Building Analytics Architectures to Power Real-Time Applications
In this article, we will explore how to build an efficient and cost-effective analytical architecture that can serve the real-time needs of applications.
Join the DZone community and get the full member experience.
Join For FreeIn today's fast-paced digital landscape, businesses are increasingly reliant on data-driven decision-making and real-time insights to gain a competitive edge. The ability to extract actionable information from data has become a crucial factor in driving innovation, optimizing processes and enhancing user experiences. However, the demand for real-time insights doesn't negate the importance of offline analytics architectures, which play a fundamental role in preparing and enhancing data before it's ready for real-time application. In this article we will explore how to build an efficient and cost-effective analytical architecture that can serve the real-time needs of applications.
Understanding the Role of Offline Analytics
Offline analytics involves the process of collecting, processing and analyzing large volumes of data in a batch manner, often over longer time frames. This contrasts with real-time analytics, which focuses on analyzing data as it's generated, with immediate results. While real-time analytics offer the advantage of rapid insights, offline analytics provide the foundation upon which these insights are built. Offline analytics architectures are designed to handle vast datasets, cleanse and transform the data, and generate aggregated results that can later be leveraged in real-time applications.
Benefits of Offline Analytics Architectures
Power of Big Data
Harnessing vast datasets enables the extraction of more profound insights, facilitates the formulation of enhanced strategies, and permits the implementation of precise interventions that surpass the limitations of real-time systems constrained by smaller datasets.
Data Cleansing and Transformation
Raw data often requires cleaning and transformation before it's suitable for analysis. Offline analytics architectures allow organizations to preprocess data at their own pace, ensuring that it's accurate, consistent, and properly structured for later use in real-time applications.
Complex Processing
Some analytics tasks involve computationally intensive operations such as advanced statistical analyses, machine learning training, or simulations. Offline architectures provide the necessary computing resources and time to perform these tasks thoroughly and accurately.
Historical Analysis
To identify trends, patterns, and anomalies, historical data analysis is crucial. Offline analytics allow organizations to analyze historical data retrospectively, revealing insights that might not be immediately evident from real-time analysis alone.
Cost Efficiency
Real-time data processing can be expensive due to the need for high-speed data pipelines and processing power. Offline analytics can often be performed on cost-effective infrastructure, reducing the overall operational expenses.
Real-time Use Cases that Benefit from Offline Architectures
Real-time applications experience a significant boost when real-time analytics seamlessly intertwine with insights derived from offline architectures. For instance, in e-commerce, real-time recommendations rely on immediate behavior, but by incorporating historical data through offline architectures, suggestions become more refined, understanding long-term preferences and trends. Similarly, in healthcare, real-time patient monitoring informs immediate decisions while coupling this data with historical records via offline analytics unveils patterns and trends that contribute to better patient care and disease prevention. Likewise, supply chains achieve operational efficiency by tracking real-time shipments, while offline analytics applied to historical data offer optimization opportunities through supplier trend analysis and demand fluctuations.
Furthermore, energy management benefits from real-time monitoring, and offline analysis leverages historical energy consumption data to devise predictive sustainability strategies. The insights garnered from real-time sentiment analysis and engagement metrics on social media platforms blend with the retrospective analysis of past campaigns through offline analytics, refining effective long-term social media strategies. Additionally, integrating real-time sensor data from smart cities with historical urban development information via offline analytics empowers city planners to make informed decisions regarding infrastructure development, zoning regulations, and resource allocation to ensure sustainable growth. This amalgamation of real-time analytics with offline insights facilitates comprehensive decision-making, resource optimization, and effective long-term strategic planning across various scenarios.
Building an Offline Analytics Architecture
This architectural framework involves the systematic collection, processing, and analysis of data in a batch manner. The process commences with data collection from diverse sources, followed by ingestion pipelines to clean, transform, and enrich the data for storage in repositories like data lakes or warehouses. After storage, the data moves into the analytics and insights phase before being prepped for visualization.
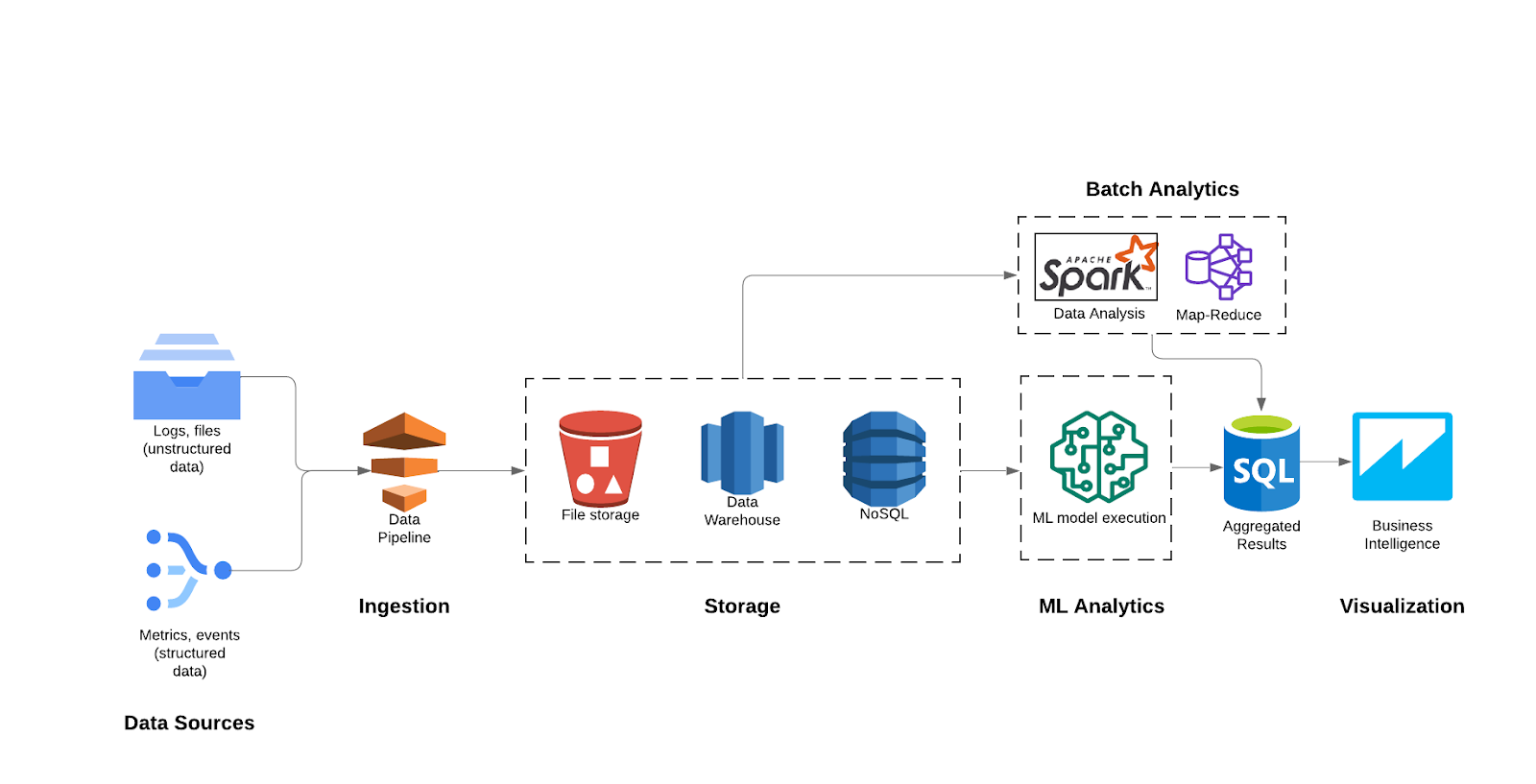
- Data Collection: Gather data from various sources, such as databases, logs, APIs, and external data providers. This data can be raw and unstructured, needing initial processing.
- Ingestion: This step includes data cleansing, transformation, and enrichment on the ingested data.
- Storage: Store collected data in a data lake or a data warehouse. These platforms offer scalable storage and can accommodate diverse data formats.
- Batch Analytics: Run batch analytics jobs using distributed data processing frameworks like Apache Hadoop or Apache Spark to process data in parallel. These jobs could involve running complex algorithms, predictive modeling, and generating reports.
- ML Training: ML training is an alternate path that can be taken if desired. It comprises of prepping the model and training it.
- Visualization: Store the results of batch analytics in a format suitable for real-time consumption. This could be in a database optimized for query speed or a caching layer.
Tools for Implementing Analytical Architectures
Constructing effective analytical architectures necessitates a toolkit of potent instruments that seamlessly gather, process, analyze, and visualize data. Key players in this realm include Apache Kafka, a distributed event streaming platform adept at handling real-time data streams, and Apache NiFi, an open-source integration tool facilitating smooth data flow orchestration. Data storage options span Amazon S3 for efficient object storage and the distributed Hadoop Distributed File System (HDFS). Databases such as Apache Cassandra deliver scalability, while Google BigQuery offers serverless SQL analytics.
For data processing, Apache Spark excels in distributed analytics across batch and real-time contexts, complemented by Apache Flink, catering to high-throughput stream processing. Apache Beam offers a unified model for versatile data pipelines. In the visualization and business intelligence domain, Tableau, Power BI, and Looker empower dynamic insights.
Python libraries like NumPy, Pandas, and sci-kit-learn support advanced analytics alongside frameworks like TensorFlow and PyTorch. Platforms like Collibra and Alation ensure effective data governance. Talend and Informatica stand out for ETL processes.
This toolkit converges to create analytical architectures capable of managing data from collection to visualization, fostering informed decision-making. The choice of tools depends on specific needs and existing tech infrastructure.
Integrating Offline and Real-Time Architectures
A pivotal transformation in adapting analytical architectures to seamlessly support real-time applications centers around adopting a stream-based architecture paradigm. Unlike traditional processes that involve writing data to a storage layer before analysis, this approach entails analyzing data on the fly. Subsequently, both raw and aggregated results are stored, cultivating a dynamic environment that expedites the generation of insights. This acceleration is achieved while maintaining the capability to concurrently perform more intricate analytical processes.
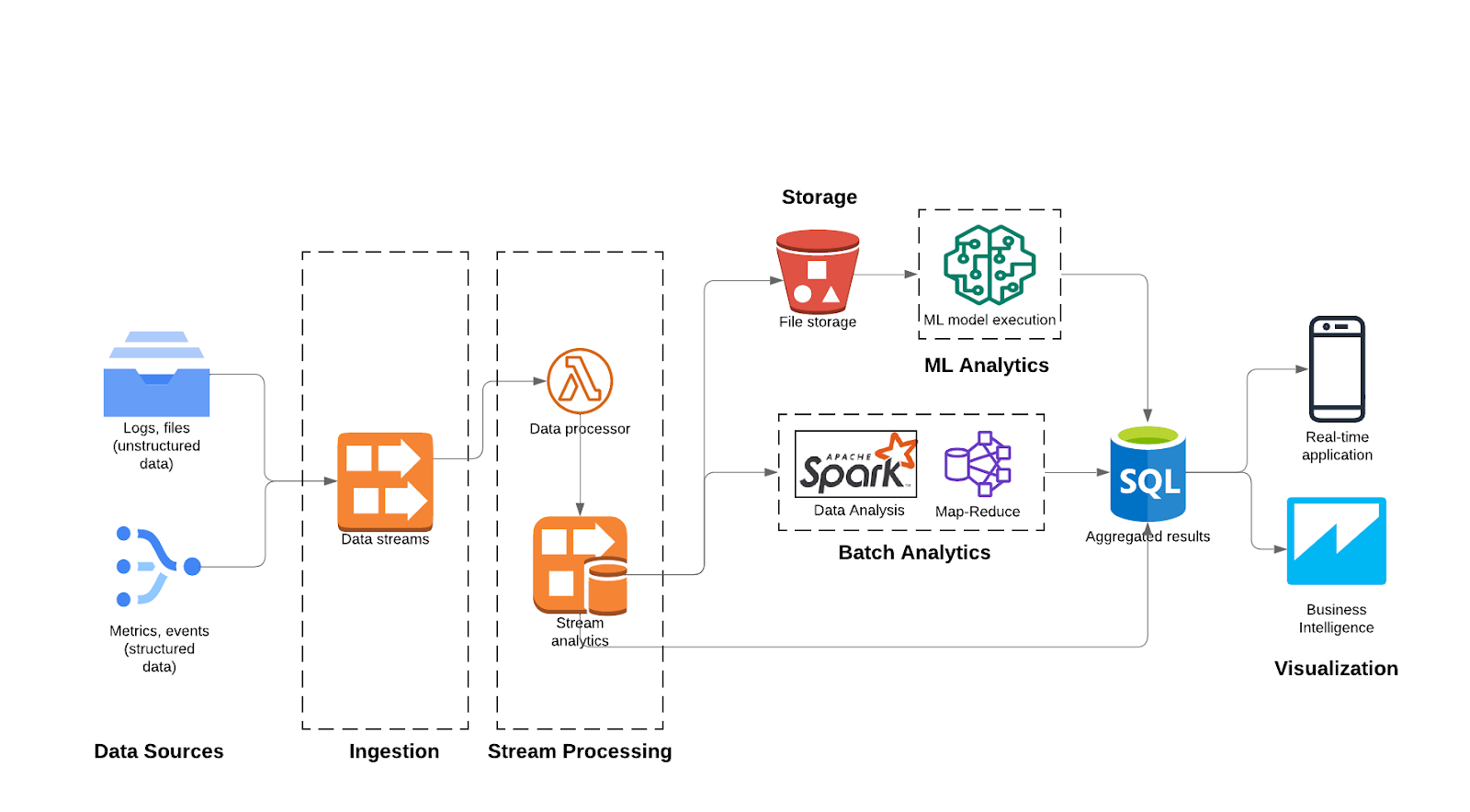
The outputs of real-time and offline analytics would feed into real-time applications. This integration can be achieved through:
- Data Synchronization: Regularly update the real-time application's data store with the results of the latest offline analytics.
- Incremental Processing: For rapidly changing data, use incremental processing techniques to update the real-time dataset with the most recent insights.
- Caching: Utilize caching mechanisms to store precomputed results that can be quickly retrieved by real-time applications.
In the above architecture, we adopt a data synchronization approach by utilizing a unified database to house the aggregated results. This database acts as a repository from which the application can draw relevant information. The convergence of real-time analysis and streamlined data storage not only enhances the speed of generating insights but also bolsters the architecture's capacity to engage in advanced analytics simultaneously. There are multiple strategies that can be applied for synchronization that are described next.
Data Synchronization Strategies
Overwrite Strategy: Ensuring Uniformity
The overwrite strategy involves replacing existing data with new information during synchronization. This approach ensures data uniformity across all connected systems. Typically employed when the most recent data version is considered the authoritative one, the Overwrite strategy simplifies synchronization processes by eliminating conflicts that may arise due to merging differing versions of data. While effective in maintaining data consistency, caution is required to prevent accidental data loss, especially if the original data holds value beyond the synchronization event.
Upsert Strategy: Merging New and Existing Data
The upsert (Update + Insert) strategy aims to blend the benefits of updating existing data and inserting new data when synchronizing. This strategy is particularly valuable when dealing with datasets that evolve over time. During synchronization, the Upsert strategy identifies whether a record already exists. If it does, the strategy updates the existing record with new information. If the record is absent, a new entry is inserted. This approach prevents data duplication while accommodating new entries and changes without overwriting entire datasets. Upserting is widely used in scenarios where historical records are as crucial as real-time updates, such as customer profiles or inventory management.
Incremental Insert Strategy: Adding New Data
The incremental Insert strategy centers on adding only new data records during synchronization. This approach is highly efficient when dealing with large datasets, as it minimizes processing time and resources. By solely inserting new records, organizations can keep their databases current without altering existing data. This strategy is ideal for scenarios where historical data remains constant, but new data points are continuously generated, such as website user logs or financial transactions. While it maintains data integrity, the Incremental Insert strategy may require additional mechanisms to handle updates or changes to existing records.
Selecting the Right Strategy: Factors to Consider
Choosing the appropriate data synchronization strategy hinges on the specific use case and business needs. Several factors should be considered:
- Data Criticality: Determine the value of existing data and the potential impact of overwriting it. For mission-critical data, consider strategies that prioritize data integrity while accommodating updates.
- Historical Context: Evaluate whether historical data holds significance. The Upsert strategy might be preferred when historical records must be retained and integrated with new data.
- Data Volume: Consider the volume of data being synchronized. Incremental Insert can be efficient for large datasets, reducing processing overhead.
- Concurrency and Conflicts: Anticipate potential conflicts that could arise when synchronizing data from multiple sources simultaneously. Some strategies may require conflict resolution mechanisms.
- Performance: Assess the performance implications of each strategy. Overwriting might be quicker, but it could come at the cost of historical data preservation.
Conclusion
In the pursuit of data-driven decision-making and real-time insights, it's essential not to overlook the critical role that offline analytics architectures play. These architectures provide the groundwork for accurate, reliable, and comprehensive insights that power real-time applications. By building a robust offline analytics infrastructure, organizations can leverage the strengths of both batch processing and real-time analytics, ultimately leading to more informed decision-making, improved user experiences, and sustained business success.
Opinions expressed by DZone contributors are their own.
Comments