Designing Fault-Tolerant Microservices With Toxiproxy and Cucumber
Find out how!
Join the DZone community and get the full member experience.
Join For Free
You may also like: Making Your Microservices Resilient and Fault Tolerant
Thinking About Fault Tolerance From Day 0
Fault tolerance — alongside with security and other traits - is hard to factor-in after the service is already built. It's created by making careful design decisions starting at the same time your service was born.
"What happens when the database isn't there? What happens if all connections time out?"
These are all valid questions and you better prepare for these situations before your service goes live!
About Toxiproxy
Toxiproxy is a cool programmable proxy made by Shopify for testing purposes. We're going to use it to predefine network characteristics in our test scenarios. These scenarios are responsible for describing the failure modes of the service.
Why Cucumber?
Failure modes are hard to understand but still, take a significant part in our service lifecycle. Usually, you can only understand failure modes of a specific service by looking at the source code. These implementations are typically low level so it's even harder to understand them by solely relying on code reading. It's better to use a living documentation to understand the service's failure modes, so the team can maintain and support the service at-ease. Also, it gives more opportunity for experimenting after the step definition implementations are settled.
What Are We Going to Build?
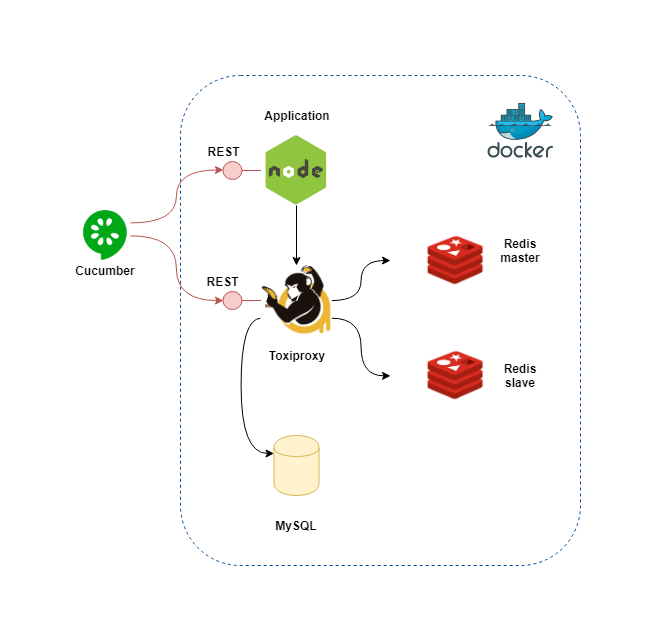
The diagram shows an overview of the container connections in the example's docker compose file. The application connects to a cache cluster and a database instance provided by Redis master/slave and MySQL. It's doing it indirectly through Toxiproxy, which offers a REST API for controlling the network characteristics. Tests will be able to change the network connectivity between the application and each one of its dependency separately. Cucumber gives the test scenarios a nice readable format and allows declaring our application's failure modes in feature files.
How to Run the Example?
Go to the GitHub example and see the README.md on how to start the service along with all the dependencies. It also contains the commands for running the Cucumber tests.
Look at Before, BeforeAll, AfterAll implementations to better understand how step definitions are communicating with the Toxpiproxy API.
I'm going to present an imaginary development process, like the one I went through when doing the exercises by myself. Readers can go through the article and review the example codebase to get a taste of how the development process would look like.
When Things Go Down
The first thing that we will implement is the case of not being able to reach the database.
Feature: ...
...
Background:
Given user 'u-12345abde234' with name 'Jack' is cached
And user 'u-12345abde234' with name 'Jack' is stored
Scenario: Read-only mode without MySQL
Given 'MySQL' is down
When user 'u-12345abde234' is requested
Then the user with id 'u-12345abde234' is returned from 'Redis'Shortly after executing the test we'll realize that our application simply crashes when MySQL is gone. Failing fast is definitely a good thing when it's intentional. What if we just want to send back the data humbly when it's available from the cache?
Seems like it's relatively easy to fix application crashes. We just need to modify our code to use connection pools.
function connect({host, port, user, password}, callback) {
const pool = mysql.createPool({
host: host,
port: port,
user: user,
password: password
});
callback(null, pool);
}In the next step, we're adding two more scenarios, which ensures that write issues are handled correctly and the application is able to recover after the database is back online.
Feature: ...
...
Scenario: Write not allowed without MySQL
Given 'MySQL' is down
When new user created with id 'u-1123' and name 'Joe'
Then HTTP 503 is returned
Scenario: Write is restored with MySQL
Given 'MySQL' is down
When 'MySQL' is up
And new user created with id 'u-1123' and name 'Joe'
And user 'u-1123' is requested
Then the user with id 'u-1123' is returned from 'MySQL'The second scenario passes without code change because the database driver is doing the work for us. We just need to ensure that write errors are handled correctly and we're also able to pass the first scenario.
app.put('/users/:userId', function (req, res) {
...
dao.saveUser(app.daoConnection, user, (err) => {
if (err) {
console.error("MySQL error, when saving user - ", err);
return res.sendStatus(503);
}
...
});
});Caching Issues
Now, let's define scenarios for the failure modes related to caching. What should happen if the Redis master is unavailable? Until we have a Redis slave running we should still use it for returning cached results.
Feature: Cache availability scenarios for user service
User service should survive all possible failure scenarios
Background:
Given user 'u-12345abde234' with name 'Jack' is cached
And user 'u-12345abde234' with name 'Jack' is stored
Scenario: Cache read-only mode without Redis master
Given 'redis-master' is down
When user 'u-12345abde234' is requested
Then the user with id 'u-12345abde234' is returned from 'Redis'This is the point when things become interesting. If we intend to run Redis in a simple master/slave mode — without using sentinels or a cluster with shards — it's impossible to failover to the read-only slaves with the traditional Node JS driver. I had to look for a smarter client and finally ended up using thunk-redis. Fortunately, the two APIs are almost identical and I have the option to define both the master and the slave IP addresses during connection initialization. You can see the list of clients for all programming languages in the official website.
function connect({
hosts, ...
}, callback) {
const client = redis.createClient(hosts, {onlyMaster: false});
...
client.on("error", function (err) {
console.error("Redis error caught on callback - ", err);
});
client.on("warn", function (err) {
console.warn("Redis warning caught on callback - ", err);
});
...
callback(null, client);
}{
"default": {
"config_id": "default",
...
"redis": {
"hosts": ["192.168.99.106:6379", "192.168.99.106:16379"],
...
},
...
}
}How should we handle any error with cache writes? The next step is to carve out two more scenarios for these use cases.
Feature: Cache availability scenarios for user service
...
Background:
Given user 'u-12345abde234' with name 'Jack' is cached
And user 'u-12345abde234' with name 'Jack' is stored
...
Scenario: Write cache fails without Redis master
Given 'redis-master' is down
When user is updated with id 'u-12345abde234' and name 'Joe'
And user 'u-12345abde234' is requested
Then the user with id 'u-12345abde234' and name 'Jack' is returned from 'Redis'
...The first scenario is expressing that the application should return stale results from the read-only cache after write failure. Be aware that this might be unacceptable in your case. Even though writing the cache fails, writes should still reach the database. This means that after cache eviction we must get back the up-to-date user from MySQL.
The next scenario is dealing with the case when Redis master gets back to business.
Feature: ...
...
Scenario: Write cache connection is restored after Redis master is up
Given 'redis-master' is down
And 'redis-master' is up
When user is updated with id 'u-12345abde234' and name 'Joe'
And user 'u-12345abde234' is requested
Then the user with id 'u-12345abde234' and name 'Joe' is returned from 'Redis'
...Let's start implementing this in our application. The good news is, that thunk-redis connects to the slave automatically when the master is not available. Unfortunately, it's not the case when the master becomes available again. The driver will send the READONLY error code every time when write failed to the slave node. It won't automatically reconnect to master. We have to detect these failures and initiate the reconnection. This is how it looks.
function reconnectOnReadOnlyError(client, err) {
if (!err.code || err.code !== 'READONLY') {
return;
}
setTimeout(() => {
reconnect(client);
}, client.reconnectToMasterMs);
console.debug("Reconnecting to master after %d ms", client.reconnectToMasterMs);
}
...
function storeUser(client, user) {
client.hmset(user.id, 'id', user.id, 'name', user.name)(err => {
if (err) {
console.error("Storing user in REDIS failed", err);
reconnectOnReadOnlyError(client, err);
}
});
}
...
function evictUser(client, userId) {
client.del(userId)(err => {
if (err) {
console.error("Deleting user in REDIS failed", err);
reconnectOnReadOnlyError(client, err);
}
});
}Have you noticed the issue in the code above? We tightly coupled the detection of read-only mode with the cache API calls. What's the problem with that? If there's no traffic, the failure won't be detected and recovery won't be initiated. Even the amount of retries are depending on the calls that are trying to write to the cache (just a small hint: one reconnection attempt is often not enough).
Is our application able to pass the newly written scenario? Unfortunately, not on the first attempt. The application needs to detect multiple failed operations and requires some time to recover. I had to rewrite this scenario several times. After all the effort it still looks ugly and its format may hurt your eyes:
Feature: ...
...
@fragile
Scenario: Write cache connection is restored after Redis master is up
...
Given 'redis-master' is up
And we wait a bit
When user is updated with id 'u-12345abde234' and name 'Joe'
And we wait a bit
When user is updated with id 'u-12345abde234' and name 'Joe'
And user 'u-12345abde234' is requested
# Should be cached now
And user 'u-12345abde234' is requested
Then the user with id 'u-12345abde234' and name 'Joe' is returned from 'Redis'
...Yikes! This is the point where we need to rethink what we're doing. The description of the failure modes should be easy to consume for a human. I will leave it to the readers to fix the test case and the application (probably I will do it also in an upcoming article). Here are a few guidelines on how it can be done:
- Failure detection should be done periodically, similar to how timeout detection is implemented in the next section.
- The scenario should have a defined interval, in which we're expecting the correct result to arrive.
For now, I'll exclude this scenario with the @fragile annotation. I think it's a good practice overall to separate fragile tests. You can choose not to break the build, but still, generate a test report if one of these fails until the team comes up with a stable solution.
The scenario above can be run with cucumber-js —tags @fragile.
Timeouts
We've got plenty of scenarios working with one type of toxic. It's time to experiment with other ones as well. Let's look at some failures when a timeout occurs.
Feature: Cache availability scenarios for user service
...
Scenario: Redis master/slave time out
Given 'redis-master' times out
And 'redis-slave' times out
When user 'u-12345abde234' is requested
Then the user with id 'u-12345abde234' is returned from 'MySQL'Unfortunately, this is the point where flaws of thunk-redis implementation is bubbling to the surface. Our application is waiting forever until finally giving up and denying every request towards our Redis connections. I had to introduce a decent connection validation logic to be able to deal with timeouts effectively. In brief, this is what every client library ought to do to ensure that all the connections represented inside are ready to receive requests:
- Add a timeout interval as an extra parameter for every blocking call.
- Check periodically if the established connection is still alive.
Let's start with introducing a wrapper method which allows a timeout interval parameter:
...
function callWithTimeout(method, timeout, callback) {
let timeoutTriggered = false;
const afterTimeout = setTimeout(() => {
timeoutTriggered = true;
callback(new Error(`Execution timed out after ${timeout}ms`));
}, timeout);
method((...args) => {
clearTimeout(afterTimeout);
// We avoid sending callbacks multiple times.
if (!timeoutTriggered) {
return callback(...args);
}
});
}
...The good news is that JavaScript allows us to define a generic method to wrap any kind of function. That's the method I'm going to use to implement our connection validation logic for Redis connections:
function reconnect(client) {
client.clientEnd();
client.clientConnect();
}
...
function initiateScheduledPing(client) {
setInterval(() => {
callWithTimeout(client.ping(), client.pingTimeoutMs, (err) => {
if (err) {
console.error("Ping failed, reconnecting:", err);
reconnect(client);
}
});
}, client.pingIntervalMs);
}Notice, that client.ping() is just a "factory method" passing the function to callWithTimeout . That's a special dialect coming from thunk-redis .
Initiating Redis connections will pass configuration parameters and kick-off the validation of the pool:
function connect(
{
...
pingIntervalMs,
pingTimeoutMs,
...
},
callback) {
...
client.pingIntervalMs = pingIntervalMs;
client.pingTimeoutMs = pingTimeoutMs;
...
initiateScheduledPing(client);
...
}Every call to thunk-redis should be wrapped with callWithTimeout, so this is how to get a user with a predefined timeout interval:
function getUser(client, userId, callback) {
callWithTimeout(client.hgetall(userId), client.callTimeoutMs, callback);
}After implementing all these not-so-straightforward library extensions, finally, our scenario will pass.
Conclusion
Why Can't I Just Use Integration Tests and Mocks?
Drives are a black box. They contain a lot of surprises you wouldn't expect. Creating a programmable mock involves a lot of assumptions on how the driver is going to behave. The approach above gives you space for a lot of exploration. It's required to fully understand your driver's limitations on handling connection failures.
What's With Toxiproxy-Node-Client?
Unfortunately using toxiproxy-node-client didn't end up very well, so I decided to implement my own client calls in Before, BeforeAll, AfterAll.
Why Don't We Use Circuit Breakers?
Good point! I plan to continue in another article showing how the issues above can be solved with them.
Drawbacks
- Services can only recover after a certain period. That period can be different in each environment. This needs careful fine-tuning of all timeout and grace period related configurations.
- It's not a good idea to connect failure detection with some kind of action if your traffic doesn't have stable characteristics. For instance, detecting write failures should not be tightly bound to write attempts unless there's decent traffic of related requests.
Further Reading
Microservices Architectures: What Is Fault Tolerance?
Opinions expressed by DZone contributors are their own.
Comments