Data Structures and Their Applications
Data structures are essential components in creating fast and powerful algorithms. They help to manage and organize data.
Join the DZone community and get the full member experience.
Join For FreeWhat Is a Data Structure?
There can be many definitions for a data structure, but the easiest one to understand is the following:
A data structure is a way of organizing data in some fashion so that later on, it can be accessed, queried, or even updated easily and quickly.
It is a collection of values. The values can have relationships among them and they can have functions applied to them. Each one is different in what it can do and what it is best used for. Each is good and is specialized for its own thing.
They are essential components in creating fast and powerful algorithms. They help to manage and organize data so that it will make our code cleaner and easier to understand. Data structures can make the difference between an Okay product and an outstanding one.
Before getting to Data structures, we have to talk about the abstraction of Data structures. In other words, let’s discuss the concept of Abstract Data Types.
What Is Abstract Data Type (ADT)?
An abstract data type (ADT) is simply an abstraction of a data structure. It provides only the interface to which a data structure must adhere to. The interface doesn’t provide any specific details about how something should be implemented or in what programming language.
They are called “abstract” because they are just theoretical concepts and every programming language has different ways of implementing it.

Let’s now take a look at a few of some well-known data structures and applications.
Array
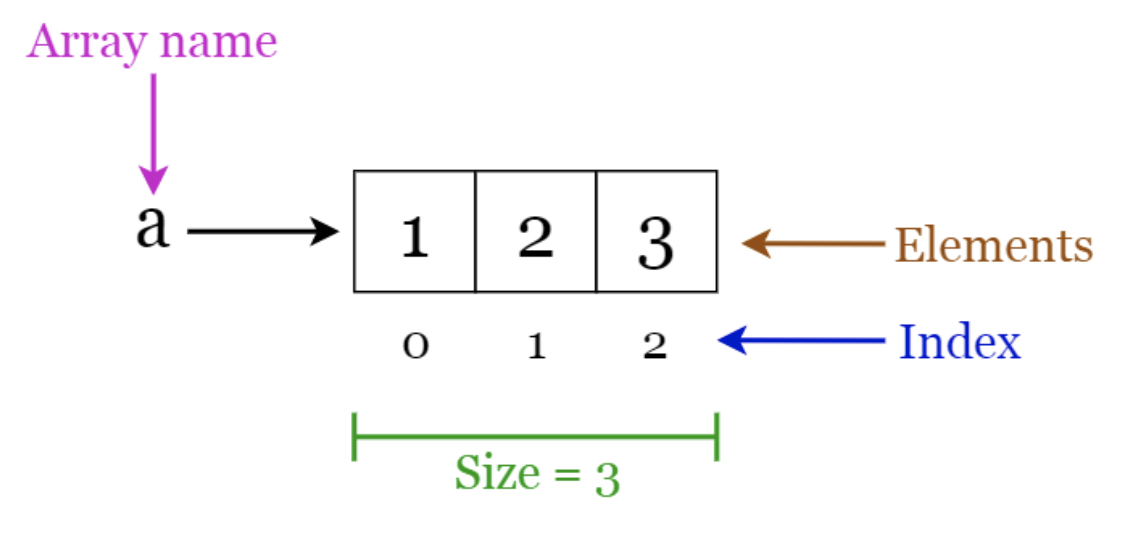
A static array is a fixed-length container containing n elements indexable from the range [0, n-1]. Indexable means that each slot/index in the array can be referenced with a number called index key (typically zero-based). This allows random access to any array element. Static arrays are given as contiguous chunks of memory.
The name assigned to an array is typically a pointer to the first item in the array. It means that given an array named myArray which was assigned the value [‘a’, ‘b’, ‘c’, ‘d’, ‘e’], in order to access the ‘c’ element, we would use the index 2 to lookup the value (myArray[2]).
Arrays are traditionally ‘finite’ in size, means that we define their length/size (i.e. memory capacity) in advance, but there is a concept known as ‘dynamic arrays’ (and of which you’re likely more familiar with when dealing with certain high-level programming languages) which supports the growing (or resizing) of an array to allow for adding more elements to it. But under the hook, the new array (normally with double size compared to the original) is created in order to copy the original array element values over to.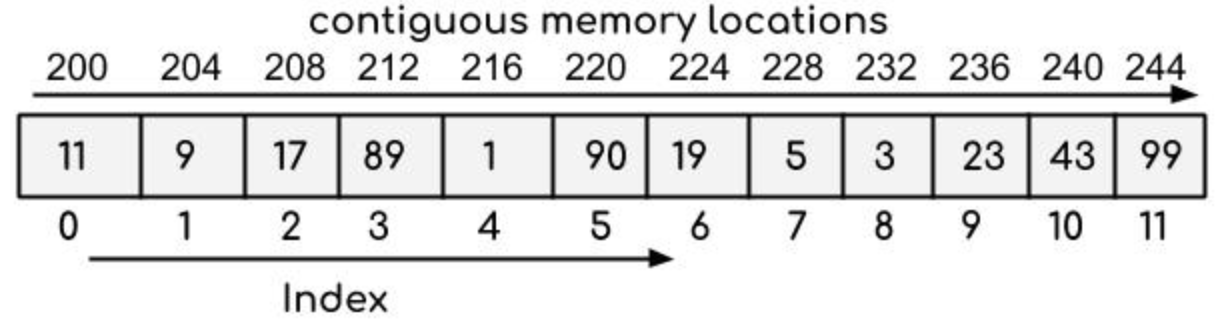
Array's Application Examples
- Used as the primitive building blocks to build other data structures such as array lists, heaps, hash tables, vectors and matrices.
- Used for different sorting algorithms (insertion sort, quick sort, bubble sort and merge sort..).
Linked List

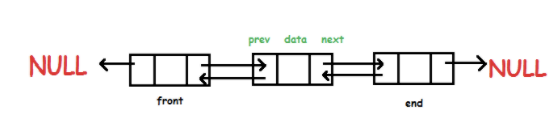
A linked list is different from an array in the order of the elements within the list that is not determined by contiguous memory allocation. Instead, the elements of the linked list can be sporadically placed in memory due to its design, which is that each element of the list (also referred to as a ‘node’) consists of two parts:
- The data
- A pointer
The data is what we’ve assigned to that element/node, whereas the pointer is a memory address reference to the next node in the list.

Unlike an array, there is no index access. So in order to locate a specific piece of data or element we will have to traverse the entire list until we find the element we’re looking for. That operation takes O(n) complexity.
This is one of the key performance characteristics of a linked list and is why (for most implementations of this data structure) we’re not able to append data/element to the list (because talking about the performance of such an operation, it would require us to traverse the entire list to find the end/last node). Instead linked lists generally will only allow prepending to a list as it’s much faster. The newly added node will then have its pointer set to the original ‘head’ of the list.
There is also a modified version of this data structure called ‘doubly linked list’ which is essentially the same idea but with the exception of the third attribute for each node: a pointer to the previous node (in a normal linked list we only have a pointer to the following node).
Applications of Linked Lists
- Used for symbol table management in a designing compiler
- Used in switching between applications and programs in the Operating system (implemented using Circular Linked List)

Tree
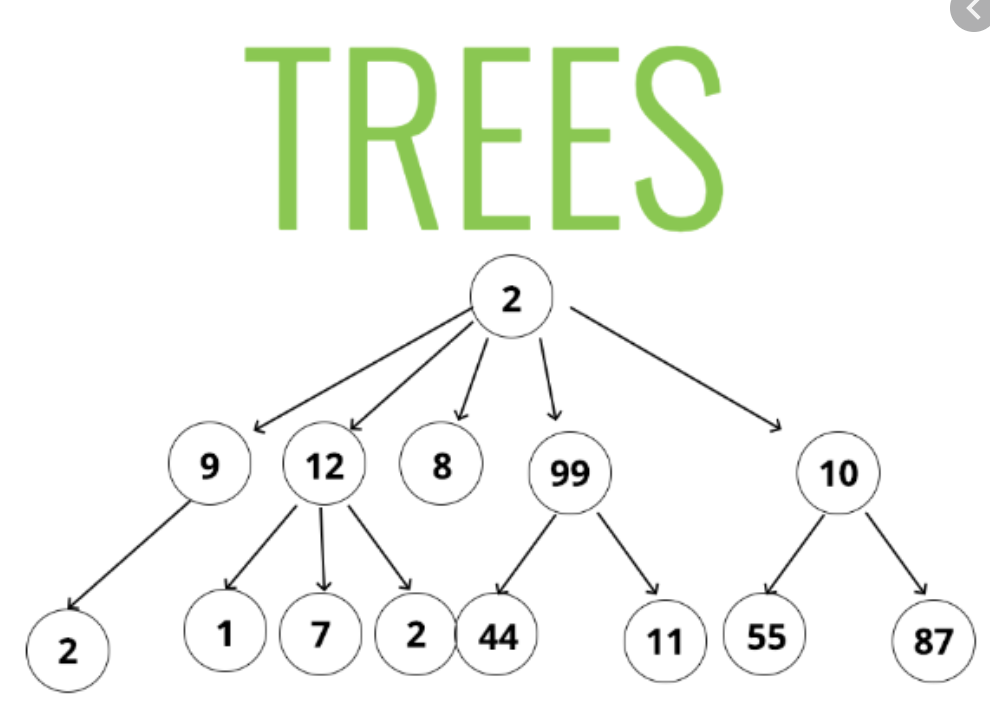
A tree is a hierarchical structure where data is organized hierarchically and are connected together. This structure is different from a linked list whereas, in a linked list, items are linked in a linear order.
A tree contains “nodes” (a node has a value associated with it) and each node is connected by a line called an “edge”. These lines represent the relationship between the nodes.
The top-level node is known as the “root” and a node with no children is a “leaf”. If a node is connected to other nodes, then the preceding node is referred to as the “parent”, and nodes following it are “child” nodes.
There are various incarnations of the basic tree structure, each with their own unique characteristics and performance considerations:
- Binary Tree
- Binary Search Tree
- Red-Black Tree
- B-tree
- Weight-balanced Tree
- Heap
- Abstract Syntax Tree
Tree’s Application Examples
- Used to implement database indexes (index is a structure that exists independent of the data in the database which improves the query optimizers’ ability to execute the query quickly. In other words, an index is something we create for a column in a table to speed up searches involving that column)
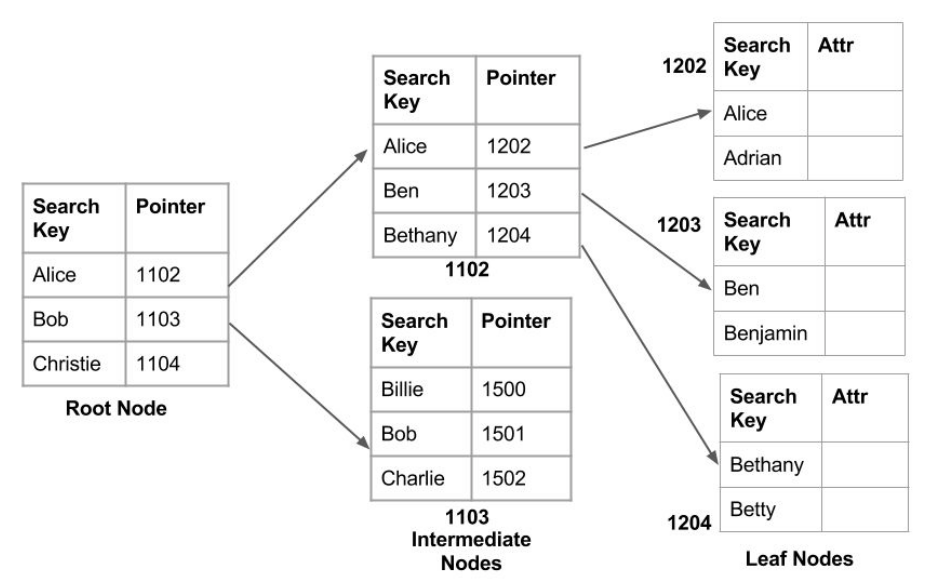
- Heaps data structure: is used by JVM (Java Virtual Machine) to store Java objects.
- Treap data structure: is used in wireless networking.
Published at DZone with permission of Huyen Pham. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments