Edge Computing in Utility IoT: Two Architecture Patterns That Actually Work
In this article, we break down edge architecture patterns that fit modern utility infrastructure when power flows both ways.
Join the DZone community and get the full member experience.
Join For FreeWhen centralized control architectures were designed, power flowed from large generation plants down to passive consumers, utilities managed hundreds of large assets, data volumes were modest, and connectivity was reliable at substations.
Few of these assumptions hold today. Power flows in both directions as rooftop solar and battery storage inject back into the distribution network. Utilities now coordinate millions of small, variable, distributed assets instead of hundreds of large ones. Data volumes have multiplied by orders of magnitude as smart meters, sensors, and distributed energy resource (DER) controllers generate continuous streams.
According to SCE's "Countdown to 2045" analysis, overall electricity demand will nearly double over the next two decades, driven largely by EV adoption, building electrification, and distributed solar. That growth will come from millions of small, distributed resources that centralized systems weren't designed to coordinate.
Going forward, the control architecture should match the grid they're actually operating, not the one they planned for decades ago. This gap is exactly what edge computing addresses.
Why Edge Architecture Fits Utility Environments
Before looking at specific deployment patterns, it helps to understand why edge computing suits utility infrastructure in particular. Three structural characteristics make it the right fit.
Utility data has a locality problem. Sensors, meters, and controllers generate data where decisions need to happen — at the substation, the inverter, the distribution feeder. IEEE 2800-2022 specifies that inverter-based resources must achieve step response times within 2.5 grid cycles OSTI — at 60Hz that's roughly 42 milliseconds. A cloud round-trip often takes longer than that. Edge processing keeps logic where the data originates.

Utility infrastructure has a connectivity problem. The system needs to keep functioning whether or not it can reach the cloud — despite storms, distance, or unreliable networks. For these environments, autonomous edge operation is a baseline requirement.
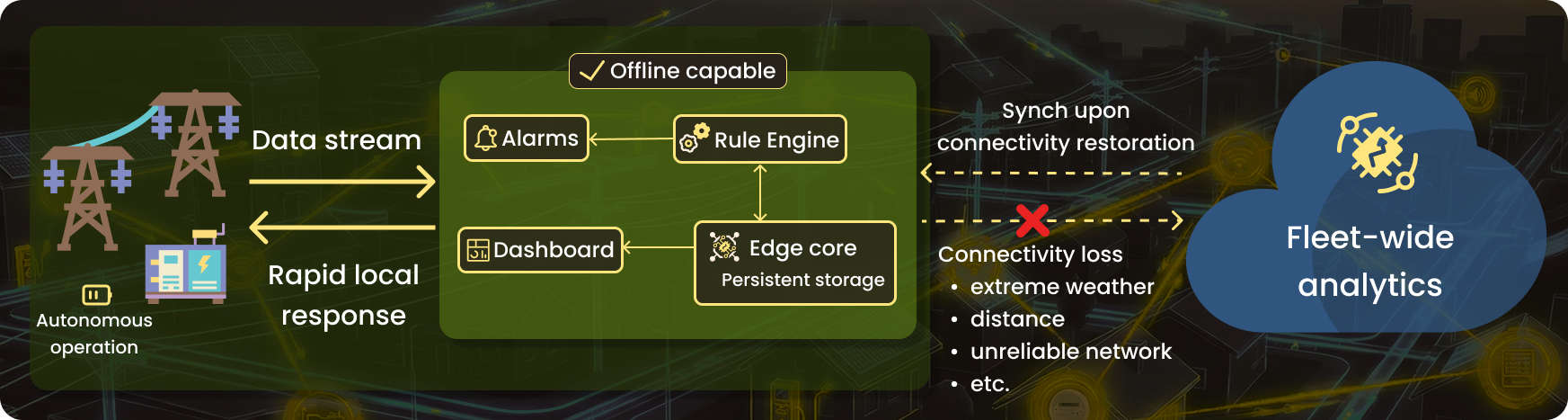
Utility scale has a bandwidth problem. Modern grid sensors generate continuous, high-resolution streams. Transmitting everything to a central system is economically unfeasible at the deployment scale. Edge filtering means only verified anomalies and events travel upstream, not raw sensor streams.
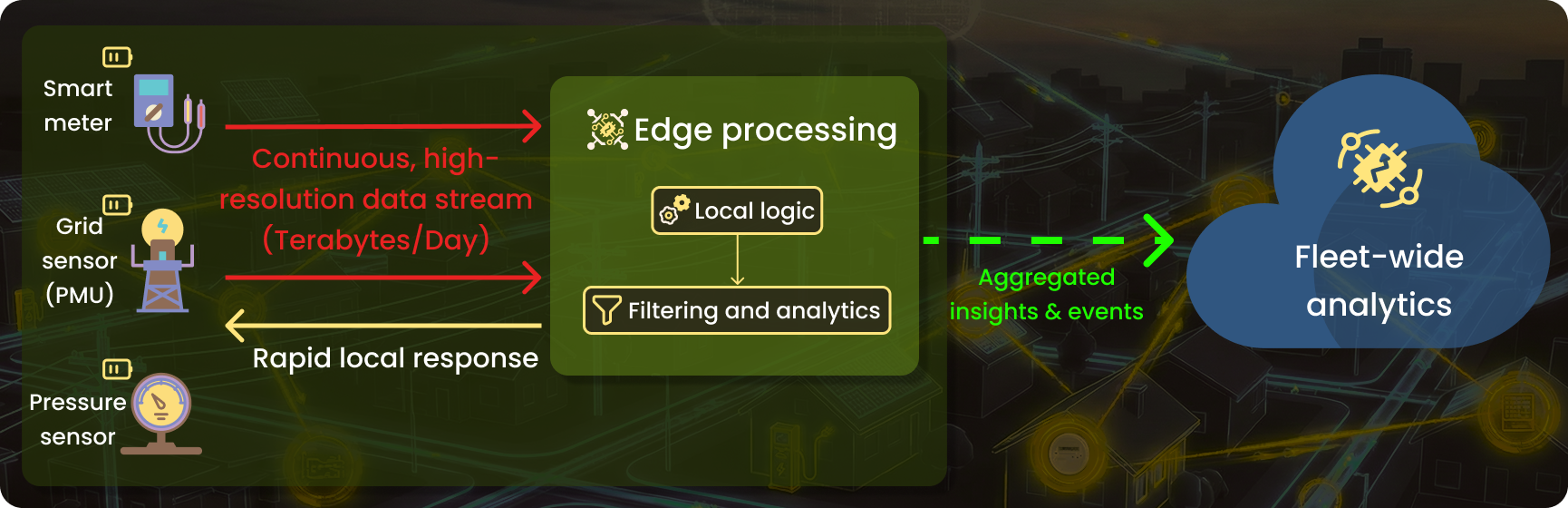
These three characteristics show up in every serious utility IoT deployment. The architecture pattern you choose determines how you address them.
Two Patterns, Different Constraints
Utility edge deployments fall into two fundamentally different patterns. Which one you're deploying determines your hardware, protocol, and AI strategy.
Pattern A: High-Frequency Control Loops
This pattern applies when the system needs to detect grid conditions and respond within milliseconds — DER coordination, voltage regulation, frequency response, fault detection. The key difference is that the control decisions are made by the device itself, not a gateway or central system.
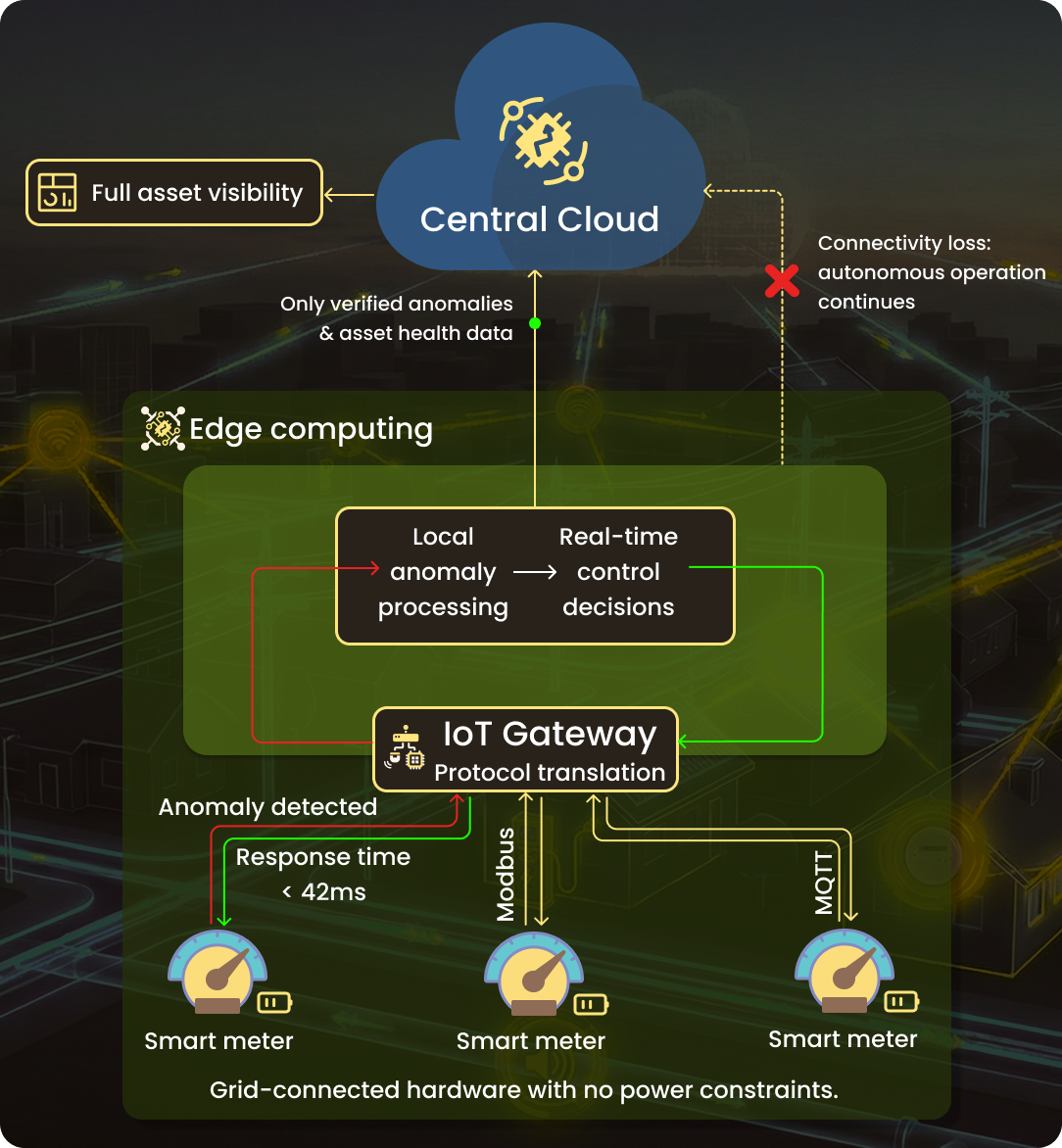
The Utilidata deployment with Southern California Edison and NVIDIA embedded computing directly into smart meters using NVIDIA's Jetson platform, running Real-Time Optimal Power Flow (RT-OPF) algorithms at the meter. Solar inverters, EV chargers, and battery systems responded to actual grid conditions measured locally, not static dispatch schedules. The published results: 27% reduction in peak demand and 12.5% reduction in electricity costs for the simulated household.
This is a meaningful architectural difference that only works with grid-connected hardware with sufficient compute power and no battery constraints.
Pattern B: Distributed Sensor Networks
This pattern applies when deploying hundreds or thousands of battery-powered sensors across a wide geographic area. The data is being captured periodically, processed locally, and transmitted only when something meaningful is detected.
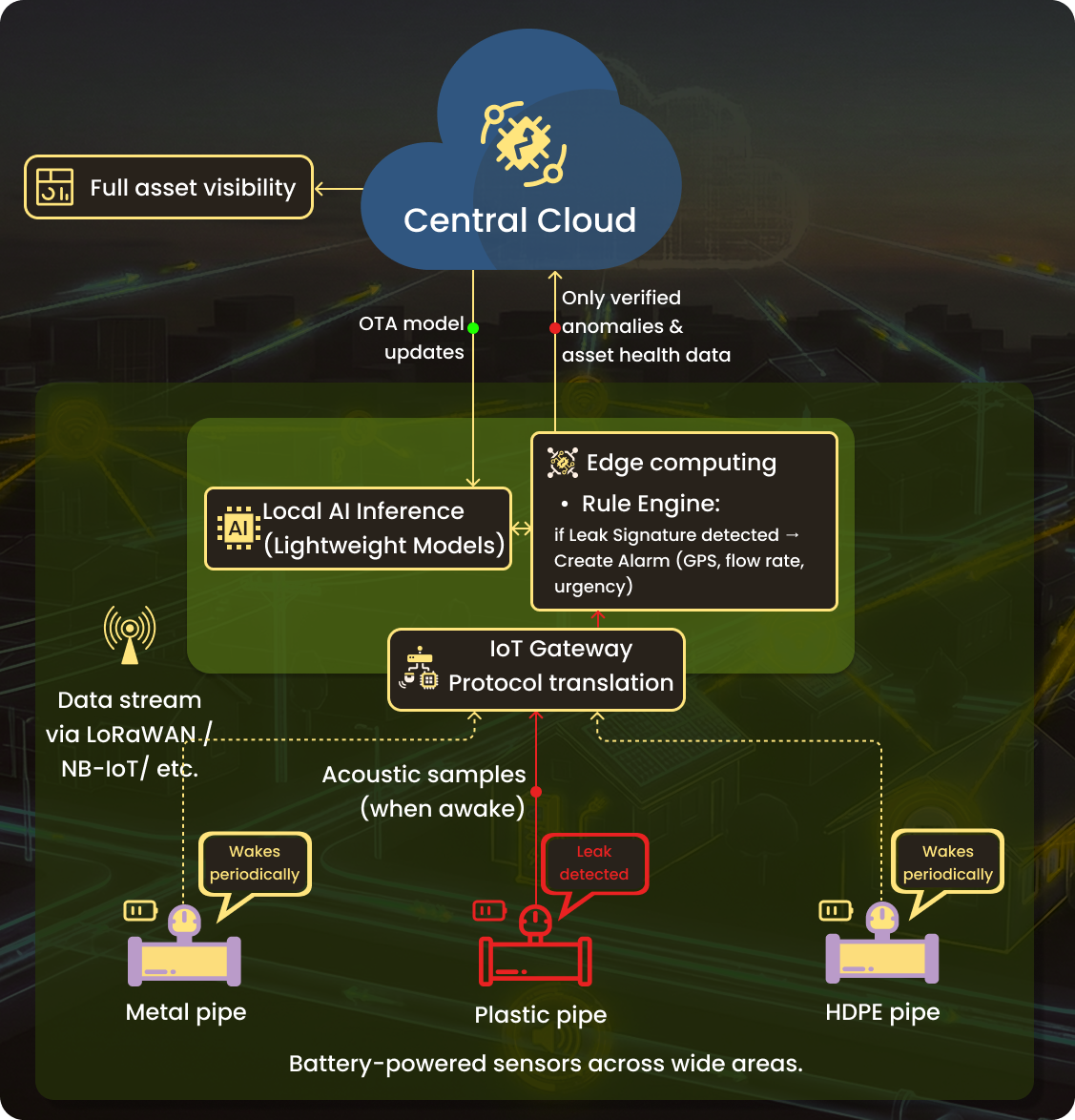
EPCOR's acoustic leak detection deployment across 160 square miles of desert water infrastructure in Arizona demonstrates this. Battery-powered sensors attach directly to water pipes, wake periodically to capture acoustic samples, run local AI inference to detect leak signatures, and transmit only when an anomaly matches trained patterns. The system identified over 250 leaks and helped recover 115 million gallons of water. The results would be economically impossible if sensors were streaming continuous audio to the cloud.
Every computation and transmission drains limited energy, yet sensors must run on batteries for years. AI models must be lightweight enough to run within milliwatt budgets while still being accurate enough to distinguish a genuine leak signature from pipe noise.
Protocol and Hardware Decisions Follow the Pattern
Once you know which pattern applies, hardware and protocol choices follow directly.
For control loop deployments (Pattern A), hardware is typically grid-connected — gateways at substations, computing embedded in meters or inverters. Protocol selection centers on what your existing field devices speak: Modbus for legacy equipment, IEC 61850 for modern substations, DNP3 for SCADA-connected devices, MQTT for newer IoT sensors. A single-edge gateway must collect from all of these simultaneously.
For sensor network deployments (Pattern B), hardware is battery-constrained, and the protocol choice is driven by range and power requirements. LoRaWAN achieves 15km range with years of battery life at the cost of low data throughput and is the common choice for large geographic areas. NB-IoT provides better penetration in dense or underground environments using cellular infrastructure. LoRaWAN requires a gateway deployment. NB-IoT runs on existing cellular coverage but introduces carrier dependency and ongoing SIM costs. Neither protocol is universally better. The choice depends on service area geography, existing cellular coverage, deployment density, and battery budget.
ThingsBoard Edge supports protocol diversity through the IoT Gateway component. It connects to Modbus and OPC-UA out of the box, along with MQTT for modern IoT sensors. For low-power wide-area protocols like LoRaWAN and NB-IoT, ThingsBoard integrations enable connectivity without custom middleware. This allows utilities to deploy either pattern — or both — on unified infrastructure.
AI at the Edge: Two Execution Strategies
Both patterns differ based on hardware constraints.
Pattern A gateways have enough compute to query external AI services when connected — OpenAI, Azure OpenAI, or a self-hosted model via API — and switch to cached local models when the connection drops. This approach keeps models updated centrally without hardware constraints limiting model complexity.
For Pattern B deployments, models must run locally within tight power and memory budgets. The EPCOR deployment uses deep learning models trained on extensive plastic pipe acoustic datasets, optimized to run directly on the sensor hardware. Every percentage point of detection accuracy improvement must be weighed against battery life — a more complex model might cut operational lifespan in half.
Either way, managing AI models across a distributed fleet requires automation. Utilities can't manually update inference logic on hundreds of field-deployed devices. Modern edge platforms solve this with central model repositories and OTA update pipelines. Engineers train on historical data, check results, and push updates to the whole device fleet during scheduled maintenance — no truck rolls, no downtime.
Integration With Existing Infrastructure
The most common engineer concern about edge computing isn't the technology — it's disruption to working systems. Replacing functional SCADA infrastructure mid-operation isn't realistic for most utilities, and it isn't necessary.
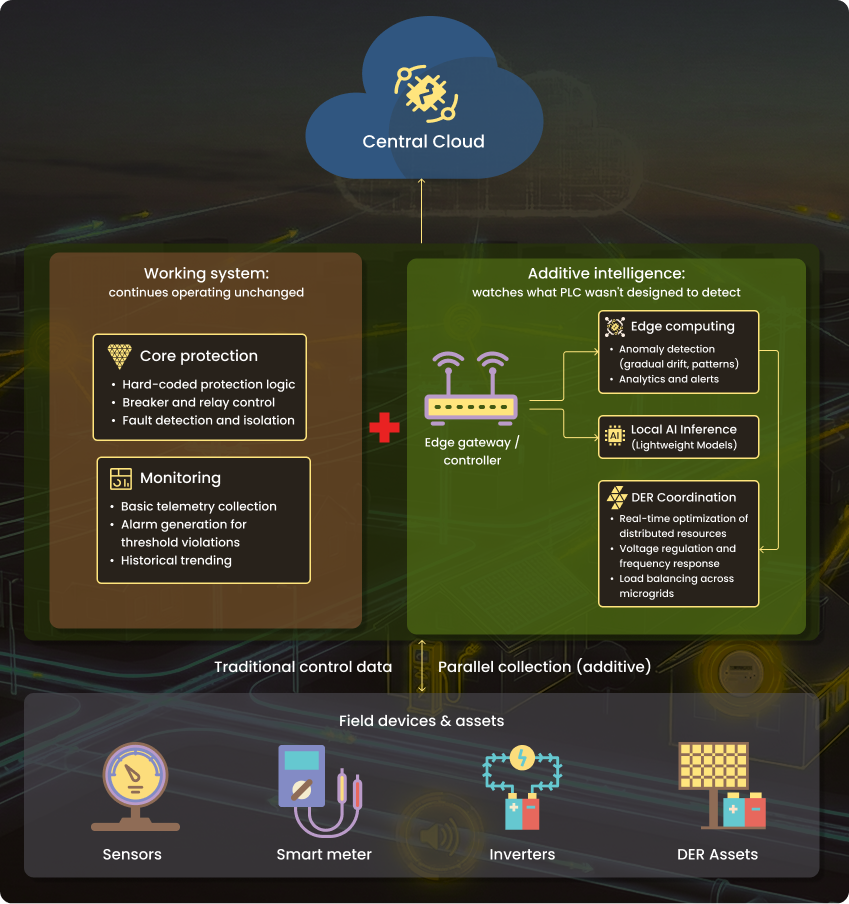
The practical integration approach is additive rather than replacement. Deploy an edge gateway alongside your existing PLC or RTU. It connects to the network, collects data from field devices via the protocols they already speak, and runs additional intelligence — anomaly detection, pattern recognition, predictive alerts — without touching the control loop. Your existing PLC continues executing hard-coded protection logic. The edge layer watches for conditions the PLC wasn't designed to detect.
This matters for DER management specifically. Existing SCADA systems weren't architected for thousands of bidirectional resources that both consume and inject power based on real-time conditions. Rather than rebuilding that SCADA layer, an edge platform can sit alongside it, handling the DER coordination layer while SCADA continues managing the assets it was built for.
Energenix, a renewable energy SCADA provider operating across South Asia, takes exactly this approach using ThingsBoard Edge. The platform delivers local monitoring and control at solar plant sites, enabling operational staff to respond to events without cloud dependency, while the central ThingsBoard instance handles fleet-wide analytics and long-term storage across their 120+ MW portfolio spanning multiple countries.
Managing hundreds of sites requires visibility into the fleet itself, not just the grid assets it monitors: battery levels, communication timestamps, firmware versions, health status. Edge platforms provide centralized dashboards for this fleet-wide visibility while edge nodes maintain autonomous operation. Over-the-air update pipelines push firmware and model updates to device groups from a central interface — no SSH sessions, no truck rolls.
Choosing Where to Start
For utilities evaluating edge computing deployments, the clearest starting point is identifying which pattern your highest-priority use case falls into, then running a contained pilot before fleet deployment.
If your primary concern is DER coordination and real-time grid response, Pattern A applies — start with a single substation or feeder and measure latency improvements against your current SCADA response baseline.
If your primary concern is infrastructure monitoring across a wide service area with connectivity constraints, Pattern B applies — start with a single sensor deployment zone, validate detection accuracy, then scale the fleet.
The platform infrastructure — protocol integration, rule engine, OTA management, centralized dashboards — should be the same regardless of which pattern you start with. Utilities that deploy both patterns eventually need them to coexist under unified management. Building on a platform that handles both from day one avoids painful integration work later.
Opinions expressed by DZone contributors are their own.
Comments