes.
Typically, secondary indexes are used to speed up queries that filter or sort on non-primary key columns. Also, it allows efficient access paths for multiple attributes in the same data. Secondary indexes are especially helpful in large datasets where scanning the whole table would be too slow.
In traditional relational databases, PostgreSQL supports B-tree, Hash, GIN, and BRIN secondary indexes. MySQL/MariaDB has secondary indexes on InnoDB tables. Oracle and SQL Server heavily rely on secondary indexes for query optimization.
In NoSQL Databases, MongoDB allows secondary indexes on fields beyond _id similar to CouchBase, which terms these as “Global Secondary Indexes GSI” instead. In Elasticsearch, its inverted index structure serves a similar purpose for text search.
Composite or Concatenated Index
A composite index (also called a concatenated index or multi-column index) is an index built on two or more columns of a table, instead of just one.
It stores a combined, ordered structure of multiple columns, allowing the database to quickly locate rows based on those columns together. The sequence of columns in the index is critical. E.g., an index on (last_name, first_name) can efficiently support queries filtering by last_name alone, or by both last_name and first_name — but not by first_name alone.
Having individual indexes on each column is not the same; the optimizer may not combine them as efficiently as a single composite index.
A composite index is typically useful when queries often filter, sort, or join on the same set of columns.
Composite index is supported in all major relational databases. PostgreSQL uses B-tree composite indexes with advanced variations like multicolumn GiST indexes. SQL Server supports composite clustered and non-clustered indexes, with options like included columns. Oracle supports concatenated indexes with optimizer hints for fine-tuning.
Even NoSQL systems like MongoDB support compound indexes, applying similar principles.
Clustered Index
A clustered index is a way of organizing data in a database table so that the rows are physically stored on disk in the same order as the index. Since the table’s rows can only be stored in one order, only one clustered index per table is possible. Queries that search by the clustered index key (e.g., primary key, date, or ID) are very efficient because the data is already sorted that way. It’s usually implemented as a B-tree, where leaf nodes contain the actual data rows. A clustered index could be on a single column or on multiple columns (i.e., composite index), too.
Clustered indexes are best suited for range queries since the rows are stored in order, and the database can quickly scan a contiguous block. Queries with ORDERBY or GROUP BY on the clustered column often skip extra sorting steps. Since the clustered index is often built on the primary key, fetching rows by ID is thus lightning fast.
However, clustered indexes can slow down insert-heavy workloads (because new rows must be slotted into the correct physical position) and make updates to indexed columns more expensive.
SQL Server and MySQL (InnoDB engine) always cluster data around the primary key. PostgreSQL doesn’t maintain clustered indexes automatically, but it can be used with the CLUSTER command to reorder a table physically. Oracle uses Index-Organized Tables (IOTs), which are essentially clustered indexes.
Conclusion
While most software professionals don’t need to master every internal detail of database indexes, understanding their fundamentals is highly valuable. Indexes are not just abstract data structures; they directly shape how efficiently applications handle queries, scale under load, and balance read/write performance. With this knowledge, engineers and architects can make more informed choices about which database engines or index types best suit their data models and query patterns.
However, real-world performance depends on data distribution, workload, and hardware. That’s why benchmarking with actual datasets is essential before adopting or switching indexes. Thoughtful selection, validated by testing, ensures systems remain efficient, resilient, and scalable in practice.
References and Further Reading
Published at DZone with permission of Ammar Husain. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments