Dynamically Provisioning Persistent Volumes With Kubernetes
How to address the persistent storage needs of stateful containerized applications using Kubernetes PVs and Kubernetes PVCs.
Join the DZone community and get the full member experience.
Join For FreeStorage in the Kubernetes and container world is handled differently than it is with virtual machines (VMs) or other types of infrastructure.
Containerized applications typically scale by running multiple instances of containers in parallel. As a result, you have many more containers running at one time than you would VMs, and the lifespan of any given container instance is typically much shorter—minutes or hours. A running VM, by comparison, might persist for weeks or months. While an application is running in a VM often stores data in the VM, that doesn’t make sense given the ephemeral nature of containers.
This blog explains how to address the persistent storage needs of stateful containerized applications using Kubernetes persistent volumes (PVs) and Kubernetes persistent volume claims (PVCs). It also describes how PVs can be provisioned either statically or dynamically.
What Are Persistent Volumes (PVs)?
Stateful applications require data to persist beyond the lifespan of a container instance. Applications often store information for later processing or as a record changes or transactions occur. PVs allows storage volumes to be separate from container instances. A PV is an allocated storage volume within a cluster that has either been provisioned by an administrator or dynamically provisioned using Storage Classes (more on this later).
Kubernetes supports many types of volumes, including both file and block storage. The various storage vendors and cloud providers have created Container Storage Interface (CSI) drivers that enable Kubernetes to take advantage of the features of their underlying storage offerings. Deciding what type(s) of storage your cluster will consume is an important management task taking into consideration static/dynamic provisioning, quality of service (QoS), can easily scale-out, and more.
A PV is a cluster resource similar to other resources in Kubernetes, such as a node, memory (RAM), etc. As with any cluster resources, it can be created via a configuration file written in YAML.
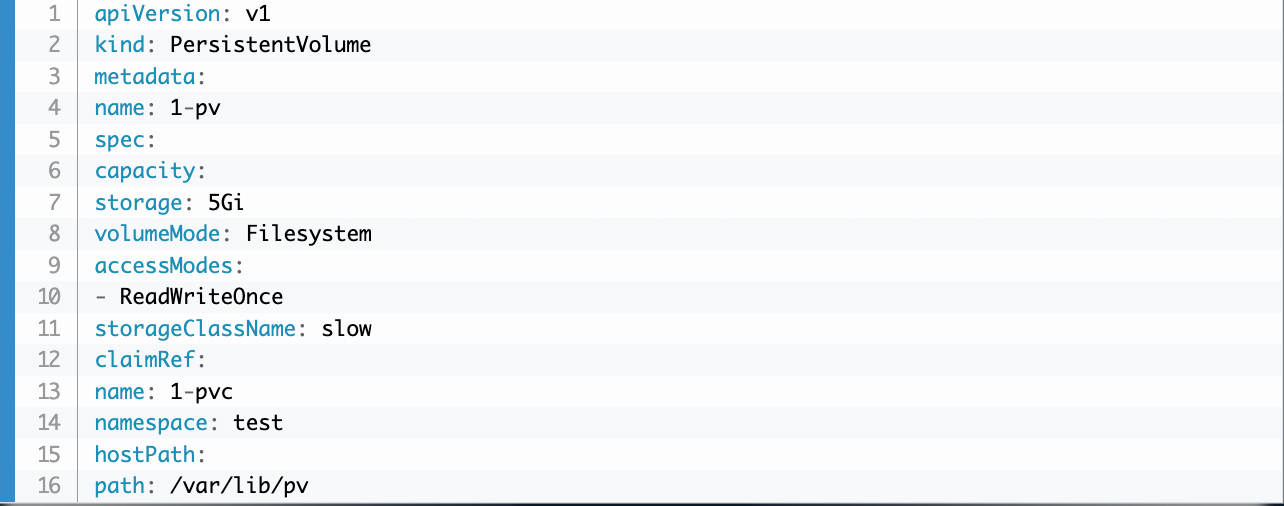
Note that the definition specifies a variety of aspects about the PV, such as its name, capacity, access modes, etc.
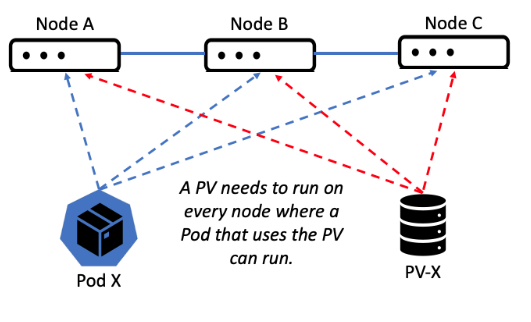
It’s helpful to think about how a simple three-node Kubernetes cluster operates to understand what is expected of a PV. Kubernetes containers run in Pods. During normal operations, Pod X running on Node A might stop and be restarted on Node C or Node B, so any PV it’s associated with (PV-X in the diagram below) will need to be accessible from every node where the Pod can run. Often that means it will need to be accessible on all nodes in the cluster. And, of course, you need to have methods to create PVs and a way for application containers running in pods to consume them.
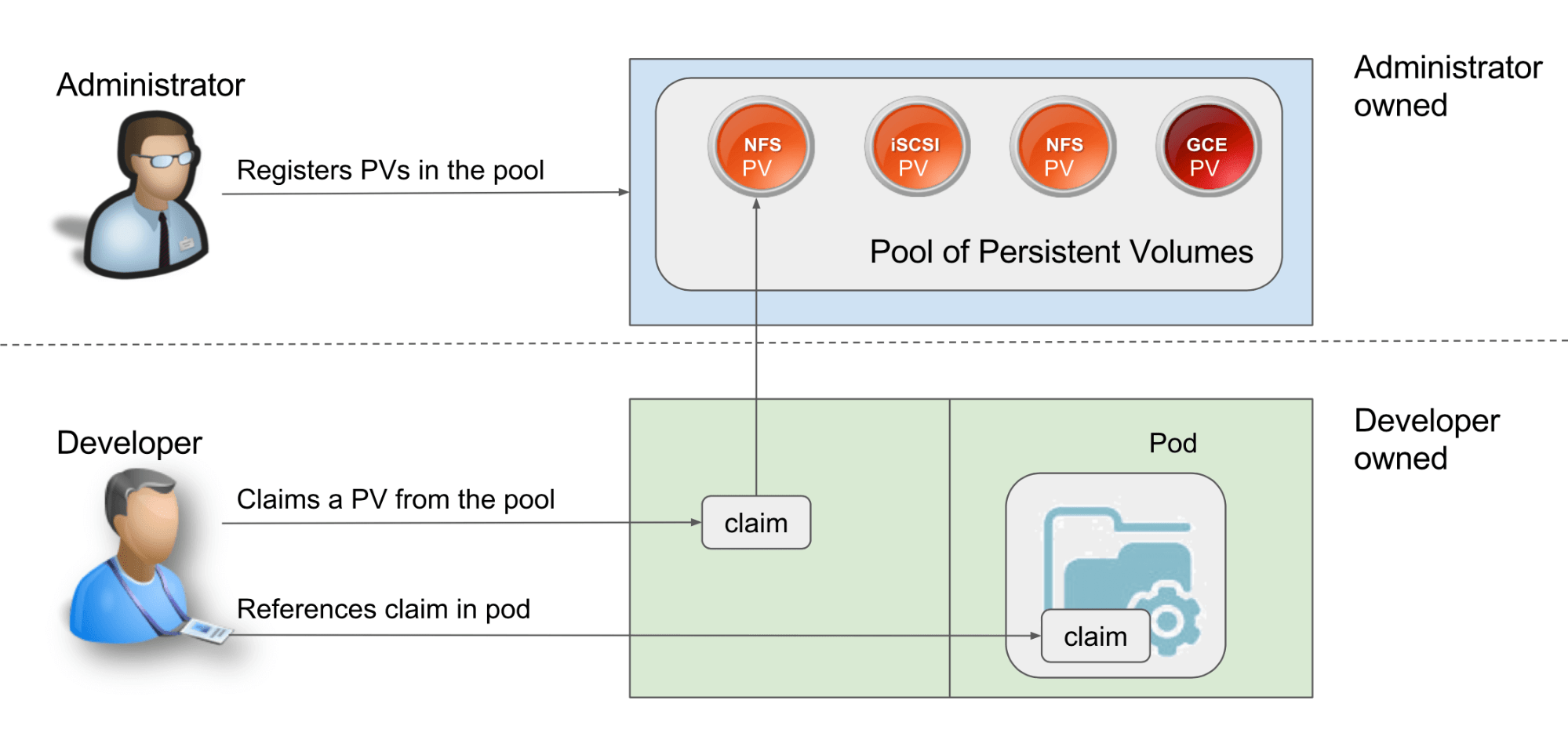
Static PV Provisioning and Persistent Volume Claims
With static provisioning, a Kubernetes admin has to know what persistent volumes developers will need in advance and create those volumes on underlying storage by creating YAML files, as shown above. Once a PV is created, it is accessible via the Kubernetes API and available for consumption.
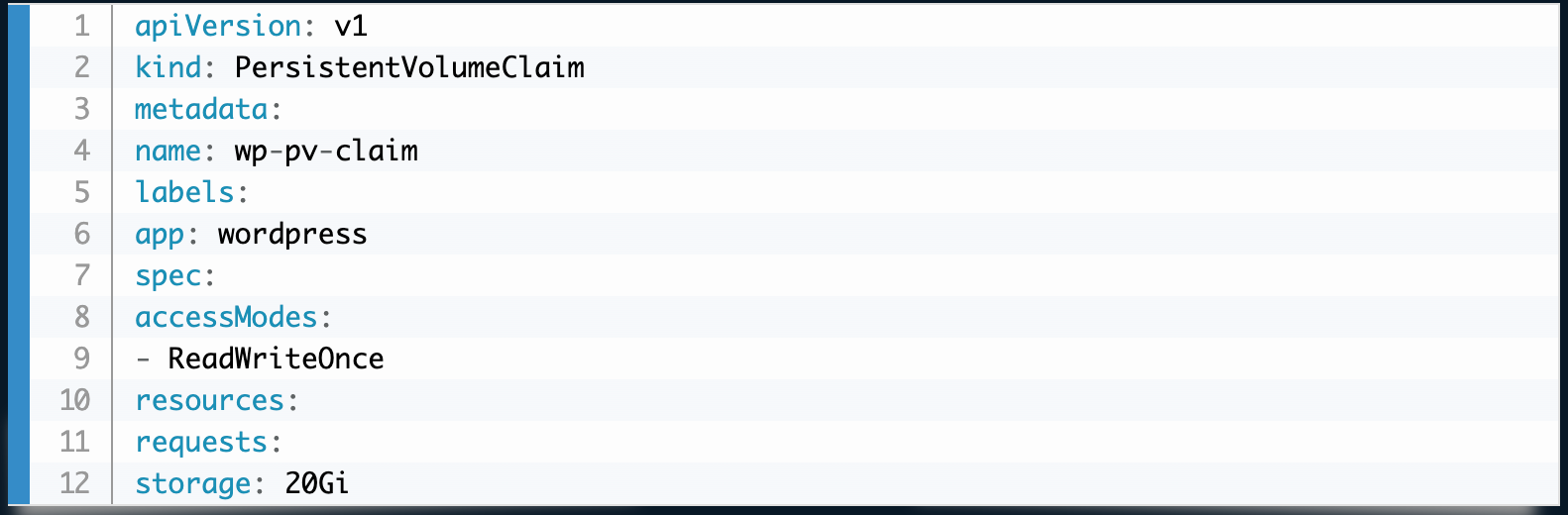
A persistent volume claim (PVC) is a request for a PV. Claims describe the storage required, including a specific name, size, and access modes. A PVC may specify some or all of the parameters of a suitable PV. If Kubernetes finds an available PV that matches the request, the PVC is bound to the PV. The YAML for a PVC might look like the following:
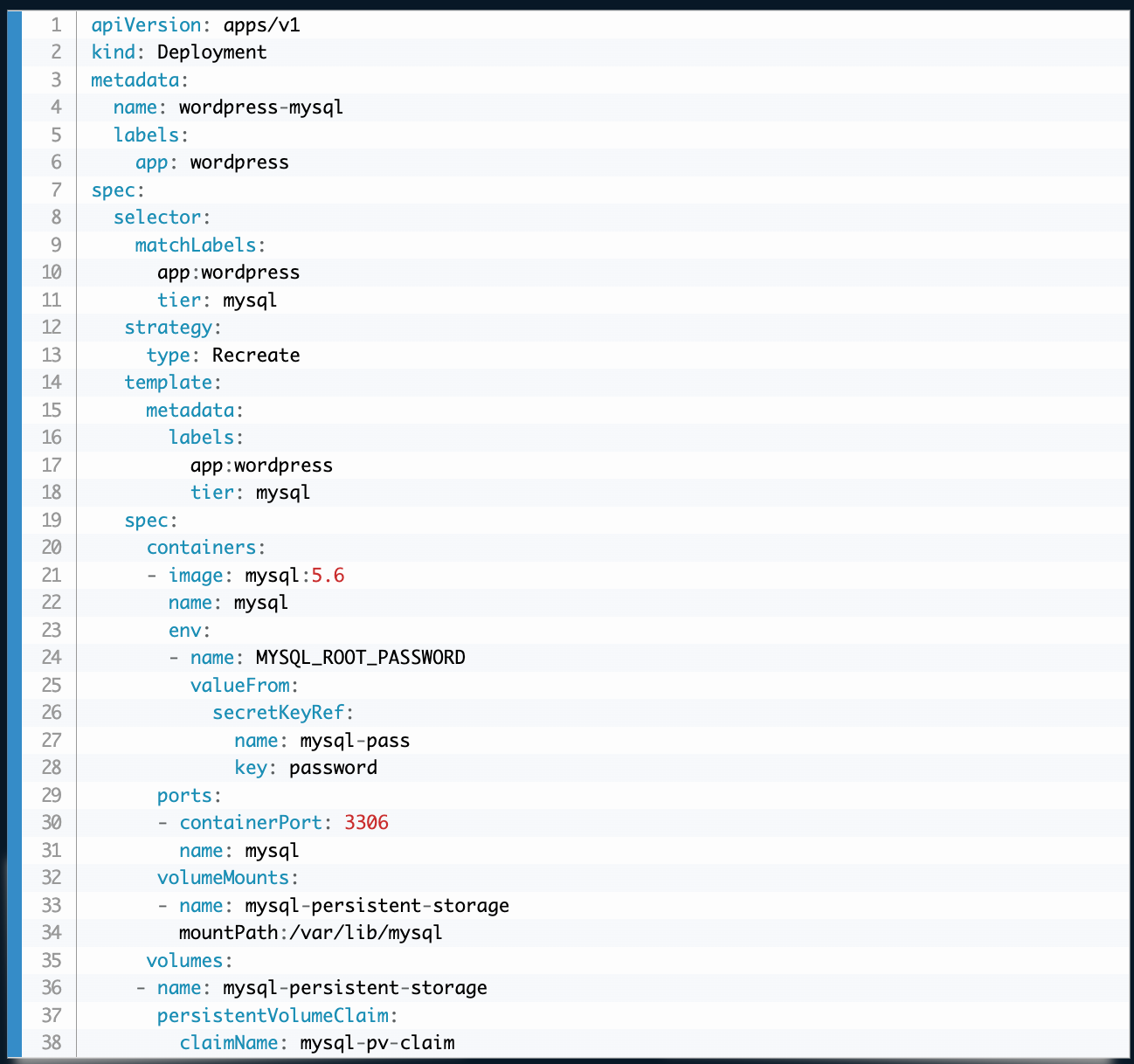
Once the PVC is established, you can then use that claim in your Deployment or Pod specification:
In summary, static PV provisioning requires these steps:
- Kubernetes Admin creates a PV.
- Developer creates a PVC to request storage and claim the PV.
- Developer configures a Pod to use the PV based on the satisfied claim.
Dynamic Provisioning
Static provisioning works okay to a point, but it either requires a lot of guesswork on the part of the administrator (in order to create PVs that applications may need) or a lot of back and forth between developers and admins. As your Kubernetes environment expands, this can become a bottleneck.
Dynamic provisioning solves this problem. Instead of the Kubernetes admin creating specific PVs, the admin defines Storage Classes. Each StorageClass has a particular backend of storage from which PVs can be provisioned automatically to meet an application’s requirements. For example, you might have separate storage classes for block and file storage. Classes can be as fine grained as you want them to be. You could have slow, medium, and fast block storage or classes that are always backed up or never backed up.
To create a StorageClass, the administrator must specify a provisioner and parameters appropriate to that provisioner. For example, Kubernetes has an internal provisioner for AWS EBS (block) storage: kubernetes.io/aws-ebs.
Kubernetes provides a variety of internal provisioners, which are described in the Kubernetes documentation here. External providers are also available or can be created.
With dynamic provisioning, a developer can use a PVC to request a specific storage type and have a new PV provisioned automatically. The PVC must request a StorageClass that has already been created and configured on the target cluster by an admin for dynamic provisioning to work.
Dynamic Provisioning Benefits
There are several benefits from using dynamic provisioning, especially as your operations grow:
- Simplified workflows: Applications provision storage as they need it without constant back and forth between users and admins.
- Reduced cost: The overhead associated with pre-provisioning volumes and managing them is eliminated, and Admins don’t have to manually support developers’ storage needs.
- Reduced storage spending: Dynamic provisioning automatically allocates and deallocates PVs in response to PVCs, reducing waste from storage that is allocated but never used.
- Optimized performance: PVCs are fulfilled dynamically based on StorageClass attributes, so the resulting volume more closely matches the need.
Persistent Volumes and Backup
Kubernetes environments require backups that keep up with the state of your cluster and applications to protect against disaster. If your backups are designed to back up only the PVs you know about, sooner or later, you may miss some. Kubernetes backups should inspect the state of your clusters to find all PVs. Policy-based solutions help ensure that you’re backing up all of your PVs at the right intervals to deliver the desired service level.
Published at DZone with permission of Cliff Malmborg. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments