ELT Is Dead, and EtLT Will Be the End of Modern Data Processing Architecture
In this article, discuss why EtLT is gradually replacing ETL and ELT as the global mainstream data processing architecture.
Join the DZone community and get the full member experience.
Join For FreeLet’s explore the reasons behind the emergence of these architectures, their strengths and weaknesses, and why EtLT is gradually replacing ETL and ELT as the global mainstream data processing architecture, along with practical open-source methods.
ETL Era (1990–2015)
In the early days of data warehousing, Bill Inmmon, the proponent of data warehousing, defined it as a data storage architecture for partitioned subjects, where data was categorized and cleaned during storage. During this period, most data sources were structured databases (e.g., MySQL, Oracle, SQLServer, ERP, CRM), and data warehouses predominantly relied on OLTP databases (e.g., DB2, Oracle) for querying and historical storage. Handling complex ETL processes with such databases proved to be challenging. To address this, a plethora of ETL software emerged, such as Informatica, Talend, and Kettle, which greatly facilitated integrating complex data sources and offloading data warehouse workloads.
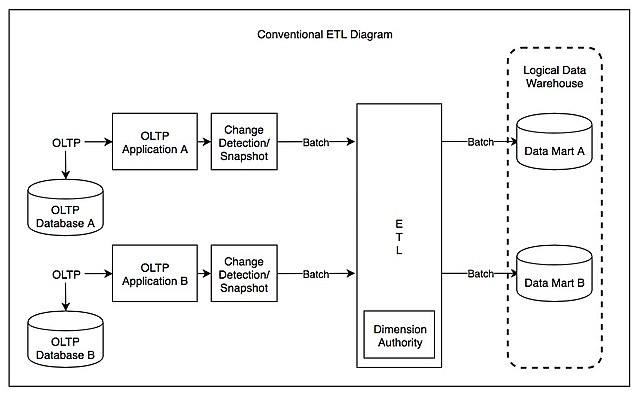
- Advantages: Clear technical architecture, smooth integration of complex data sources, and about 50% of the data warehouse work handled by ETL software.
- Disadvantages: All processing is done by data engineers, leading to longer fulfillment of business requirements; high hardware costs with double investments, especially when dealing with large data volumes.
During the early and mid stages of data warehousing, when data source complexity was significantly higher, the ETL architecture became the industry standard and remained popular for over two decades.
ELT Era (2005–2020)
As data volumes grew, both data warehouse and ETL hardware costs escalated. New MPP (Massively Parallel Processing) and distributed technologies emerged, leading to the gradual shift from ETL to ELT architecture in the later stages of data warehousing and the rise of big data. Teradata, one of the major data warehouse vendors, and Hadoop Hive, a popular Hadoop-based data warehousing solution, adopted ELT architecture. They focused on direct loading (without complex transformation like join and group) of data into the data warehouse’s data staging layer, followed by further processing using SQL or H-SQL from the staging layer to the data atomic layer and finally to the summary layer and indicator layer. While Teradata targeted structured data and Hadoop targeted unstructured data, they adopted similar 3–4 layer data storage architectures and methodologies for data warehousing globally.
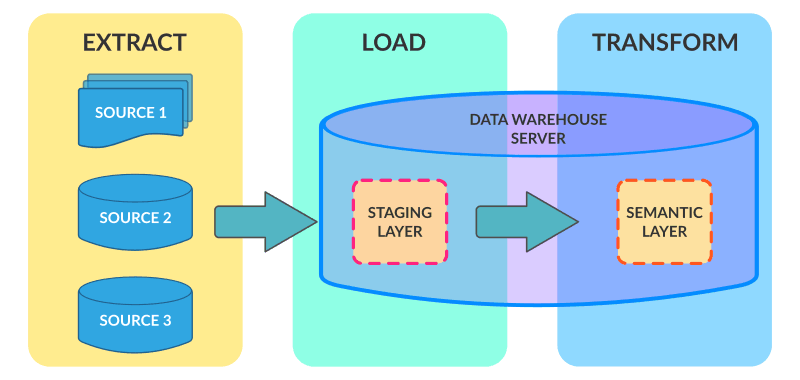
- Advantages: Utilizing data warehouse high-performance computing for large data volume processing, resulting in higher hardware ROI. Complex business logic can be handled by SQL, reducing the overall cost of data processing personnel by employing data analysts and business-savvy technical personnel, without the need to understand ETL tools like Spark and MapReduce.
- Disadvantages: Suitable for simple and large data volume scenarios. Inadequate for complex data sources and lacking support for real-time data warehousing requirements.
ODS (Operational Data Store) was introduced as a transitional solution to handle complex data sources that ELT-based data warehouses couldn’t load and to improve real-time capabilities. ODS involved processing complex data sources through real-time CDC (Change Data Capture), real-time APIs, or short-batch processing (Micro-Batch) into a separate storage layer before ELT-ing them into the enterprise data warehouse. Currently, many enterprises still adopt this approach. Some companies place the Operational Data Store (ODS) within the data warehouse and use Spark and MapReduce for initial ETL (Extract, Transform, Load) processes. Later, they perform business data processing within the data warehouse (using tools like Hive, Teradata, Oracle, and DB2).
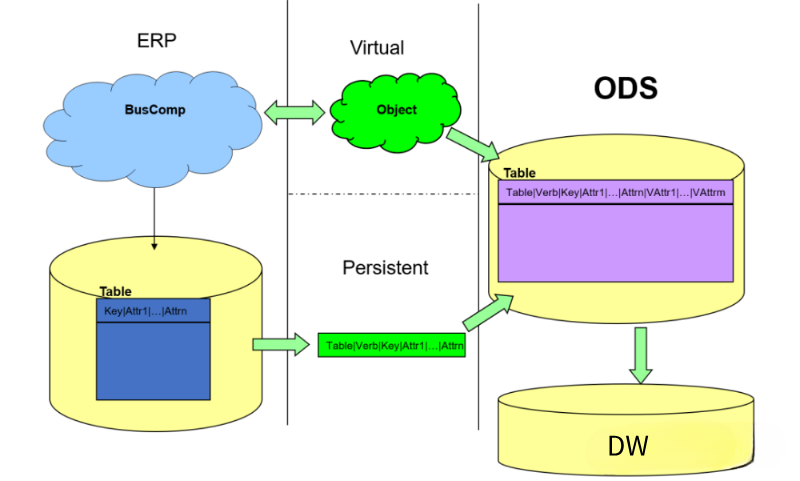
At this stage, the early EtLT (Extract, Transform, Load, and Transform) community has already formed. It is characterized by a division of roles, where the complex processes of data extraction, Change Data Capture (CDC), data structuring, and standardization are often handled by data engineers, referred to as “t.” Their objective is to move data from the source system to the underlying data preparation layer or data atomic layer within the data warehouse. On the other hand, the processing of complex data atomic layers with business attributes, data aggregation, and generating data metrics (involving operations such as Group by and Join) is typically performed by business data engineers or data analysts who are skilled in using SQL.
As a result of the emergence of the EtLT architecture, standalone projects like ODS have gradually faded out of the limelight due to the increase in data volume and the adoption of EtLT principles.
EtLT Era (2020-Present)
The EtLT architecture, as summarized by James Densmore in the Data Pipelines Pocket Reference 2021, is a modern and globally popular data processing framework. EtLT emerged in response to the transformations in the modern data infrastructure.
Background of the EtLT Architecture
The modern data infrastructure has the following characteristics, which led to the emergence of the EtLT architecture:
- Cloud, SaaS, and Hybrid Local Data Sources
- Data Lake and Real-time Data Warehouses
- New Generation Big Data Federation Proliferation of AI Applications
- Fragmentation of Enterprise Data Community
The Appearance of Complex Data Sources
In the current global enterprise landscape, the advent of cloud and SaaS has made an already complex data source environment even more intricate. Dealing with SaaS data has given rise to a new concept of data ingestion, exemplified by tools like Fivetran and Airbyte, aiming to address the ELT (Extract, Load, Transform) challenges of ingesting SaaS data into data warehouses like Snowflake. Additionally, the complexity of data sources has increased with the proliferation of cloud-based data storage services (e.g., AWS Aurora, AWS RDS, MongoDB Service) and the coexistence of traditional on-premises databases and software (SAP, Oracle, DB2) in hybrid cloud architectures. Traditional ETL and ELT architectures are unable to cope with the intricacies of processing data in such a complex environment.
Data Lake and Real-Time Data Warehouses
In modern data architecture, the emergence of data lakes has combined the features of traditional ODS (Operational Data Store) and data warehouses. Data lakes enable real-time data processing and facilitate data changes at the source (e.g., Apache Hudi, Apache Iceberg, Databricks Delta Lake). Simultaneously, the concept of real-time data warehouses has surfaced, with various new computing engines (e.g., Apache Pinot, ClickHouse, Apache Doris) making real-time ETL a priority. However, traditional CDC ETL tools or real-time stream processing platforms face challenges in providing adequate support for data lakes and real-time data warehouses, either due to compatibility issues with new storage engines or limitations in connecting to modern data sources, lacking robust architecture and tool support.
The Emergence of a New Generation of Big Data Federation
In modern data architecture, a new breed of architectures has emerged, aiming to minimize data movement across different data stores and enabling complex queries directly through connectors or rapid data loading. Examples include Starburst’s TrinoDB (formerly PrestoDB) and OneHouse based on Apache Hudi. These tools excel at data caching and on-the-fly cross-data-source queries, making them unsuitable for support by traditional ETL/ELT tools in this new Big Data Federation paradigm.
The Rise of Large-Scale Models
With the emergence of ChatGPT in 2022, AI models have become algorithmically feasible for widespread enterprise applications. The bottleneck for AI application deployment now lies in data supply, which has been addressed by data lakes and Big Data Federation for data storage and querying. However, traditional ETL, ELT, and stream processing have become bottlenecks for data supply, either unable to quickly integrate various complex traditional and emerging data sources or failing to support diverse data requirements for both AI training and online AI applications using a single codebase.
Fragmentation of the Enterprise Data Community
As data-driven approaches become more ingrained in enterprises, the number of data users within organizations has rapidly increased. These users range from traditional data engineers to data analysts, AI practitioners, sales analysts, and financial analysts, each with diverse data requirements. After experiencing various shifts like No-SQL and New-SQL, SQL has emerged as the sole standard for complex business analysis. A considerable number of analysts and business unit engineers now use SQL to address the “last mile” problem of data analysis within enterprises. Meanwhile, the handling of complex unstructured data is left to professional data engineers using technologies like Spark, MapReduce, and Flink. Consequently, the demands of these two groups diverge significantly, making traditional ETL and ELT architectures inadequate to meet the needs of modern enterprise users.
EtLT Architecture Emerges!
Against the backdrop mentioned above, data processing has gradually evolved into the EtLT architecture:
EtLT Architecture Overview:
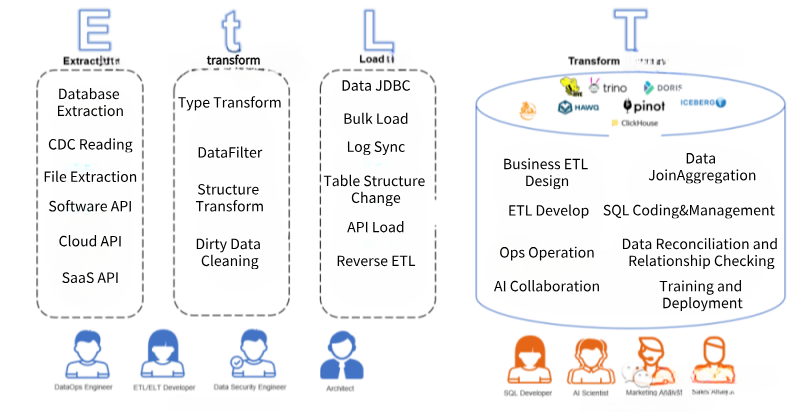
EtLT splits the traditional ETL and ELT structures and combines real-time and batch processing to accommodate real-time data warehouses and AI application requirements.
- E(xtract) — Extraction: EtLT supports traditional on-premises databases, files, and software as well as emerging cloud databases, SaaS software APIs, and serverless data sources. It can perform real-time CDC on database binlog and real-time stream processing (e.g., Kafka Streaming) and also handle bulk data reading (multi-threaded partition reading, rate limiting, etc.).
- t(ransform) — Normalization: In addition to ETL and ELT, EtLT introduces a small “t,” focusing on data normalization. It rapidly converts complex and heterogeneous extracted data sources into structured data that can be readily loaded into the target data storage. It deals with real-time CDC by splitting, filtering, and changing field formats, supporting both batch and real-time distribution to the final Load stage.
- L(oad) — Loading: The loading stage is no longer just about data loading but also involves adapting data source structures and content to suit the target data destination (Data Target). It should handle data structure changes (Schema Evolution) in the source and support efficient loading methods such as Bulk Load, SaaS loading (Reverse ETL), and JDBC loading. EtLT ensures support for real-time data and data structure changes, along with fast batch data loading.
- (T)ransform — Conversion: In cloud data warehouses, on-premises data warehouses, or new data federations, business logic is processed. This is typically achieved using SQL, either in real-time or batch mode, to transform complex business rules accurately and quickly into data usable by business or AI applications.
In the EtLT architecture, different user roles have distinct responsibilities:
- EtL Phase: Primarily handled by data engineers who convert complex and heterogeneous data sources into data that can be loaded into the data warehouse or data federation. They do not need to have an in-depth understanding of enterprise metric calculation rules but must be proficient in transforming various source and unstructured data into structured data. Their focus is on data timeliness and the accuracy of transforming source data into structured data.
- T Phase: Led by data analysts, business SQL developers, and AI engineers who possess a deep understanding of enterprise business rules. They convert business rules into SQL statements to perform analysis and statistics on the underlying structured data, ultimately achieving data analysis within the enterprise and enabling AI applications. Their focus is on data logic relationships, data quality, and meeting business requirements for final data results.
Open-Source Implementation of EtLT
There are several open-source implementations of EtLT in modern data architecture. Examples include DBT, which helps analysts and business developers quickly develop data applications based on Snowflake, and Apache DolphinScheduler, a visual workflow orchestration tool for big data tasks. DolphinScheduler plans to introduce a Task IDE, allowing data analysts to directly debug SQL tasks for Hudi, Hive, Presto, ClickHouse, and more and create workflow tasks through drag-and-drop.
As a representative of the EtLT architecture, Apache SeaTunnel started with support for various cloud and on-premises data sources, gradually expanding its capabilities to include SaaS and Reverse ETL, as well as accommodating the demands of large-scale model data supply. It has been continually refining the EtLT landscape. The latest SeaTunnel Zeta computing engine delegates complex operations such as Join and Groupby to the ultimate data warehouse endpoint, focusing on data normalization and standardization. This approach aims to achieve the goal of unified real-time and batch data processing with a single set of code and a high-performance engine. Additionally, SeaTunnel now includes support for large-scale models, making it possible for these models to directly interact with over 100 supported data sources, ranging from traditional databases to cloud databases and, ultimately, SaaS.
Since joining the Apache Incubator in late 2022, Apache SeaTunnel has witnessed a five-fold growth in one year, and currently, it supports more than 100 data sources. The connector support has been progressively improved, encompassing traditional databases, cloud databases, and SaaS offerings.
The release of SeaTunnel Zeta Engine in Apache SeaTunnel 2.3.0 brings features such as data distributed CDC, schema evolution for target source data tables, and the synchronization of entire databases and multiple tables. Its excellent performance has garnered attention from numerous global users, including Bharti Airtel, the second-largest telecommunications operator in India, Shopee.com, an e-commerce platform in Singapore, and Vip.com, a major online retailer.
Large-Scale Model Training Support
One noteworthy aspect is that SeaTunnel now offers support for large-scale model training and vector databases, enabling seamless interactions between large models and the 100+ supported data sources of SeaTunnel. Furthermore, SeaTunnel can leverage ChatGPT to directly generate SaaS Connectors directly, facilitating rapid access to a wide range of internet information for your large-scale models and data warehouses.
As the complexity of AI, cloud, and SaaS continues to increase, the demand for real-time CDC, SaaS, data lakes, and real-time data warehouse loading has made simple ETL architectures inadequate to meet the needs of modern enterprises. EtLT architecture, tailored for different stages of enterprise development, is destined to shine in the modern data infrastructure. With the mission of “Connecting the world’s data sources and synchronizing them as swiftly as flying,” Apache SeaTunnel warrants the attention of all data professionals.
Published at DZone with permission of Zongwen Li. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments