Database Operations on Cassandra and Oracle Using Apache Spark
The rapid growth of data sources and data volumes has made it difficult to process for collected data. Spark and Cassandra together can help.
Join the DZone community and get the full member experience.
Join For FreeIn this article, I will be doing operations that write and read to Cassandra database using Spark. I hope there will be a useful article in terms of awareness.
The rapid growth of data sources and data volumes has made it difficult to process for collected data. However, the need to process the data has increased. Following these needs and challenges, various solutions have been produced for rapid analysis and storage of big data. Spark is one of the common solutions used to process big data. Cassandra is one of the most widely used databases for storing and questioning big data. Now, we will try to use these two current technologies together.
First of all, I would like to give you an information about the software that I use to make this example.
OS: SUSE
Spark: 2.1.0
Oracle database: Oracle 11g R2
Cassandra: 3.4
Hadoop: 2.7
First, let's connect to the Oracle database with Spark and read a sample data and write it to HDFS. In order to do this, we need the ojdbc6.jar file in our system. You can use this link to download it.
Let's create the table in Oracle database and put the sample data into it.
CREATE TABLE EMP
(
EMPNO NUMBER,
ENAME VARCHAR (10),
JOB VARCHAR (9),
MGR NUMBER,
SAL NUMBER,
COMM NUMBER,
DEPTNO NUMBER
);
INSERT INTO EMP VALUES
(7369, 'SMITH', 'CLERK', 7902, 800, 50, 20);
INSERT INTO EMP VALUES
(7499, 'ALLEN', 'SALESMAN', 7698, 1600, 300, 30);
INSERT INTO EMP VALUES
(7521, 'WARD', 'SALESMAN', 7698, 1250, 500, 30);
INSERT INTO EMP VALUES
(7566, 'JONES', 'MANAGER', 7839, 2975, NULL, 20);
INSERT INTO EMP VALUES
(7654, 'MARTIN', 'SALESMAN', 7698, 1250, 1400, 30);
INSERT INTO EMP VALUES
(7698, 'BLAKE', 'MANAGER', 7839, 2850, NULL, 30);
INSERT INTO EMP VALUES
(7782, 'CLARK', 'MANAGER', 7839, 2450, NULL, 10);
INSERT INTO EMP VALUES
(7788, 'SCOTT', 'ANALYST', 7566, 3000, NULL, 20);
INSERT INTO EMP VALUES
(7839, 'KING', 'PRESIDENT', NULL, 5000, NULL, 10);
INSERT INTO EMP VALUES
(7844, 'TURNER', 'SALESMAN', 7698, 1500, 0, 30);
INSERT INTO EMP VALUES
(7876, 'ADAMS', 'CLERK', 7788, 1100, NULL, 20);
INSERT INTO EMP VALUES
(7900, 'JAMES', 'CLERK', 7698, 950, NULL, 30);
INSERT INTO EMP VALUES
(7902, 'FORD', 'ANALYST', 7566, 3000, NULL, 20);
INSERT INTO EMP VALUES
(7934, 'MILLER', 'CLERK', 7782, 1300, NULL, 10);
COMMIT;Now, we are launching Apache Spark from the Linux terminal with the Pyspark interface (Python interface).
/spark-2.1.0-bin-hadoop2.7/bin/pyspark
--jars "/home/jars/ojdbc6.jar"
--master yarn-client
--num-executors 10
--driver-memory 16g
--executor-memory 8g
Yes, we started Apache Spark. Now, let's write and run the Python code we will read from the database. and write it to HDFS.
empDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:oracle:thin:username/password@//hostname:portnumber/SID") \
.option("dbtable", "hr.emp") \
.option("user", "db_user_name") \
.option("password", "password") \
.option("driver", "oracle.jdbc.driver.OracleDriver") \
.load()
empDF.show()
empDF.select('EMPNO','ENAME','JOB','MGR','SAL','COMM','DEPTNO').write.format('com.databricks.spark.csv').save('/employees/')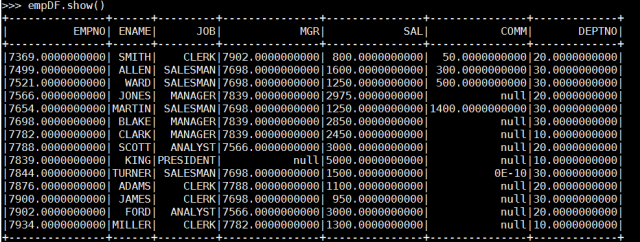 Yes, we read the data with Spark from Oracle and wrote to hdfs. Now, let's create a table in Cassandra where we will store this data in the Cassandra database.
Yes, we read the data with Spark from Oracle and wrote to hdfs. Now, let's create a table in Cassandra where we will store this data in the Cassandra database.
CREATE TABLE emp(
empno int,
ename text,
job text,
mgr text,
sal text,
comm text,
deptno text,
primary key(empno)
);Now let's start a new pyspark and read the data that we wrote to hdfs and write it to the cassandra database. But before we do this, we need some .jar files to connect to the cassandra database. After downloading these .jar files, we are launching pyspark using these jar files.
spark-cassandra-connector-2.4.0-s_2.11.jar
jsr166e-1.1.0.jar
pyspark-cassandra-0.8.0.jar
/spark-2.1.0-bin-hadoop2.7/bin/pyspark \
--jars /jar_s/spark-cassandra-connector-2.4.0-s_2.11.jar,/jar_s/jsr166e-1.1.0.jar\
--py-files /jar_s/pyspark-cassandra-0.8.0.jar \
--conf spark.cassandra.connection.host= CASSANDRA_IP_ADDRESSfrom pyspark import SparkContext, SparkConf
from pyspark.sql import SQLContext
from pyspark.sql import Row
from pyspark.sql import HiveContext
from pyspark.sql.functions import *
hive_context = HiveContext(sc)
sqlContext = SQLContext(sc)
RecEmp = Row('empno','ename','job','mgr','sal','comm','deptno')
dataEmp = sc.textFile("/employees/")
recEmp = dataEmp.map(lambda l: l.split(","))
dataEmp = recEmp.map(lambda l: RecEmp(float(l[0]),l[1],l[2],(l[3]),(l[4]),(l[5]),(l[6])))
dfEmp = hive_context.createDataFrame(dataEmp)
dfEmp.registerTempTable("emp")
spark = SparkSession.builder \
.appName('SparkCassandraApp') \
.config('spark.cassandra.connection.host', 'CASSANDRA_IP_ADDRESS') \
.config('spark.cassandra.connection.port', 'CASSANDRA_PORT') \
.config('spark.cassandra.auth.username','CASSANDRA_USER') \
.config('spark.cassandra.auth.password','CASSANDRA_PASS') \
.master('local[2]') \
.getOrCreate()
dfEmp.write\
.format("org.apache.spark.sql.cassandra")\
.mode('append')\
.options(table="emp", keyspace="test")\
.save()-- cassandra database
select * from emp; We saw that the data was written successfully. Now, we read the data that we wrote on Cassandra with Spark. Let's show on console with Pyspark.
We saw that the data was written successfully. Now, we read the data that we wrote on Cassandra with Spark. Let's show on console with Pyspark.
ds = sqlContext \
.read \
.format('org.apache.spark.sql.cassandra') \
.options(table='emp', keyspace='test') \
.load()
ds.show()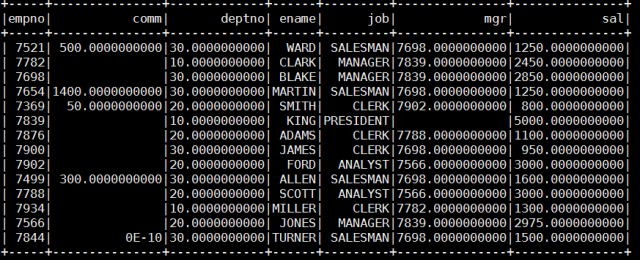
Opinions expressed by DZone contributors are their own.
Comments