Doris Lakehouse Integration: A New Approach to Data Analysis
Doris Lakehouse Integration bridges data lakes and warehouses and enables seamless access, faster queries, unified management, and greater data value.
Join the DZone community and get the full member experience.
Join For FreeIn the wave of big data, the data volume of enterprises is growing explosively, and the requirements for data processing and analysis are becoming increasingly complex. Traditional databases, data warehouses, and data lakes operate separately, resulting in a significant reduction in data utilization efficiency.
At this time, the concept of lakehouse integration emerged, like a timely rain, bringing new possibilities for enterprise data management. Today, let's talk about lakehouse integration based on Doris and see how it solves the problems of data management and enables enterprises to play with big data!
The "Past and Present" of Data Management
In the development of big data technology, databases, data warehouses, and data lakes have emerged one after another, each with its own mission.
- The database is the "veteran" of data management, mainly responsible for online transaction processing. For example, the mall cashier system records every transaction and can also perform some basic data analysis. However, as the data volume "grows wildly," the database becomes a bit overwhelmed.
- The data warehouse emerged as the times required. It stores high-value data that has been cleaned, processed, and modeled, providing professional data analysis support for business personnel and helping enterprises dig out business value from massive data.
- After the emergence of the data lake, it can store structured, semi-structured, and even unstructured data at a low cost and also provides an integrated solution for data processing, management, and governance, meeting various needs of enterprises for raw data.
However, although data warehouses and data lakes each have their own strengths, there is also a "gap" between them. Data warehouses are good at fast analysis, and data lakes are better at storage management, but it is difficult for data to flow between the two.
Lakehouse integration is to solve this problem, allowing seamless integration and free flow of data between the data lake and the data warehouse, giving full play to the advantages of both and enhancing data value.
The "Magic Power" of Doris Lakehouse Integration
The lakehouse integration designed by Doris focuses on four key application scenarios, each hitting the pain points of enterprise data management.
1. Lakehouse Query Acceleration
Doris has a super-efficient OLAP query engine and an MPP vectorized distributed query layer. For example, it is like a super sports car on the data highway, which can directly accelerate the analysis of data on the lake. Data query tasks that previously took a long time to process can be completed in an instant with the help of Doris, greatly improving the efficiency of data analysis.
2. Unified Data Analysis Gateway
The data sources of enterprises are diverse, including data from different databases and file systems, which is very troublesome to manage. Doris is like a "universal key," providing query and write capabilities for various heterogeneous data sources. It can unify these external data sources onto its own metadata mapping structure. No matter where the data comes from, when users query through Doris, they can get a consistent experience, as convenient as operating a single database.
3. Unified Data Integration
Doris, with the data source connection capabilities of the data lake, can synchronize data from multiple data sources in an incremental or full-volume manner and can also use its powerful data processing capabilities to process the data. The processed data can not only directly provide query services through Doris but can also be exported to provide data support for downstream.
4. A More Open Data Platform
The storage format of traditional data warehouses is closed, and it is difficult for external tools to access the data. Enterprises are always worried that the data will be "locked" inside. After the access to the Doris lakehouse integration ecosystem, open-source data formats such as Parquet/ORC are adopted to manage data, and the open-source metadata management capabilities provided by Iceberg and Hudi are also supported, allowing external systems to easily access the data.
The "Hard-Core Architecture" of Doris Lakehouse Integration
The core of the Doris lakehouse integration architecture is the multi-catalog, which is like an intelligent data "connector." It supports connecting to mainstream data lakes and databases such as Apache Hive and Apache Iceberg, and can also perform unified permission management through Apache Ranger to ensure data security.
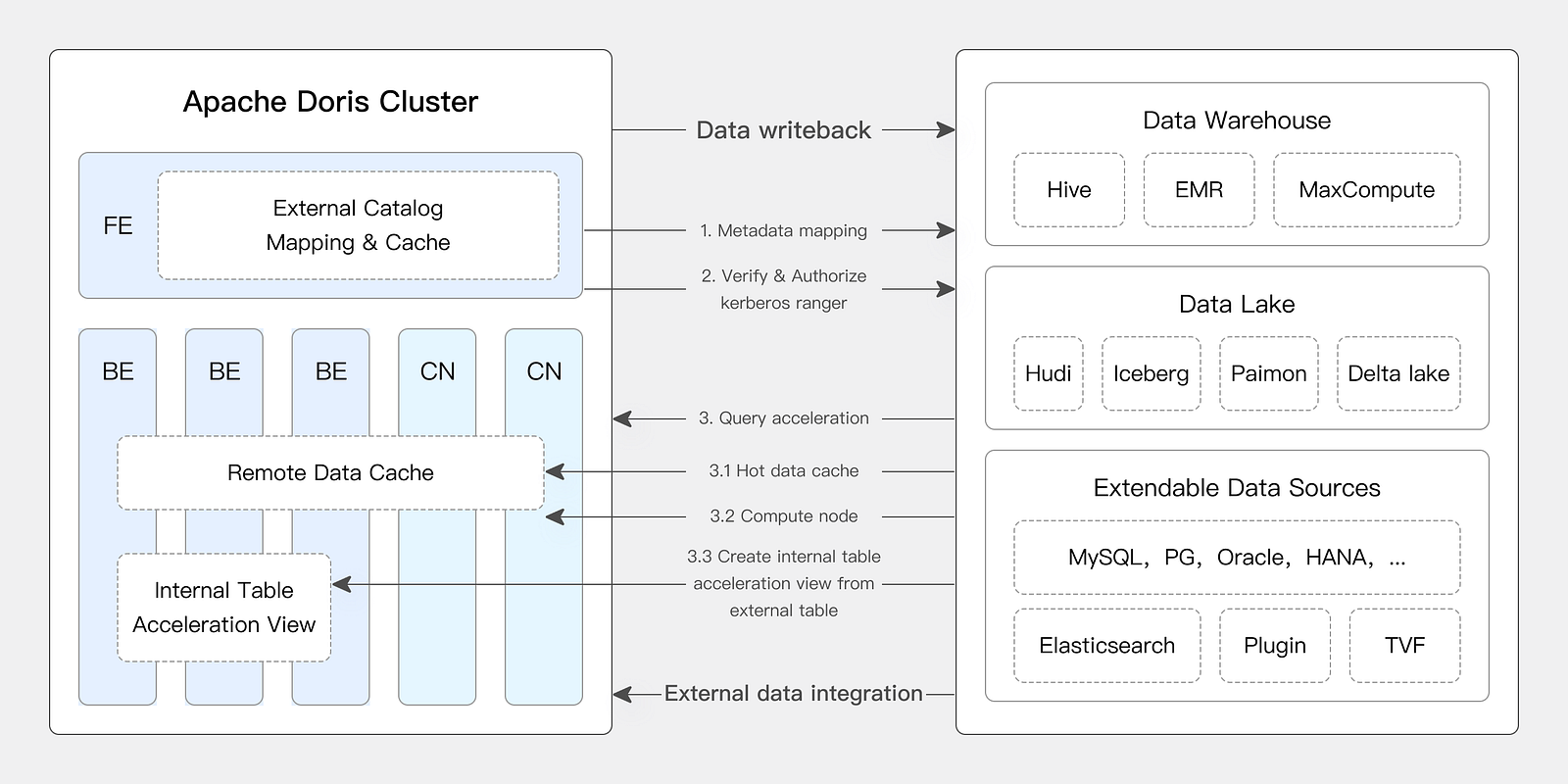
The data lake docking process:
- Create metadata mapping. Doris obtains and caches the metadata of the data lake, and, at the same time, supports a variety of permission authentication and data encryption methods;
- Execute query. Doris uses the cached metadata to generate a query plan, fetches data from external storage for calculation and analysis, and caches hot data;
- Return query results. FE returns the results to the user, and the user can choose to write the calculation results back to the data lake.
The "Core Technologies" of Doris Lakehouse Integration
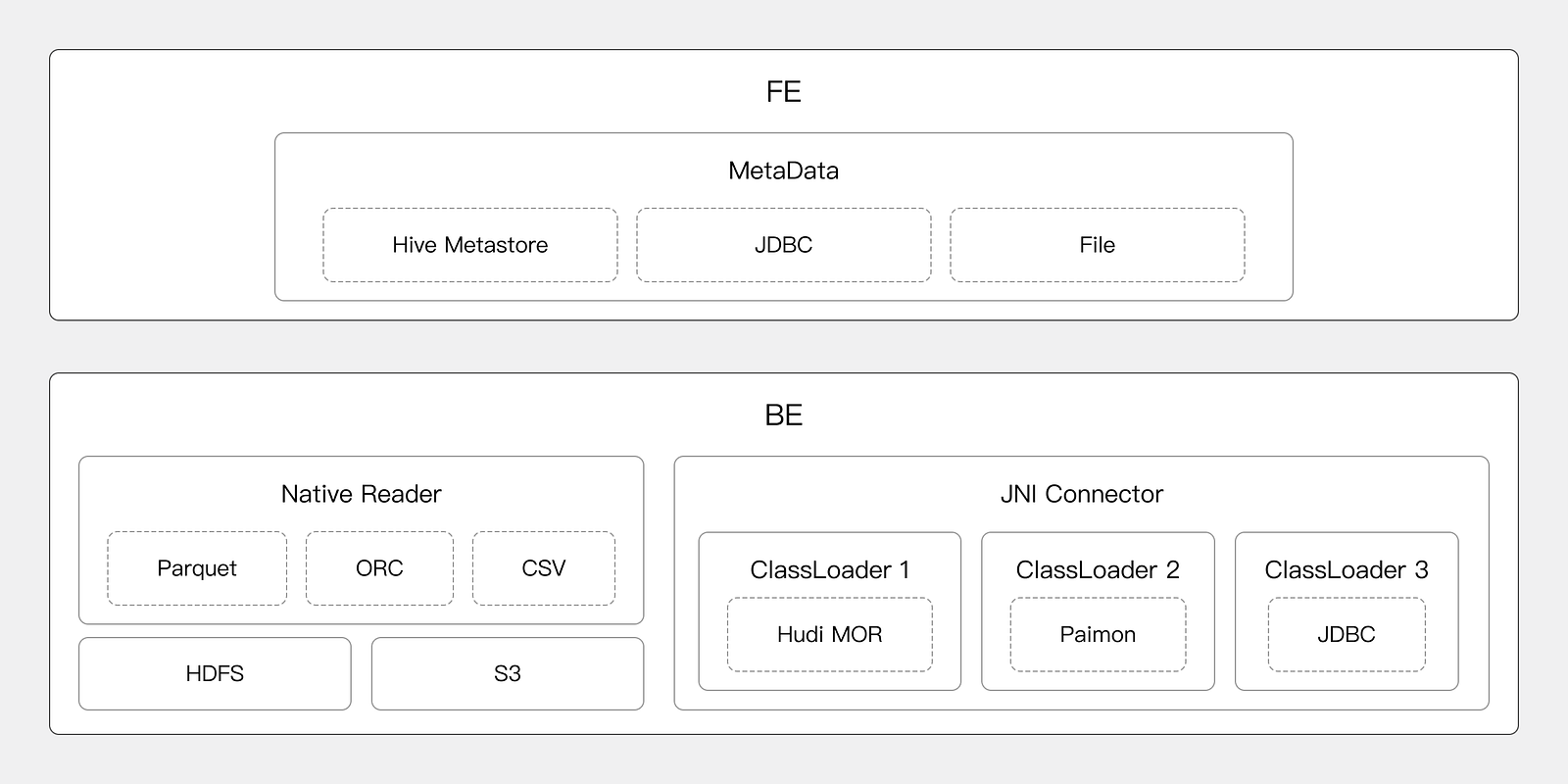
An Extensible Connection Framework
- FE is responsible for metadata docking, and realizes metadata management based on HiveMetastore, JDBC, and files through the MetaData manager.
- BE provides efficient reading capabilities, reads data in multiple formats through NativeReader, and JniConnector is used to dock the Java big data ecosystem.
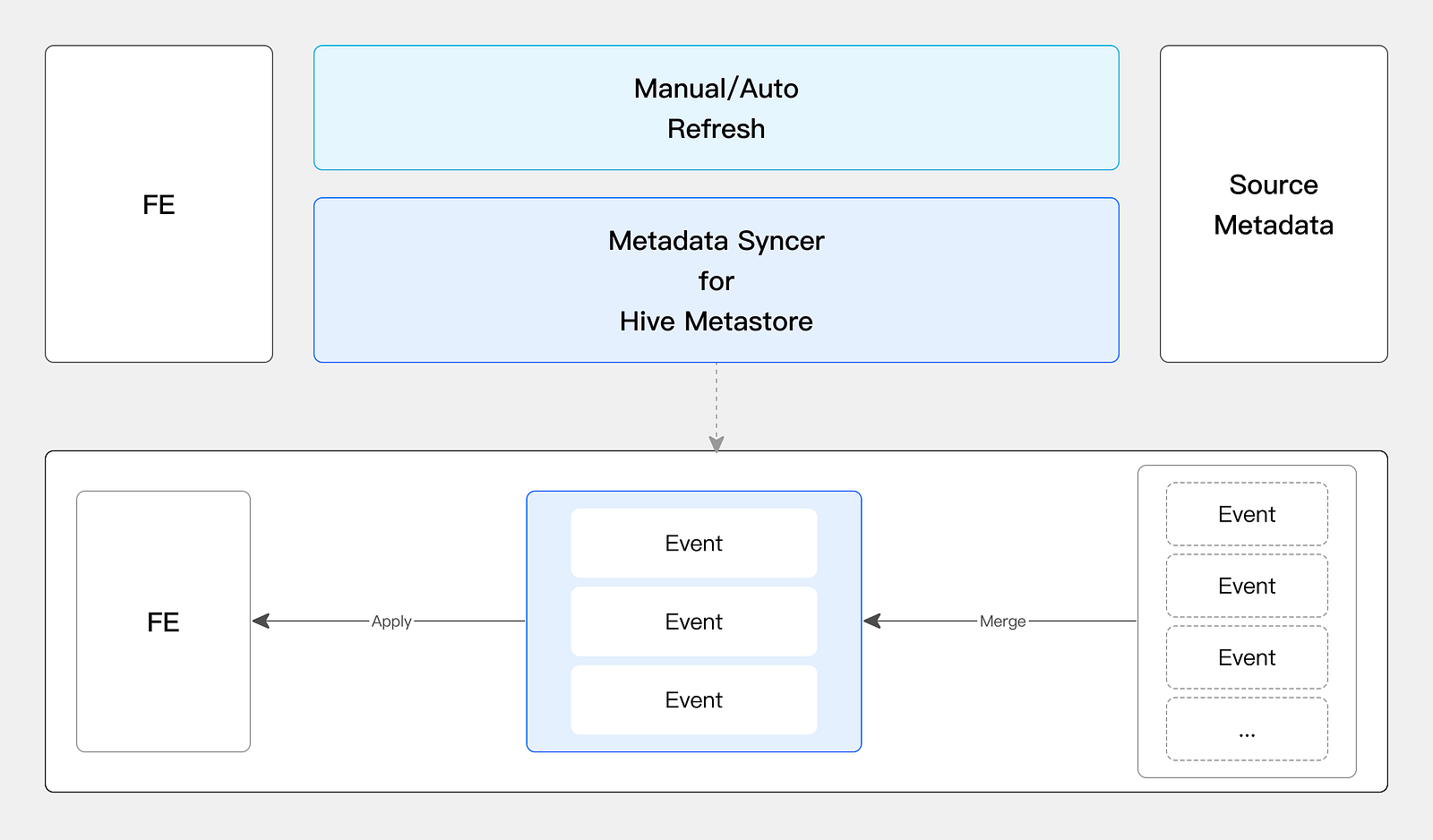
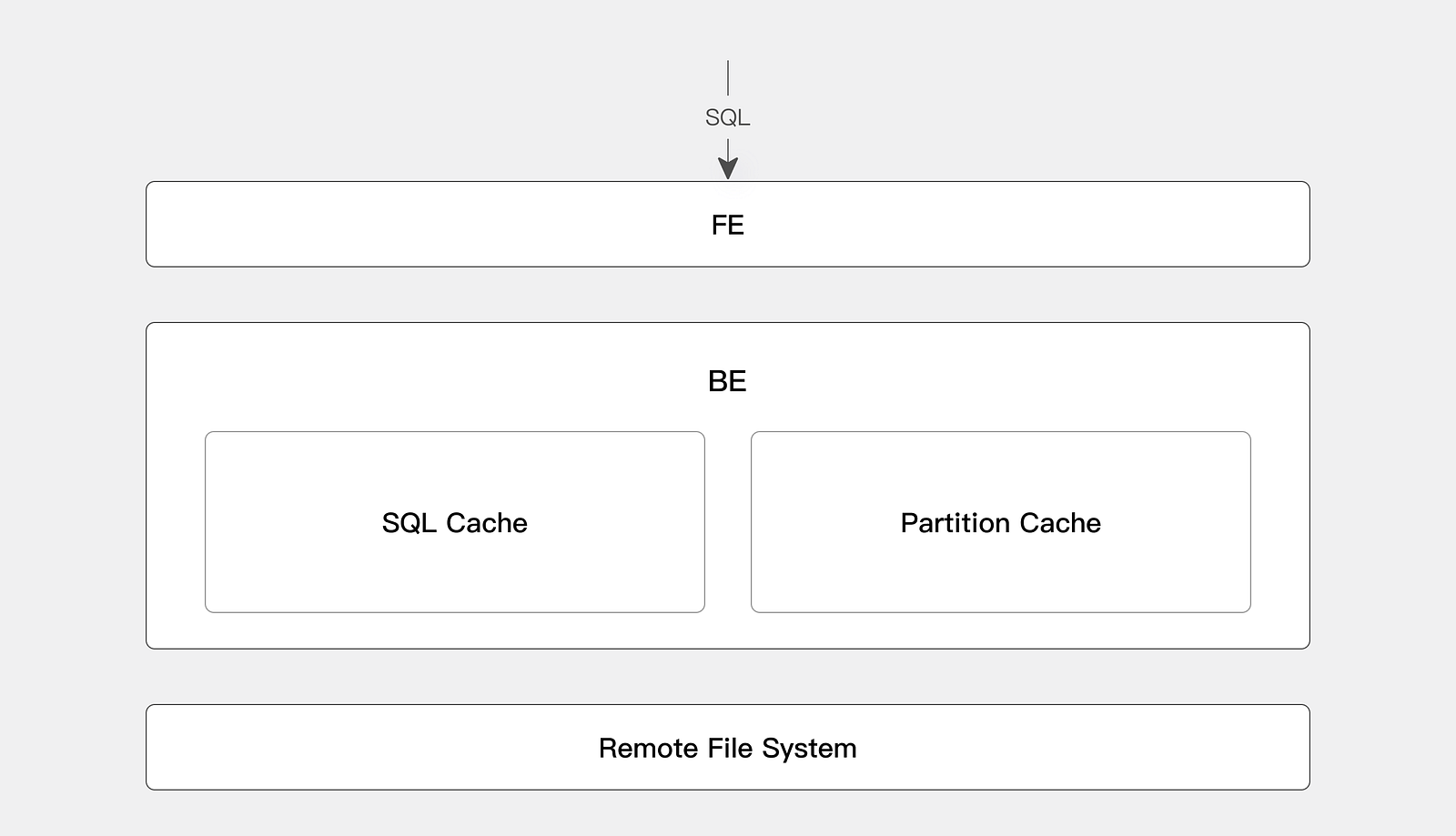
An Efficient Caching Strategy
- Metadata caching. Supports manual synchronization, regular automatic synchronization, and metadata subscription to ensure real-time and efficient metadata.
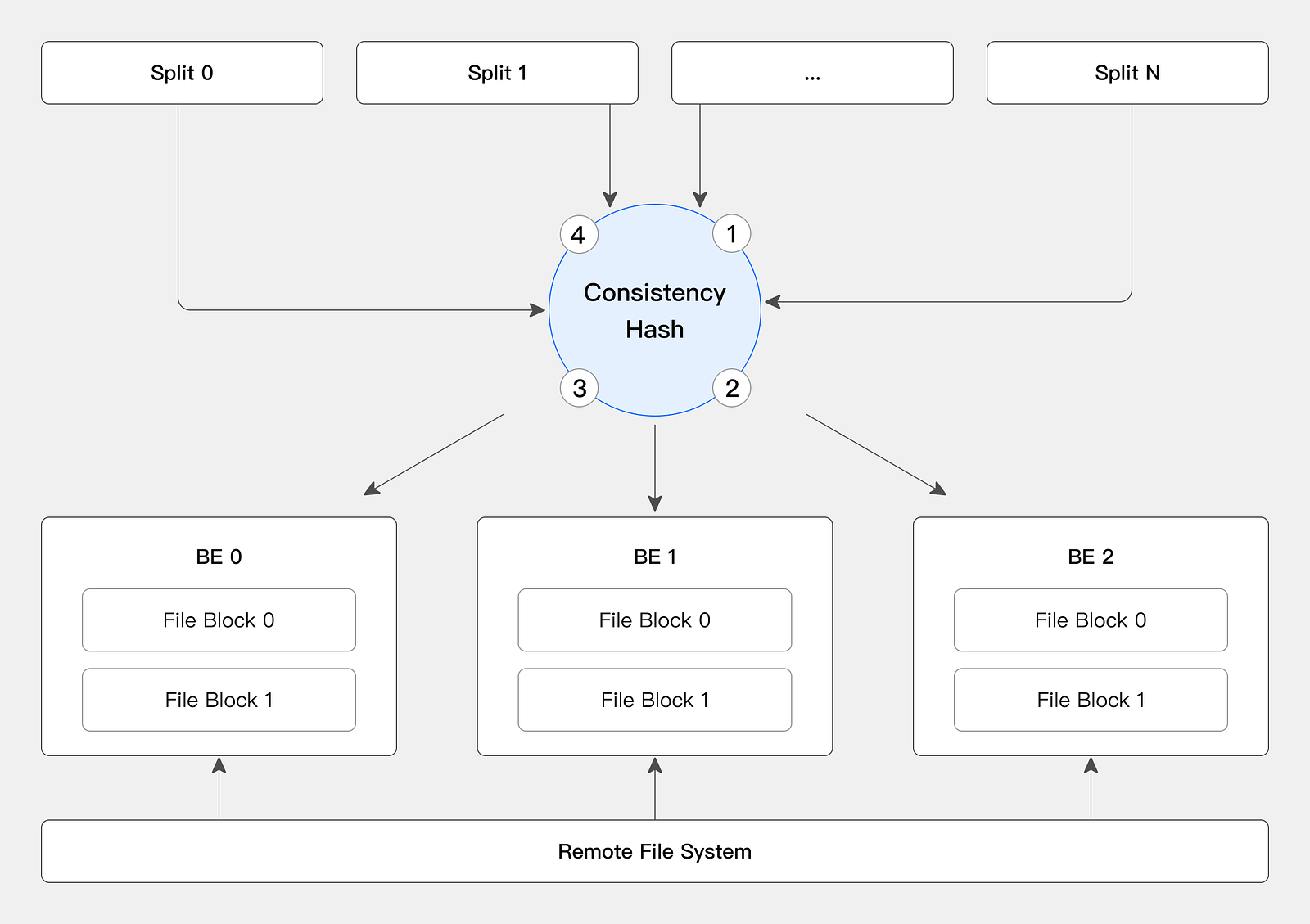
- Data caching. Stores hot data on local disks, using consistent hashing distribution to avoid cache invalidation when nodes are scaled up or down.
- Query result caching. Allows the same query to directly obtain data from the cache, reducing the amount of calculation and improving query efficiency.
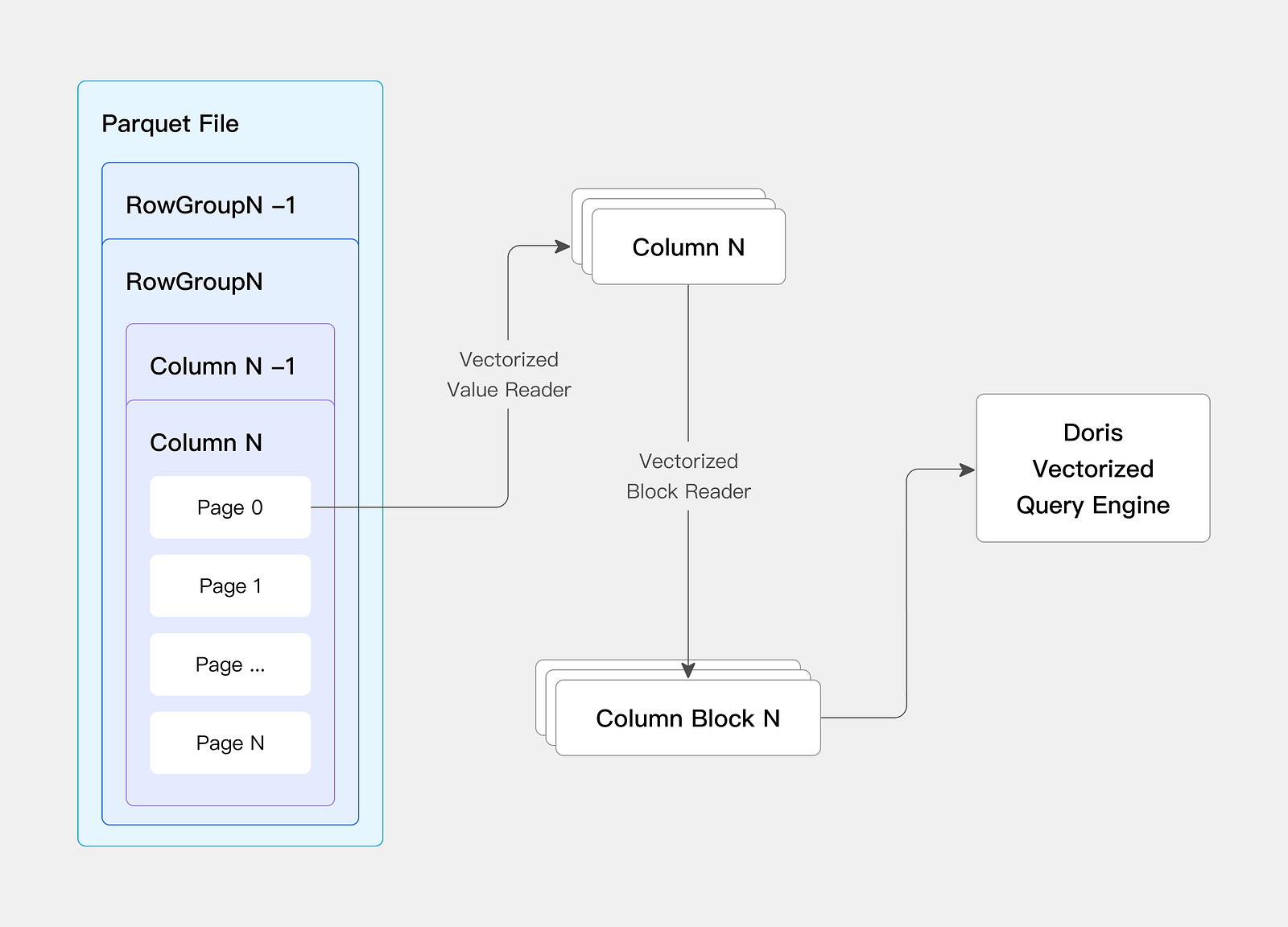
An Efficient Native Reader
The self-developed Native Reader of Doris directly reads Parquet and ORC files, avoiding data conversion overhead, and at the same time introduces vectorized data reading to accelerate the data reading speed.
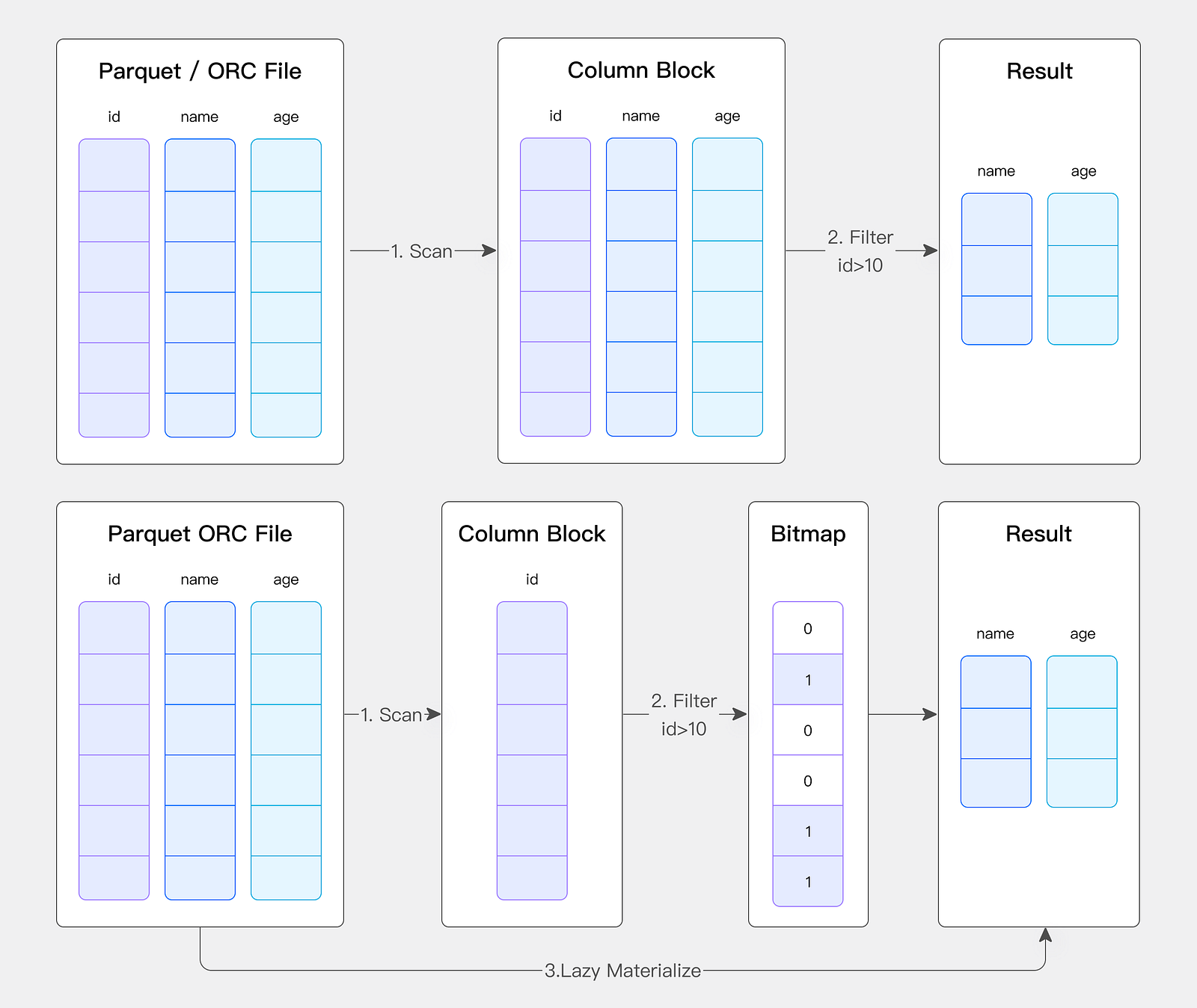
Merge IO
Facing a large number of small-file IO requests, Doris adopts the Merge IO technology to combine small IO requests for processing, improving the overall throughput performance, and the optimization effect is significant in scenarios with more fragmented files.

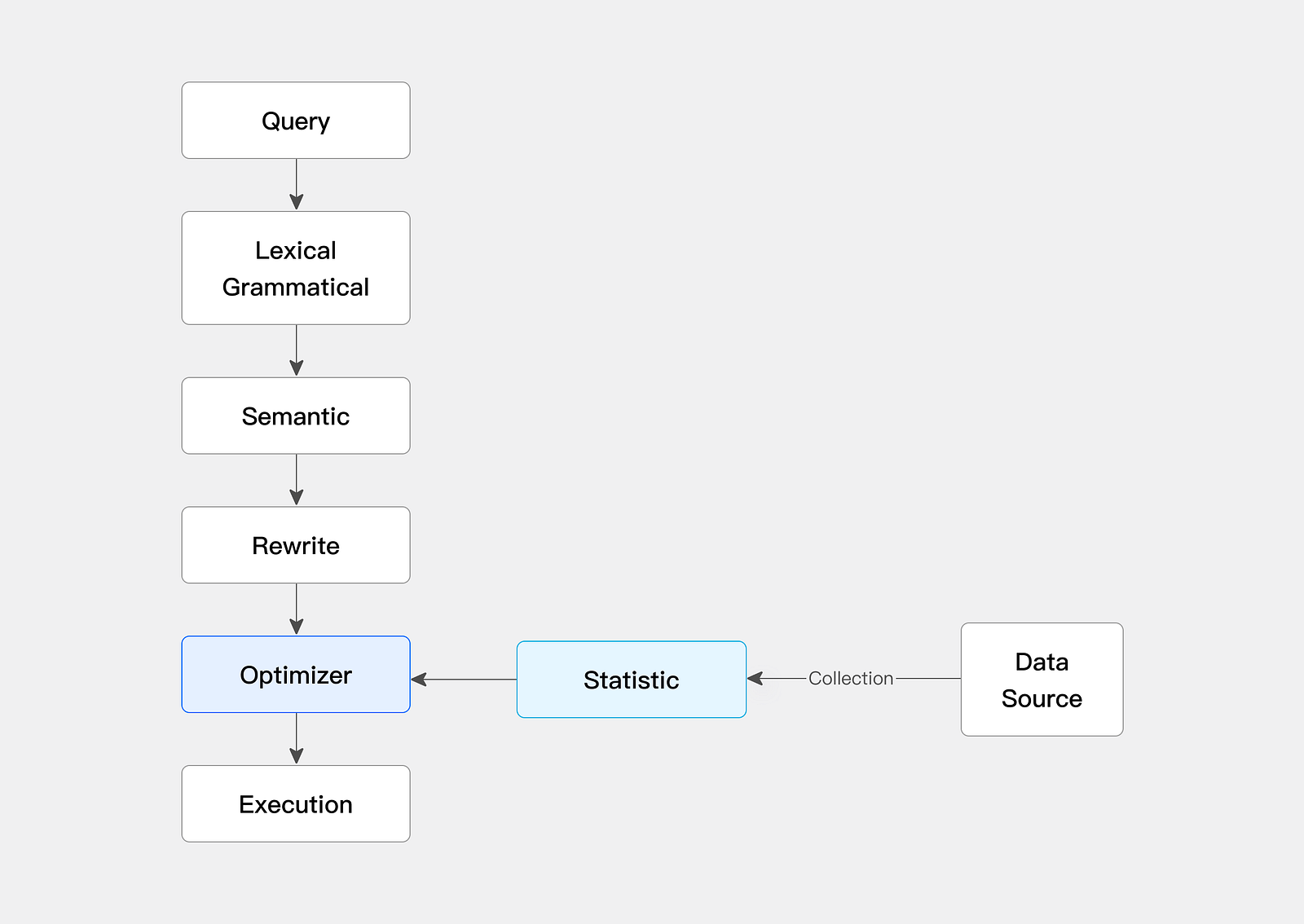
Statistical Information Improves Query Planning Effect
Doris optimizes the query execution plan and improves query efficiency by collecting statistical information, and supports manual, automatic, and sampling statistical information collection.
Multi-Catalog
Doris constructs a three-layer metadata hierarchy of Catalog -> Database -> Table, providing an internal catalog and external catalog, which is convenient for managing external data sources. For example, after connecting to Hive, users can create a catalog, directly view and switch databases, query table data, perform associated queries, or import and export data.
Conclusion
With its powerful functions, advanced architecture, and core technologies, Doris lakehouse integration provides an efficient and intelligent solution for enterprise data management. In the era of big data, it is like a solid bridge, breaking down the barriers between the data lake and the data warehouse, making data flow more smoothly, releasing more value, and helping enterprises seize the initiative in the wave of digital transformation!
Opinions expressed by DZone contributors are their own.
Comments