Disaster Recovery for Kubernetes Clusters
In this article, we discuss the options for setting up a disaster recovery for a Kubernetes container cluster and the best available solution.
Join the DZone community and get the full member experience.
Join For FreeImportance of Business Continuity
Business continuity is having a strategy to deal with major disruptions and disasters. Disaster recovery (DR) helps an organization to recover and resume business critical functions or normal operations when there are disruptions or disasters.
High-availability clusters are groups of servers that support business-critical applications. Applications are run on a primary server, and in the event of a failure, application operation is moved to the secondary server, where they continue to operate.
DR strategies work significantly different compared to pre-container days. Then the relationship is simple and straightforward, mapping one-to-one between the application and the application server. Taking a backup or snapshot of everything to restore in case of failure is the dated approach.

Disaster Recovery Types
Before we discuss different DR approaches, it’s important to understand the different types of disaster recovery sites. There are three types of DR sites: cold site, warm site, and hot site.
Cold Site: This is the basic option with minimal or no hardware/equipment. There will be no connectivity, backup, or data synchronization. Although this is one of the most basic, least expensive options, this is not ready to take the hit of failover.
Warm Site: This type has few options upgraded compared to the cold site. There can be options for network connectivity and hardware. This has data synchronization, and the failover can be addressed within hours or days, depending on the type of setup.
Hot Site: This is the most premium option in the lot, with fully equipped hardware and connectivity with near-perfect data synchronization. This is an expensive type of setup compared to the other two types of sites.
The impact of a disaster on an organization can be very expensive, so it is important to make the best choice in the first place. Disaster recovery management can mitigate the impact of the disaster due to its disruptive incidents. No approach/option is perfect, and it can vary depending on the requirement and type of the business/organization.

Traditional DR Approaches
Option 1: We can have a cold standby by having the periodic backups, or you can have a warm standby by having the batch/scheduled replication of the data. The major difference here is the type of replication from the main primary data center to DR. In this option, application, and data are not available until the standby is bought online, and there are high chances of data loss due to periodic/scheduled backups.
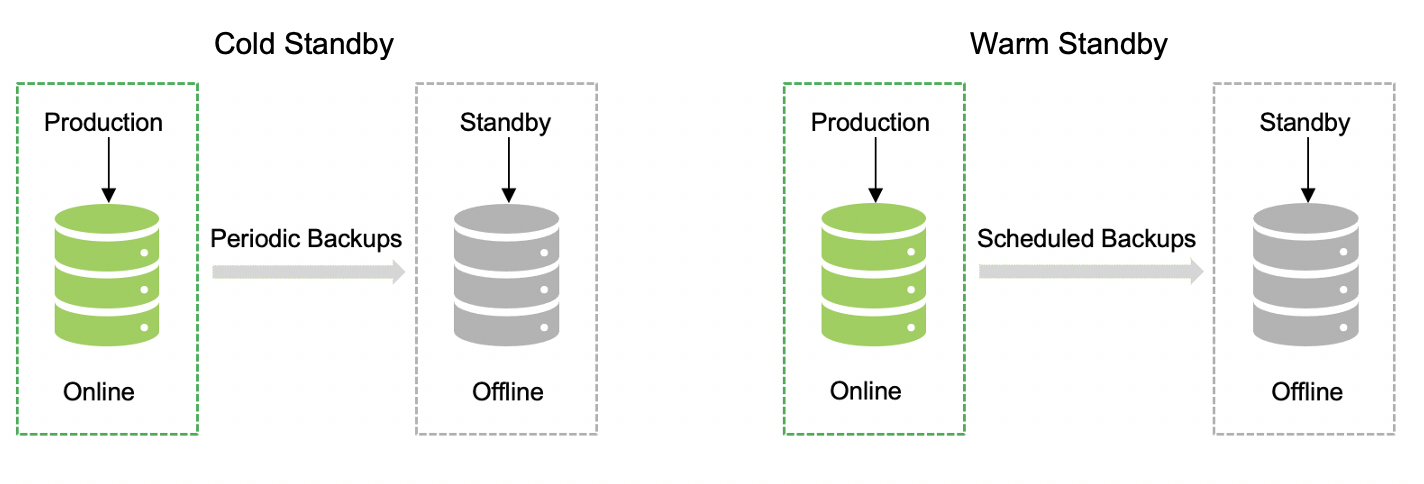
Option 2: In this case, we have continuous replication in place with a very minimal baseline time between the replication. This is a hot standby, and the other one is the hot standby with read replicas. That means both will be the same in terms of reading the data, while the data can be written only at the primary data center location. Standby can be available for immediate use in case of a disruption.
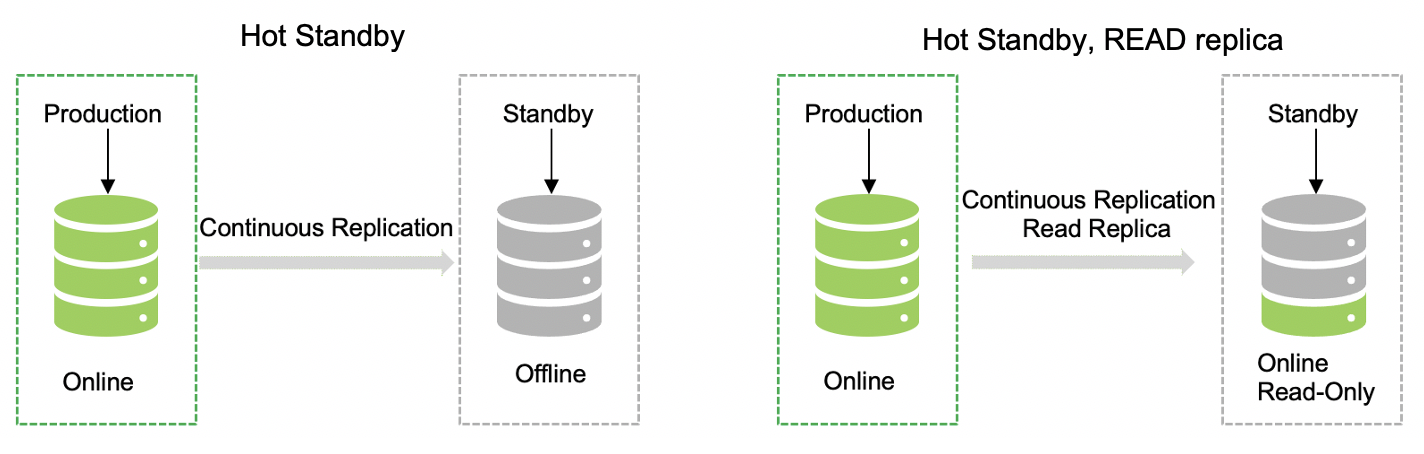
Option 3: This is the most robust way of having the disaster recovery setup. In this case, you need to maintain two active data centers with real-time data replication seamlessly. This model required an advanced setup with the latest technology and tool stack. This is a comprehensive model, but it can be expensive. Configuration and maintenance can be complicated — niche skills are required to run this kind of setup.

Disaster Recovery for Containers
Now, let’s discuss how we can do disaster recovery management using the containerized ecosystem.
Kubernetes Cluster: When you deploy Kubernetes, you get a cluster. A Kubernetes cluster consists of a set of worker machines, called nodes, that run containerized applications. Every cluster has at least one worker node. The worker node(s) host the Pods that are the components of the application workload. The control plane manages the worker nodes and the Pods in the cluster. In production environments, the control plane usually runs across multiple computers, and a cluster usually runs multiple nodes, providing fault tolerance and high availability. To learn more about cluster components, refer to the link.
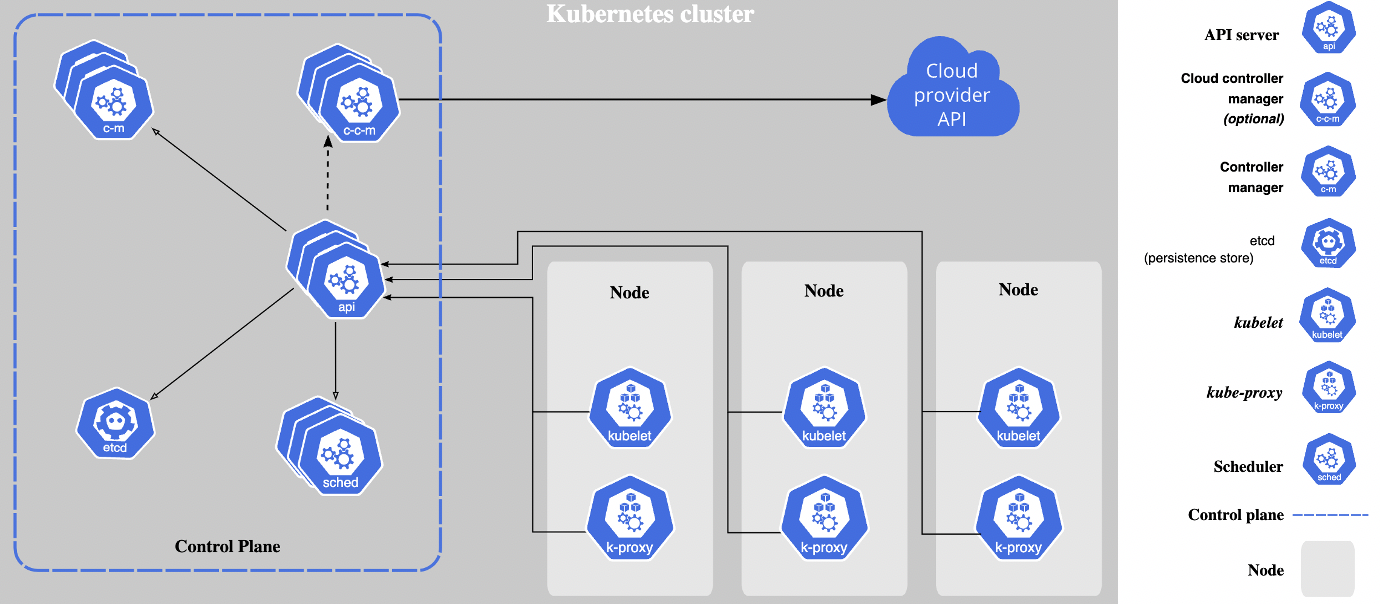
In this setup, the application will not be deployed into one defined server. It can be scheduled on any of the worker nodes. Capacity management will be done in the cluster as Kubernetes is an orchestration tool — deployments are assigned as per the availability of the nodes.
What We Need To Backup
We understand the nature of the Kubernetes ecosystem is very dynamic, and it makes it harder for more traditional backup systems and techniques to work well in the context of Kubernetes nodes and applications. Both RPO and RTO may need to be far stricter since applications need to constantly be up and running.
Below is the list of important things for backup:
- Configurations
- Container Images
- Policies
- Certificates
- User Access Controls
- Persistent Volumes
There are two types of components in the cluster stateful and stateless. State full components are mindful, expect a response, track information, and resend the request if no response is received. ETCD and Volumes are the stateful components. While remaining of the Kubernetes plane, worker nodes and workloads are the stateless components. It’s important to take the backup of all the stateful components.
ETCD Backup
ETCD is a distributed key-value store used to hold and manage the critical information that distributed systems need to keep running. Most notably, it manages the configuration data, state data, and metadata for Kubernetes, the popular container orchestration platform.
We can back up ETCD by using the built-in snapshot feature of the ETCD. The other option is to take a snapshot of the storage volume. The third option is to take the backup of the Kubernetes objects/resources. The restore can be done from the snapshot, volume, and objects respectively.
Persistent Volume Backup
Kubernetes persistent volumes are administrator-provisioned volumes. These are created with a particular filesystem, size, and identifying characteristics such as volume IDs and names.
A Kubernetes persistent volume has the following attributes
- It is provisioned either dynamically or by an administrator
- Created with a particular filesystem
- Has a particular size
- Has identifying characteristics such as volume IDs and a name
In order for pods to start using these volumes, they need to be claimed, and the claim referenced in the spec for a pod. A Persistent Volume Claim describes the amount and characteristics of the storage required by the pod, finds any matching persistent volumes, and claims these. Storage Classes describe default volume information.
Create volume snapshot from persistent volumes:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: new-snapshot-test
spec:
volumeSnapshotClassName: csi-hostpath-snapclass
source:
persistentVolumeClaimName: pvc-testRestore the Volume Snapshot
You can reference a VolumeSnapshot in a PersistentVolumeClaim to provision a new volume with data from an existing volume or restore a volume to a state that you captured in the snapshot. To reference a VolumeSnapshotin a PersistentVolumeClaim, add the data source field to your PersistentVolumeClaim.
In this example, you reference the VolumeSnapshot that you created in a new PersistentVolumeClaim and update the Deployment to use the new claim.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-restore
spec:
dataSource:
name: my-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
storageClassName: standard-rwo
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1GiRestore Kubernetes Platform Operations
We can restore the k8s platform in two ways: rebuilding or restoring. Below are a few strategies to restore platform operations:
- Platform backup and restore
We need to run this operation using a backup tool that will take the backup from the source cluster related to applications ETCD, configurations, and images, which will store this information in the backup repository. Once the backup is done, you need to run this restore operation from the target cluster using the same backup tool and can restore the information from the replication repository.
- Restore VMs from the snapshot
This strategy is only for ETCD recovery. The steps involved in restoring a Kubernetes cluster from an ETCD snapshot can vary depending on how the Kubernetes environment is set up, but the steps described below are intended to familiarize you with the basic process. It is also worth noting that the process described below replaces the existing ETCD database, so if an organization needs to preserve the database contents, it must create a backup copy of a database before moving forward.
- Install the ETCD client
- Identify appropriate IP addresses
- Edit a manifest file to update paths
- Locate the Spec section
- Add the initial cluster token to the file
- Update the mount path
- Replace the name of the hose path
- Verify the newly restored database
- Failover to another cluster
In case of failure of one cluster, we use a failover cluster. These clusters are identical to infrastructure and stateless applications. However, the configurations and secrets can be different. At setup, these two types of clusters can be in sync with CI/CD. This can be expensive in the setup and maintenance aspects as we have double clusters run in parallel.
- Failover to another site in case of multisite
In this strategy, we need to build a cluster across multiple sites. This is applicable to the cloud as well as on-premises. It is always recommended to have more than two sites and an odd number of sites due to the ETCD quorum to keep the cluster operation in case of failure at one site. This is a popular and efficient way compared to other options. Savings yield on how we manage the capacity.
- Rebuild from the scratch
This is called GitOps, and the concept here is, why don’t we rebuild the system in the case of failure instead of repair? If there is a failure in the cluster, we can build the entire cluster from the git wrapper, and no backup is required for the ETCD. This works perfectly for the stateless applications, but if you are combining this with persistence data, then we need to look for options on backing and restoring the storage.
Conclusion/Summary
It is very important to plan and design your own disaster recovery strategy depending on the requirement, complexity, and budget. Planning well ahead of time is very important. We need to know what the tolerance level of the infrastructure is and how much service loss you can bear, etc., to design a cost-efficient disaster recovery strategy. One other key understanding required is about the workloads. Are we running stateful or stateless workloads? We need to know what the underlying technologies and dependencies are connected to the backup and restore. when it comes to DevOps for mission-critical cloud-native applications requiring 100% uptime and availability. In the event of a disaster, the applications need to continue to be available and perform without a hitch. It is important to understand the components and strategies they need to consider for effective disaster recovery for Kubernetes.
Opinions expressed by DZone contributors are their own.
Comments