Docker Model Runner: A Game Changer in Local AI Development (C# Developer Perspective)
Explore how C# developers can use Docker Model Runner to run AI models locally, reduce setup time, and integrate OpenAI-compatible APIs into their apps.
Join the DZone community and get the full member experience.
Join For FreeBig breakthroughs and advancements in AI, particularly with LLM's (Large Language Models) have made it increasingly common for developers to integrate AI capabilities into their applications in a faster way than ever before. However, developing, running, and testing these models locally can often be challenging due to environment inconsistencies, performance issues, and dependency management. It's a common pattern. To help with this, Docker introduced Docker Model Runner, a new feature in Docker Desktop designed to simplify the process. In this post, we’ll take a closer look at Docker Model Runner, explore its benefits, and walk through an end-to-end project to see it in action.
What Is Docker Model Runner (DMR)?
Docker Model Runner is a feature integrated into Docker Desktop that aims to streamline local development and testing of LLM models. It helps in solving several pain points often faced by developers working on AI related projects.
- Simplified Set-up: No need to worry about installing complex AI frameworks, libraries, dependencies. DMR gives you a common environment.
- Run Locally: With DMR, you can run AI models on your own machine directly, use your own local hardware and its GPU without relying on external cloud services during development.
- Consistency: Just as Docker containers provide consistent environments for applications, DMR provides consistent execution environments for AI models.
- Integration with Docker Ecosystem: Models can be pulled from Docker Hub as OCI artifacts, they can be managed using standard Docker commands and are easy to integrate into Docker Compose projects.
- OpenAI-Compatible API: Many models exposed through DMR expose an OpenAI-compatible API making it easy to go back and forth between using AI services locally and those hosted publicly in the cloud.
How to Set Up Docker Model Runner (DMR)
To get started, make sure you have Docker Desktop version 4.40 or newer installed. Head over to Settings, open the Beta Features tab, and turn on Docker Model Runner. While you're there, also enable host-side TCP support, it defaults to port 12434, which lets your local apps talk to the model runner outside of Docker. This allows DMR to expose its API on your local network interface, so even applications running outside of Docker containers can access it. We'll test this using a .NET console project running outside Docker.
Note: If your Windows system supports an NVIDIA GPU, you can optionally enable “GPU-backed inference” for better performance. Save your changes and restart Docker Desktop to apply the settings.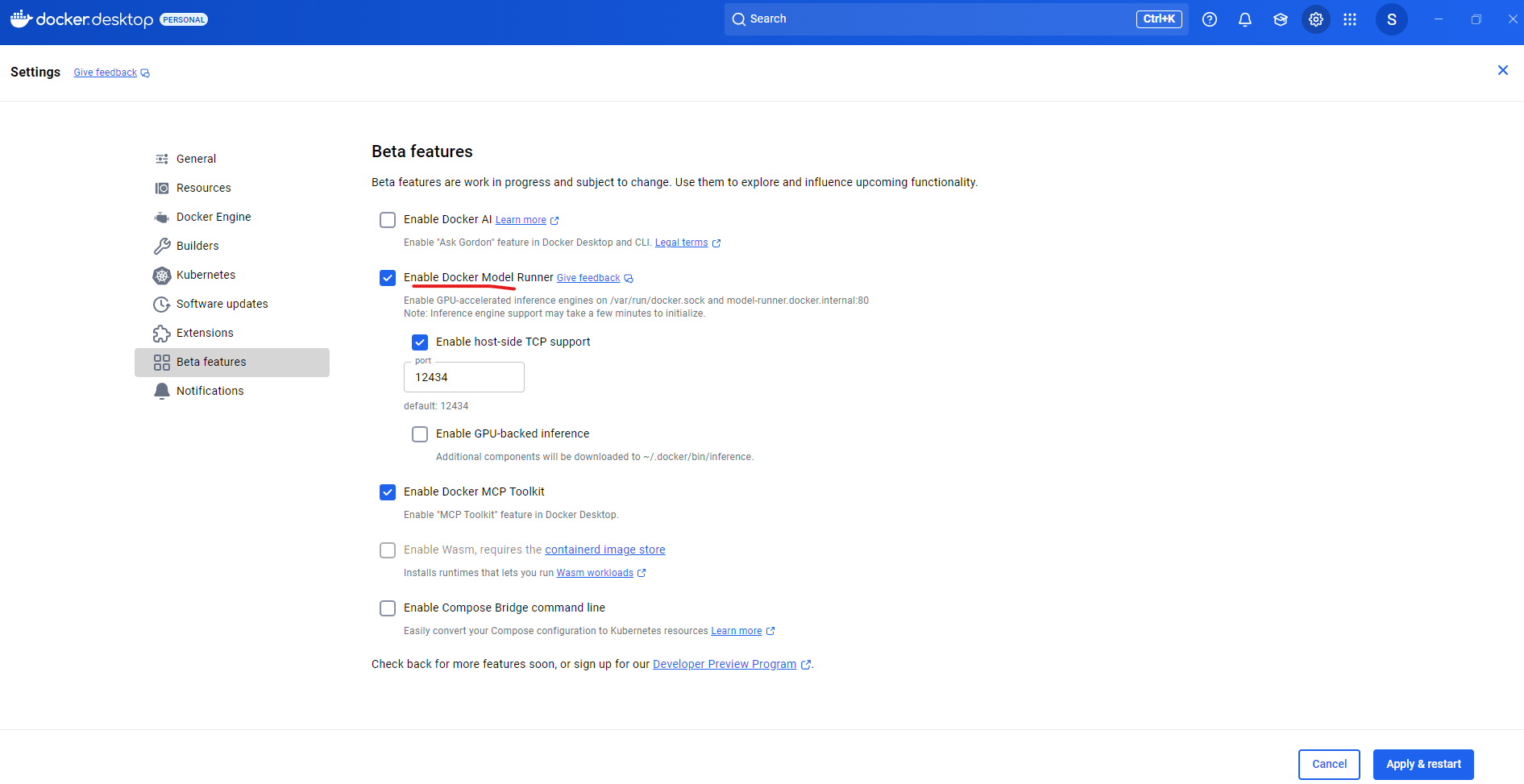
Once you’ve enabled those settings, you’re ready to go. You can start using the docker model command right from your terminal to work with local AI models.
How to Pull an Ollama Image and Run as Containerized Service
You can pull the image and run Ollama as a containerized service by executing the commands below:
docker pull ollama/ollama
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama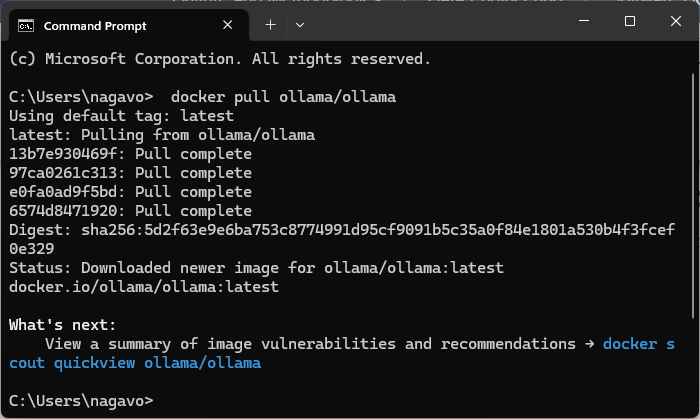
Next, go to https://localhost:11434 and you should see a message that says "Ollama is running."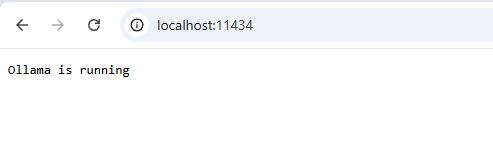
However, to use it, the models need to run in Docker containers, and it relies on Ollama’s own API format. In the next section, we will see how you can pull and run models from Docker Model runner without directly downloading the image.
How to Pull and Run Models From Docker Hub
You can pull models from Docker Hub that are compatible with Docker Model Runner. Run the command below in your terminal to pull the Ollama server image, which can run LLMs (like Llama 2, Mistral, etc.) inside a Docker container.
For this example, lets do model pull ai/smollm2 model.
docker model pull ai/smollm2
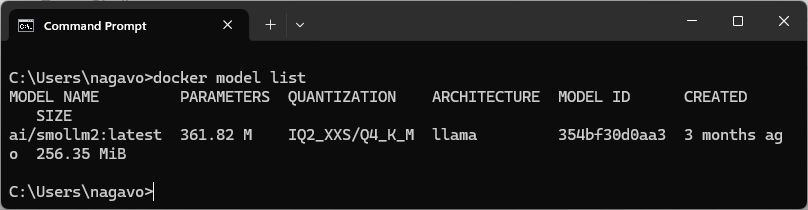
The image above shows that the ai/smollm2 image was pulled successfully. You can now run the command below to list the models available in your setup.
docker model listThis image includes the ai/smollm2 model. Let’s use it in our .NET application.
You can interact with the above model directly from the terminal by running the command below.
docker model run ai/smollm2
The next image shows the interactive chat mode started with the ai/smollm2 model.
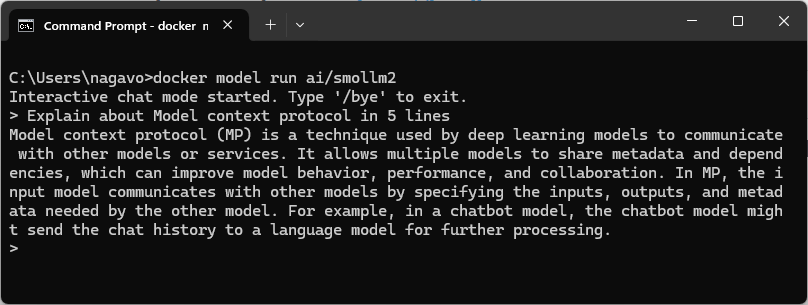
This makes it simpler to interact with models through Docker Model Runner directly from the CLI.
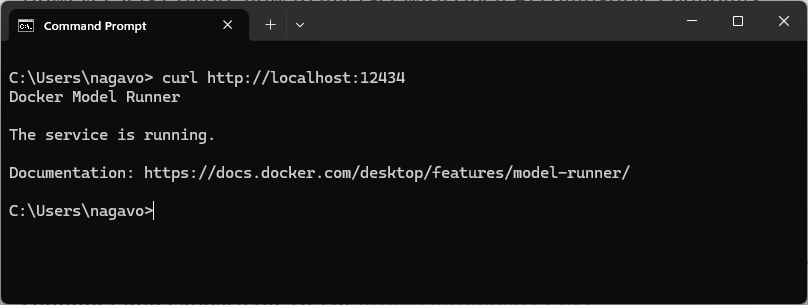
Now, putting on the developer hat, let’s explore how to interact with OpenAI-compatible endpoints. To check if Docker Model Runner is running, enter the command below. It’ll confirm that the service is active and ready to use.
curl http://localhost:12434You should see the message, "Docker Model Runner. The service is running", as shown in the image below.
Let’s create a simple .NET console application to interact with the OpenAI-compatible endpoints.
Open a terminal and run the following commands to create the .NET console application:
dotnet new console -n ModelRunnerClient
cd ModelRunnerClient
dotnet add package System.Net.Http.JsonWe’ll use HttpClient to make a request to the Docker Model Runner API endpoint. Go ahead and update the Program.cs file with the code below. This will allow your .NET app to interact with the Docker Model Runner endpoint.
using System;
using System.Net.Http;
using System.Net.Http.Json;
using System.Threading.Tasks;
namespace ModelRunnerClient
{
public class Program
{
private static readonly HttpClient _httpClient = new HttpClient();
private const string DockerModelRunnerApiUrl = "http://localhost:12434/engines/llama.cpp/v1/chat/completions";
public static async Task Main(string[] args)
{
Console.WriteLine("Welcome to the Docker Model Runner .NET Client!");
Console.WriteLine("This version works with Docker Model Runner's ai/smollm2 model.");
Console.WriteLine("Type your prompt and press Enter (type 'exit' to quit):");
while (true)
{
Console.Write("> ");
string? prompt = Console.ReadLine();
if (string.IsNullOrWhiteSpace(prompt) || prompt.ToLower() == "exit")
break;
var requestPayload = new
{
model = "ai/smollm2",
messages = new[]
{
new { role = "system", content = "You are a helpful assistant." },
new { role = "user", content = prompt }
}
};
try
{
var response = await _httpClient.PostAsJsonAsync(DockerModelRunnerApiUrl, requestPayload);
response.EnsureSuccessStatusCode();
var result = await response.Content.ReadFromJsonAsync<OpenAIResponse>();
if (result?.choices?.Length > 0)
{
Console.WriteLine($"\nAI: {result.choices[0].message.content}\n");
}
else
{
Console.WriteLine("\nAI: No response received.\n");
}
}
catch (Exception ex)
{
Console.WriteLine($"\nError: {ex.Message}");
Console.WriteLine("Make sure Docker Model Runner is enabled and TCP support is enabled.");
Console.WriteLine("Check if the service is running at http://localhost:12434\n");
}
}
}
}
public class OpenAIResponse
{
public Choice[]? choices { get; set; }
public int created { get; set; }
public string? id { get; set; }
public string? model { get; set; }
public string? object_type { get; set; }
public Usage? usage { get; set; }
}
public class Choice
{
public Message? message { get; set; }
public int index { get; set; }
public string? finish_reason { get; set; }
}
public class Message
{
public string? role { get; set; }
public string? content { get; set; }
}
public class Usage
{
public int prompt_tokens { get; set; }
public int completion_tokens { get; set; }
public int total_tokens { get; set; }
}
}
The code is self-explanatory. We're interacting with the ai/smollm2 model running inside Docker Model Runner by sending a request to this endpoint: http://localhost:12434/engines/llama.cpp/v1/chat/completions.
To run the application, use the command below:
dotnet runNow you can interact with the model directly from your terminal as shown below.

Conclusion
Docker Model Runner is definitely a valuable addition from Docker, especially for local AI model development. It simplifies interaction with models by handling setup and dependencies, allowing developers to quickly prototype, test, and integrate intelligent features into existing applications without the cost or latency concerns of relying on cloud-hosted AI services.
References
1. “Docker Model Runner.” (2025, June 26). Docker Documentation. https://docs.docker.com/ai/model-runner/
2. Ollama. (n.d.). Ollama. https://ollama.com/
Opinions expressed by DZone contributors are their own.
Comments