Delta Sharing vs Traditional Data Exchange: Secure Collaboration at Scale
Share live Delta tables with external partners securely and at scale — no data copies needed — fully governed and audited via Unity Catalog.
Join the DZone community and get the full member experience.
Join For FreeSharing large datasets securely with external partners is a major challenge in modern data engineering. Legacy methods such as transferring files via SFTP or HTTP and building custom APIs often create brittle pipelines that are hard to scale and govern. Many organizations have historically used on-prem or cloud SFTP servers or custom REST endpoints to exchange CSV/Parquet files. These approaches work in a pinch but require copying or exporting data, scheduling processes and managing credentials. As Databricks observes, homegrown SFTP and API solutions have become difficult to manage, maintain or scale. Traditional data warehouses add another option but that typically locks you into one vendor and incurs extra licensing and data copy overhead.
In contrast, Databricks Delta Sharing is a new open protocol designed for secure, real-time data sharing across organizations and platforms. The core idea is simple data providers register a share of live Delta tables and recipients connect directly to query that data in place. No ETL or manual file export is needed. A built-in Delta Sharing server handles authentication, governance and data serving. The Delta Sharing API is a lightweight REST service effectively a simple REST protocol that supports sharing live data in a Delta Lake between providers and recipients.
Traditional Data Exchange Methods
File-Based Sharing (SFTP, Cloud Storage)
Historically, providers often upload batch files to an SFTP server or shared cloud bucket and partners download them. This is vendor-agnostic but mostly manual. For example, Spark can ingest from SFTP using Auto Loader:
df = (spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "csv")
.load("sftp://user@host:22/path/to/files"))
df.show()While this can bring data into a lakehouse, it is inherently batch-oriented. Files must be produced ingested via separate jobs and access is coarse. Such setups lack integrated governance and often become bottlenecks as volumes and partner counts grow.
API/Service Endpoints
Some teams build REST or gRPC APIs to serve data. Clients make authenticated HTTP requests to fetch data on demand. For example:
import requests
res = requests.get("https://api.partner.com/data?date=2023-01-01")
data = res.json()APIs offer more flexible filtering and can be real-time, but they require substantial engineering. Building an API layer for bulk data means handling authentication, pagination, rate limits and schema evolution. Many existing APIs are tuned for point lookups or analytics rather than large-scale table scans.
Like SFTP, APIs often end up duplicating infrastructure and do not scale easily to thousands of large-table queries without sophisticated caching and infrastructure. Databricks notes that legacy API-based sharing often becomes unmanageable at scale.
Database/Warehouse Replication
Another model is to copy shared data into a partner’s own database or data warehouse. For example, an engineer might write a DataFrame into a shared Snowflake or PostgreSQL table:
df.write \
.format("jdbc") \
.option("url", "jdbc:postgresql://db-host:5432/mydb") \
.option("dbtable", "shared.sales") \
.option("user", "user") \
.option("password", "pass") \
.mode("overwrite") \
.save()Each of these traditional methods trades off real-time freshness, ease of integration and governance. Providers must constantly monitor jobs, rotate credentials and coordinate with partners. As a result, sharing data externally tends to be slow, manual and expensive.
Databricks Delta Sharing Overview
Databricks Delta Sharing was created to overcome these limitations. In Databrick's words, it is the world’s first open protocol for secure and scalable real-time data sharing. It is open and platform agnostic any client that implements the Delta Sharing API can read the data, whether it’s a Spark cluster, a Pandas script, Power BI or even a custom tool. Users on any cloud or on-prem Spark cluster can participate.
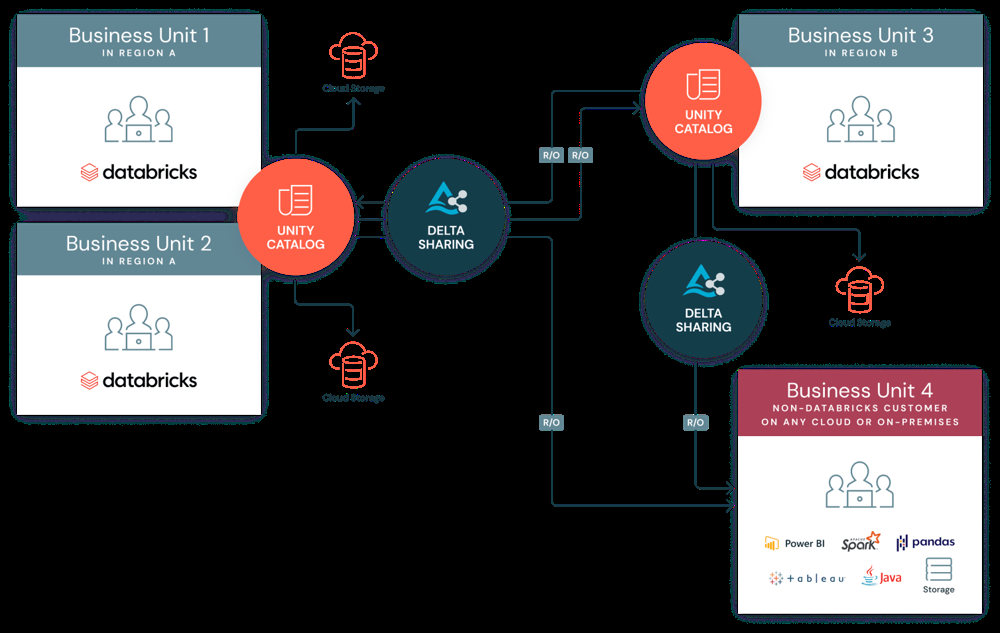
In practice, a data provider creates a share object in Unity Catalog that includes one or more tables to share with one or more recipients. Internally this is a pointer to the Delta Lake files on cloud storage. The provider then registers recipients either other Databricks accounts or external users using tokens or OAuth. Because Unity Catalog underpins the share, all typical governance policies still apply.
In PySpark one might do:
df = (spark.read.format("deltasharing")
.option("sharingCredentialsFile", "/path/to/credentials.json")
.load("finance_share.saleschema.transactions"))
df.show()Here, credentials.json is a small JSON file containing the Delta Sharing endpoint URL and an access token. The .load() call uses the syntax <share-name>.<schema-name>.<table-name> to identify the table. The Delta Sharing connector then sends the query to the provider’s sharing server, which validates the token and returns query results from the live Delta table. There is no intermediate storage of the data the provider’s files are read directly as needed.
Because the data is accessed live, partners always see the most recent updates. Providers can update the underlying Delta tables and recipients will automatically see those changes on their next query. Delta Sharing also supports advanced features like Structured Streaming and Change Data Feed if enabled on the source table. Delta Sharing turns every shared table into a live, governed endpoint.
Benefits: Secure, Scalable Collaboration
Compared to traditional exchange, Delta Sharing brings several engineering advantages:
- Live, up-to-date data: There is no need to dump and sync files or refresh warehouse copies. Recipients query the provider’s tables in real-time. As Databricks notes, providers can share large datasets in a seamless manner and overcome SFTP scalability issues. Downstream users no longer wait hours or days for new files they always get current data.
- Platform and cloud neutral: Because Delta Sharing is an open protocol, partners can use any compatible client on any cloud. There’s no requirement for the same vendor on both ends.
- Built-in security and governance: Shares are managed via Unity Catalog, so providers retain full control. They can grant or revoke access at any time and even apply row-level or column-level filters per recipient. Unity Catalog also audits usage, giving both parties visibility into who queried what. Traditional file drops or APIs lack this centralized audit trail. Delta Sharing provides granting, tracking and auditing of shared data from a centralized place with expiration policies and revocation built in.
- Lower operational overhead: Setting up a share is largely declarative. Databricks handles the heavy lifting of serving the data. There are no custom ingestion jobs to maintain no data duplication to manage and no manual credential handoffs. Providers simply pay normal egress data transfer fees when recipients read the data. This can be much cheaper and simpler than provisioning extra compute or storage for every partner. One Databricks customer found that switching from nightly SFTP exports to Delta Sharing minimizes the cost, as the data provider only incurs data egress cost and does not have to pay for any compute charges.
- Scale to many recipients: Delta Sharing is designed to handle thousands of shares and recipients at scale. Because the data itself is not copied for each recipient, adding more consumers has minimal impact on the provider. This contrasts with pushing data out individually which multiplies work and cost.
Overall, Delta Sharing turns the traditionally heavy problem of external data exchange into a self-serve, secure pipeline. Partners can use familiar SQL or DataFrame queries to access shared tables and providers can centrally manage everything via Unity Catalog. Delta Sharing enables sharing real-time/batch data without replication and treats data as live tables rather than static files.
Example Code
Below is a simplified example illustrating the two sides of Delta Sharing in Databricks SQL. A data provider creates a share and adds a table:
-- As the data provider (Databricks Unity Catalog SQL):
CREATE SHARE IF NOT EXISTS sales_share COMMENT 'Partner Sales Data';
ALTER SHARE sales_share ADD TABLE main_catalog.public.orders;Once this is done, any authorized recipient can query the orders table. For a Databricks-to-Databricks share, the provider would also GRANT SELECT ON SHARE sales_share TO RECIPIENT partner_acct for open sharing, the provider instead gives the recipient a token credential file.
On the recipient side, you read from the share like this:
# As the recipient (any Spark with Delta Sharing connector):
df = (spark.read.format("deltasharing")
.option("sharingCredentialsFile", "/tmp/sales_credentials.json")
.load("sales_share.public.orders"))
df.select("order_id", "amount", "date").show()Here, sharingCredentialsFile is a small JSON file supplied by the provider. The .load("sales_share.public.orders") call then pulls the live orders table from the provider’s lake. Notice we did not copy any data or configure a JDBC connection the Delta Sharing connector handles the rest.
Conclusion
Delta Sharing represents a modern approach to cross organization data exchange. By treating shared tables as live data endpoints and using open-standard APIs, it removes many of the friction points of traditional sharing.
For data engineers, this means setting up fewer custom jobs and enjoying real-time access and fine-grained governance. As illustrated, Delta Sharing can replace bulky SFTP/ETL setups and expensive warehouse copies with a secure, cloud-agnostic sharing mechanism. In doing so, it enables scalable, secure data collaboration partners can access the data they need with minimal overhead and providers keep control with strong governance.
Opinions expressed by DZone contributors are their own.
Comments