Deploying Real-Time Machine Learning Models in Serverless Architectures: Balancing Latency, Cost, and Performance
Learn how to deploy real-time machine learning models in serverless environments while balancing latency, cost, and performance challenges.
Join the DZone community and get the full member experience.
Join For FreeMachine learning (ML) is becoming more and more important in real-time applications such as fraud detection and personalized recommendations. Due to their scaling capacity and the elimination of workload on infrastructure management, these applications are highly attractive for deployment in serverless computing.
However, deploying ML models to serverless environments has unique challenges with latency, cost, and performance. In this article, we will describe these problems and provide a solution that makes it possible to successfully deploy real-time ML models into the serverless architecture.
Understanding the Serverless Challenge for Real-Time ML
Serverless computing, like AWS Lambda, Google Cloud Functions, and Azure Functions, allows developers to build applications without the need to manage the servers. Given its scaling flexibility and cost, these platforms are well matched to satisfy traffic that rarely has the same characteristics at times. Real-time machine learning model needs to be carefully balanced with low latency inference, cost control, and optimal usage of resources.
One of the biggest advantages of the serverless framework is its scalability, but this comes at a cost of unpredictable cold start, resource limitation, and cost overruns. It is important to consider how to address these challenges for real-time ML, where every hour and every penny counts.
1. Cold Starts: Impact on Latency
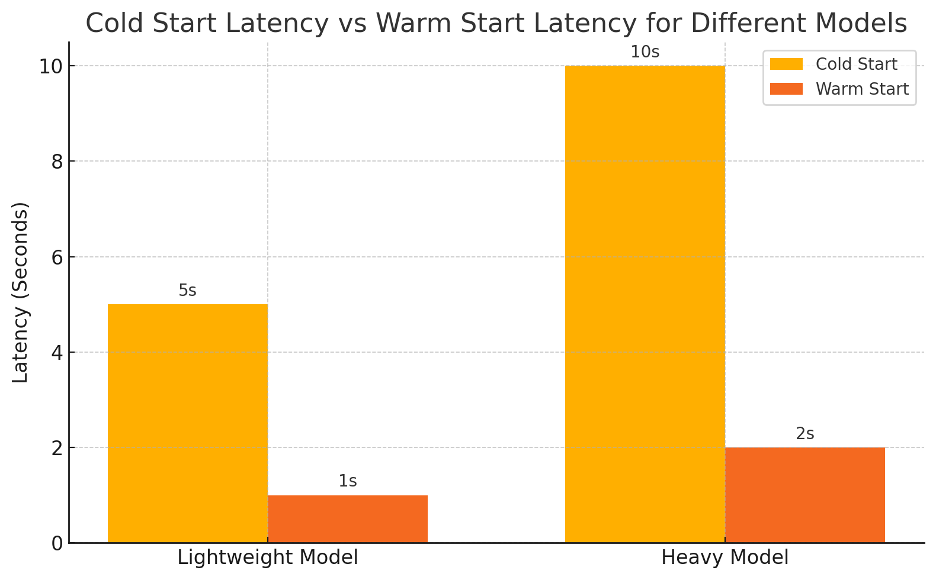
In serverless computing, cold starts are a big challenge. The platform has to initialize the serverless function environment when it has not been called recently, so it introduces a delay. Cold start time is the fastest time needed for machine learning models to be initialized, depending on how difficult it is to load large models or dependencies. This can be problematic in real-time applications in the context of low latency.
For example, AWS Lambda can add latency up to 10 seconds for large models as they warm up. However, this can be severely detrimental to real-time systems like fraud detection, where every millisecond counts.
Provisioned Concurrency on AWS Lambda lets you keep a fixed number of function instances warm to mitigate cold starts, significantly reducing cold start time. That is, however, at the expense of latency, and developers will need to consider the tradeoff between latency and the extra cost.
2. Managing Cost: Efficient Use of Resources
Serverless functions are billed per use, and are extremely beneficial to applications with inconsistent traffic patterns. Rapidly rising costs are incurred by the execution of compute-intensive machine learning models, in particular, deep learning models. Using system resources for each of the single model invocations until they are largely used in real-time applications results in increased operational costs.
A deep learning model needs heavy CPU and memory to process every request that pours into it. Businesses have to put a lot of emphasis on optimizing the model run on serverless functions because of the high costs.
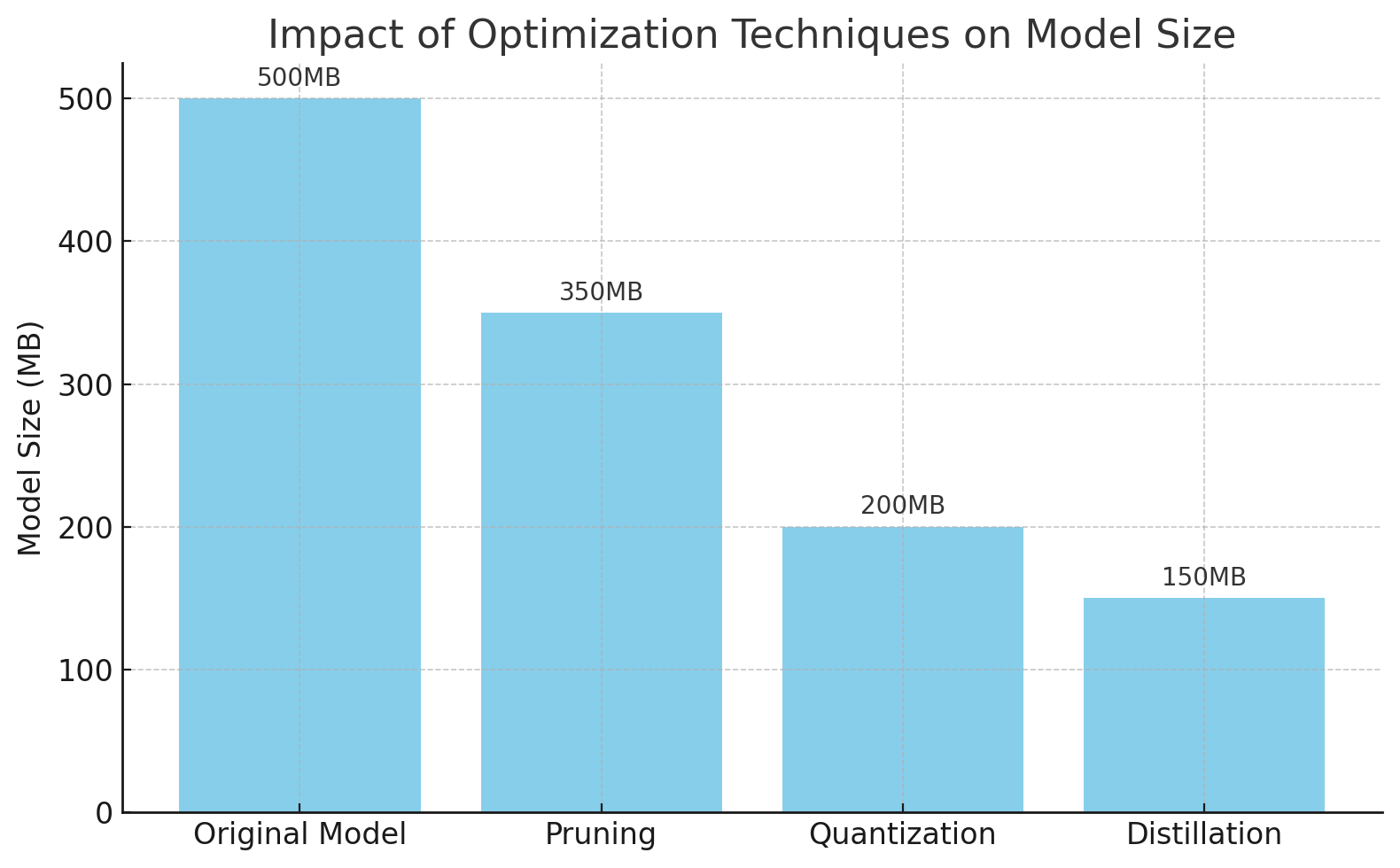
Optimization of models is a fundamental approach to reducing operational expenses. Model pruning with quantization technologies and distillation methods is introduced to reduce the size of models while maintaining accuracy performance. This allows for quicker and less expensive performance of inferences.
By allowing administrators to combine several requests into one execution, the batch processing process decreases the number of serverless function calls. The processing is reshaped because batching executes a single function execution for multiple requests, thus reducing the operational costs and overhead expenses.
3. Performance: Resource Constraints and Scalability
Serverless functions work on a stateless approach, while ML models require stateful execution along with promising resources to run working models. In case of real-time ML on a serverless platform, it is critical to allocate sufficient resources to handle the inference workload to ensure no delays and no timeouts.
The performance of large models deployed to undefined computing environments might be limited. As deep learning inference usually involves GPUs as hardware, we cannot easily access GPUs directly on most serverless platforms, and indeed, the majority of them prevent direct GPU access.
Machine learning models that will be deployed in serverless environments must be minimized and enhanced. MobileNet or equivalent models can be served in deployment, and businesses could save memory space and speed up the processes with exactly the same top-level accuracy performance. Despite the constraint of resource availability, these models are the most suitable ones for serverless operations due to their mobile and edge device optimisation.
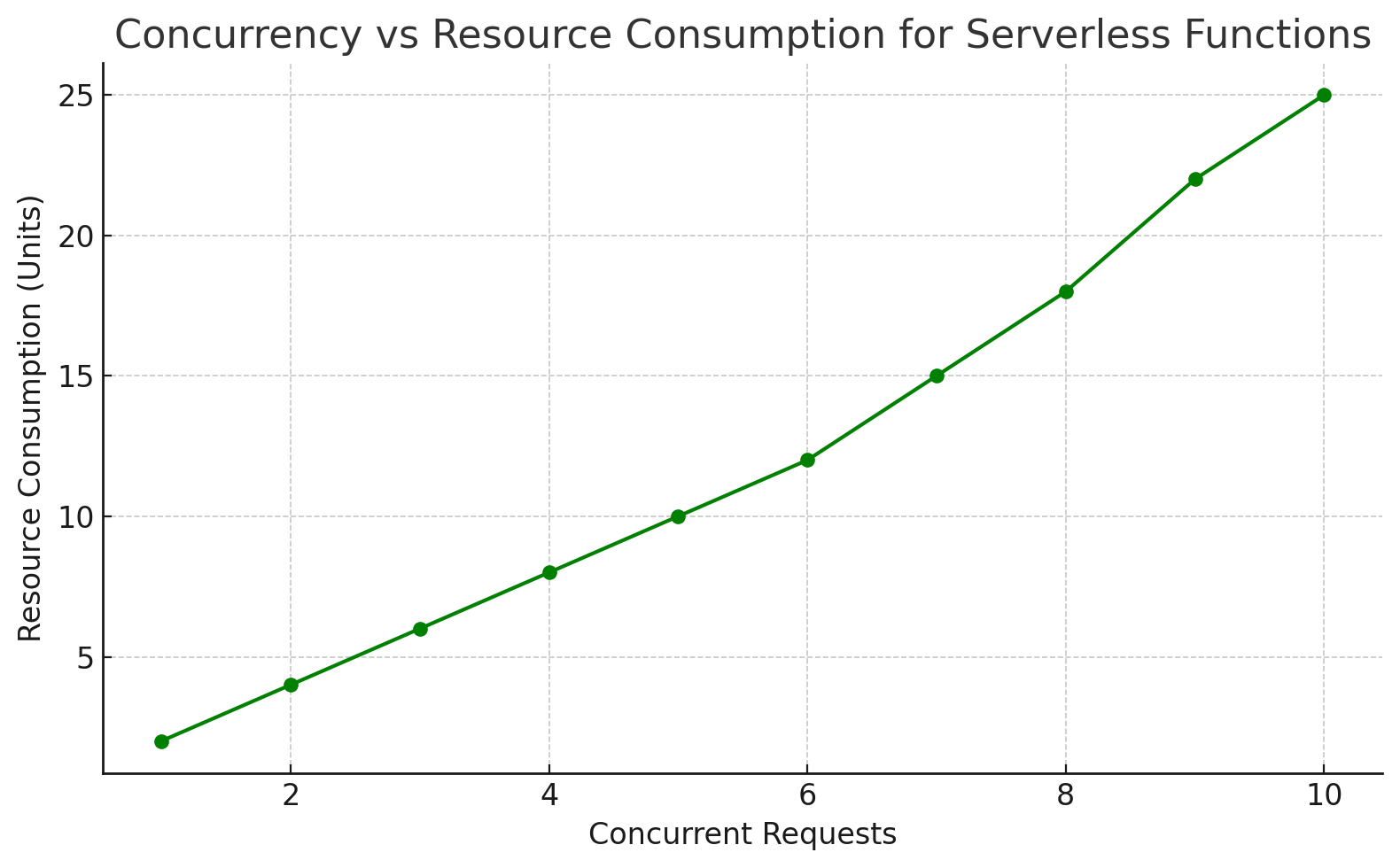
Concurrent processes depend on the management, and it's an essential aspect of development. When an unexpected surge happens to the function invocation activity in serverless environments, resource competition would occur with the auto-scaling feature of serverless environments. Acquisition of enough running executions, along with appropriate configuration modification, lets developers keep the smooth functionality under high demand.
Best Practices for Real-Time ML Deployments in Serverless Architectures
There are various considerations when deploying real-time ML models in serverless environments. To make a successful deployment, however, you'll want to follow these best practices:
- Reduce model complexity: Prune, quantize, and distill your ML models to optimize them. By using lighter models such as MobileNet or TinyBERT, real-time inference tasks can be effectively handled with good accuracy.
- Lower cold start latency: Warm up functions or use provisioned concurrency to minimize cold start latency. To reduce initialization overhead, alternative solutions like containerized ones can be considered.
- Cost efficiency via batch processing: Instead of running each request with an invocation of a serverless function, shove them all together. It will reduce the number of invocations and, by extension, your total costs.
- Monitor and manage shared resources: Monitor and control serverless function concurrency so that serverless functions are not interrupted or overset and the results are not poor.
- Low latency applications: Use edge devices to offload inference tasks for closer computing and scalability in case of cloud dependency.
Conclusion
By giving developers access to tools that make it possible to deploy machine learning models at a large scale, serverless architectures allow us to work with effective tools. Serverless architecture platforms also pose special obstacles when it comes to deploying real-time ML models, as performance and pragmatic cost effectiveness have to meet the latency. By using appropriate control policies such as optimization techniques coupled with cold start management, resource management, and concurrency operation, developers can construct efficient real-time ML systems running in a serverless environment.
Opinions expressed by DZone contributors are their own.
Comments