DevoxxGenie: Your AI Assistant for IntelliJ IDEA
This tutorial will provide you the steps and recommendations to best leverage the DevoxxGenie plugin for either local or cloud-based LLM code assistant tools.
Join the DZone community and get the full member experience.
Join For FreeDevoxxGenie is a fully Java-based LLM code assistant plugin for IntelliJ IDEA, designed to integrate with local LLM providers and cloud-based LLMs. In this blog, you will learn how to get started with the plugin and get the most out of it. Enjoy!
Introduction
AI coding assistants are getting more and more attention. Multiple cloud services are available and IDEs provide their own services. However, with this approach, you are tied to a specific vendor and most of the time, these services are cloud based only. What should you do when your company policy does not allow you to use these cloud-based services? Or what do you do when a new, more accurate model is released? When using IntelliJ IDEA, you can make use of the DevoxxGenie plugin, created by Stephan Janssen, founder of the Devoxx conference. The plugin allows you to choose between several cloud based and local LLMs. You are not tied to a specific cloud vendor or a specific model. This is important because every few weeks a new model is released, which outperforms previous ones.
If you rather look at a video, you can watch the 30-minute Tools-In-Action talk I gave at Devoxx Belgium 2024: DevoxxGenie: Your AI Assistant for IDEA.
1. Features
At the time of writing, v0.2.22 is the most recent release. However, new features are added continuously, because Stephan uses DevoxxGenie itself to create new features for DevoxxGenie. Here is a list of notable ones:
- Project Scanner: add full project source code to the prompt context. A prompt context is what you send to an LLM so it can create a response. If you want to ask questions about your project, you will get better answers if the LLM has the full source code.
.gitignore: exclude files and directories based on your .gitignorefile or exclude/include them using wildcards.- Add a selection of files for more focused responses. You are able to add single files or complete directories to the prompt context. This way, less content needs to be sent to an LLM.
- Calculate the number of tokens and estimate the cost. Cloud vendors will charge you based on the number of tokens you send in a prompt. A token is about 3/4 of a word. Especially when you add the full project source code to the prompt context, it is interesting to know beforehand how much it will cost you. The calculation only takes into account the input tokens. You will also be charged for the output tokens (the response) a cloud LLM generates. For the most part, this is only a fraction of the input token cost.
- Code highlighting in the responses makes the responses more readable.
- Send previous prompts and responses through the chat memory. Often you will receive a response which is not entirely correct. In this case, you want to send another prompt. The previous prompt and response is automatically added to the new prompt. This way, the LLM will take into account the previous prompt and response while generating the new response.
- Chat history is locally stored in order so that you can restore a previous prompt and response.
- Execute a web search and let the LLM generate a response based on the results.
- DevoxxGenie is entirely written in Java with LangChain4j.
- Support for several cloud-based LLMs: OpenAI, Anthropic, Mistral, Groq, Gemini, DeepInfra, DeepSeek, and OpenRouter.
- Support for several local LLM providers: Ollama, LMStudio, GPT4All, Llama.cpp, Exo, and custom URL.
- Streaming responses are also available, but still in beta at the time of this article's realease.
2. Installation
Install the plugin in IntelliJ via the settings. The plugin is available in the JetBrains marketplace.
3. Get Started With Cloud LLMs
First, let’s explain how you can get started with a cloud LLM. Anthrophic will be used, but you can choose any of the cloud LLMs as mentioned above. You need to be able to use the Anthrophic API. Therefore, navigate to the pricing page for the API and click the Start building button. In the following steps, you need to create an account and you also need to explain what you want to do with the API. Next, you need to choose a plan because you need credits in order to do something with the API. Choose the Build Plan (Tier 1). This will allow you to buy pre-paid credits.
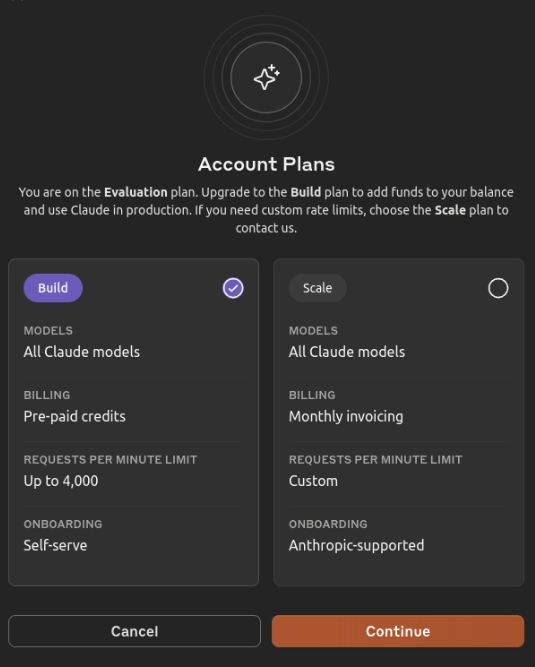
Add your credit card details and choose how much credit you want. In order to give you some indication of what it will cost you: the DevoxxGenie plugin is about 104K tokens. The pricing at the moment of writing for using Claude 3.5 Sonnet is $3/MTok for input tokens and $15/MTok for output tokens. This means that adding the full project source code, will cost you $3 x 1.000.000 / 104.000 = $0.312. You need to add your prompt to it and the output token cost, but the cost of a prompt using the full project source code will be approximately $0.40.
Last thing to do is to create an API key and add it to the settings in the DevoxxGenie plugin.

4. Get Started With Local LLMs
When you do not want to spend any money using a cloud provider, you can make use of a local LLM. When using local LLMs, you must be aware that your hardware will be a limiting factor. Some limiting factors include:
- A GPU will be faster than a CPU.
- The amount of memory available will limit the context size and the model you can use. The context size is how large your prompt can be. If you want to add the full source code of your project, you will need to have enough memory available.
- When choosing a model, you will notice that many variations exist of the same model. These will be indicated as Q2, Q4, Q5, and so on. This tells you something about the quality you may expect. The higher, the better. A higher quality will also result in the need for better hardware.
In the end, it is a trade-off between quality and performance.
In order to run a model, you need an LLM provider. A good one to start with is Ollama. After installing Ollama, you need to install a model. At the moment of this article's release, Llama 3.1 is a good model to start with. Install and run the model with the following command:
$ ollama run llama3.1Detailed information about the Ollama commands can be found at the GitHub page.
5. Configure Settings
Before using DevoxxGenie, you need to first configure some settings. Navigate to the LLM Settings section:
- Set the Temperature to 0 for coding tasks, the higher the temperature (with a maximum of 1 in the plugin), the more creative the LLM responses will be.
- When using a local LLM, you set the timeout to a higher value than its default of 60 seconds. On my machine, responses often take up around one minute and this leads to timeouts.
- Set the Maximum Attempts to 1. When using a local LLM, you will encounter timeouts and in this case, it is useless to try again because you will encounter a timeout again when consecutive attempts are made.
6. Add Code to Context
There are several ways to add code to the context in order so that an LLM can produce better responses.
- By default, an opened file will be added to the context.
- If you select a code snippet in the file, the code snippet will be added.
- Clicking the Add full project to prompt button will add the full source code of your project to the context taken into account the
.gitignorefile. In the settings you can finetune this even more. - In the bottom right corner a Select file(s) for prompt context button is available which displays the opened files, but it also allows you to search for other files and add them to the context.
- Using the context menu on a directory allows you to:
- add selected files to the prompt context
- add selected directories to the prompt context
7. Use Utility Commands
When you have selected the files needed for your prompt, you can just start typing your prompt and click the Submit the prompt button. Another way is to use one of the utility commands:
/test: will write a JUnit test for the selected code./explain: will explain the selected code./review: will review the selected code.
In the settings, you can change the prompts for the utility commands and you can define your own custom prompts. For example, if you often use a prompt for generating javadoc you can define a /doc utility command for your own custom prompt.
8. Chat Memory
The chat memory is a very powerful feature. Very often, your prompt will not be specific enough for the LLM to generate the response you want. In that case, you can create a new prompt indicating what is wrong with the previous response. The previous prompt and response will be sent to the LLM as chat memory together with the new prompt. Do realize that when your first prompt contained the full project source code, it will be sent again in the chat memory of your second prompt. If you do not want this to happen, you need to create a new chat which will reset the chat memory.
9. Streaming Mode
Although you can enable Streaming Mode in the settings, it is not advised to do so. It is still in beta and copying code from the response does not take into account line breaks which is very annoying. In non-streaming mode, a copy button is available to copy code to the clipboard which does take into account line breaks.
10. Tips and Tricks
Some practical tips and tricks:
- Work iteratively. Write a prompt and evaluate the response. Most likely, the response will not be entirely what you want. In that case, write a follow-up prompt and let the model fix it.
- Do not blindly copy-paste responses. Always try to understand the response. A model will provide you a solution, but it might not be the best solution. Maybe your prompt was not specific enough and you need to provide more detailed information about what you really want.
- When using local LLMs, try to use a GPU.
- If you do not have GPU, keep the prompts small. The context size of a local LLM will be smaller and responses will take some time (at least 30 seconds on my machine, but often it takes more than a minute, even for small prompts and responses).
- Be specific in your prompts. A nice guide on how to write prompts for coding tasks, can be found here.
- Experiment with different models and try to determine for yourself which model suits you best.
Conclusion
The DevoxxGenie plugin integrates well with IntelliJ and allows you to select a cloud LLM or local LLM to suit your needs. The most powerful feature is giving you the ability to use a local LLM and model or your liking or the ability to use a cloud provider of your liking.
These two features are especially important because you may not be allowed to use a cloud provider based on your company policies and besides that, every few weeks new models are released which outperform previous models. With DevoxxGenie you can use the power of the new models right away.
Published at DZone with permission of Gunter Rotsaert. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments