Parallel Data Conflict Resolution in Enterprise Workflows: Pessimistic vs. Optimistic Locking at Scale
Locking isn’t backend trivia, it’s UX, trust, and system integrity. Smart enterprises blend optimistic and pessimistic locks to scale collaboration.
Join the DZone community and get the full member experience.
Join For FreeData conflict resolution is not a simple backend detail in modern enterprise systems, particularly when supporting complex concurrent operations. It is a full-stack architectural matter that affects consistency, UX, observability, and trust in the system.
We experienced this firsthand while building a government system that handled claims adjudication. Multiple case workers accessed and edited the shared records in parallel, and the premise that all system parts could be operated separately started to break down. Locking was no longer a database concern; it became a product at that scale.
What Locking Means in Modern Systems
Locking, in terms, says, “This data is in use.” Hold off.” Row-level locking used to be usually sufficient in traditional RDBMS systems. But distributed systems change everything. Now, your data is spread across containers, services, and multiple cloud regions. There is no implicit safety net.
Applications have to carry the burden of consistency. That’s where two philosophies come in—optimistic and pessimistic locking. These are not just access methods to a database but a way to handle conflict due to a parallel workflow, message queue, and simultaneous human collaboration at scale.
Optimistic Locking: When You Expect People to Behave
Most operations are assumed not to interfere with each other, so optimistic locking is used. Versions or timestamps are added on the fly for each update. The system runs this check when trying to find and accept a change provided by a user: it checks whether the version they started with is still the current version. If it is not, the update will be rejected, and the user will be prompted to try again or merge changes.
It worked well on a large-scale insurance claim intake system we built. The files were processed by claim processors asynchronously, with low chances of simultaneous edits. In a NoSQL system that allows multiple reviewers to move fast without blocking one another, we use a versioned document model to allow this.
Conflicts occasionally occur, and a version mismatch renders a comparison interface on the front end. The changes are reconciled with the users' version or discarded. While it was far from foolproof, it worked well with distributed teams and provided a hearty experience for most users.
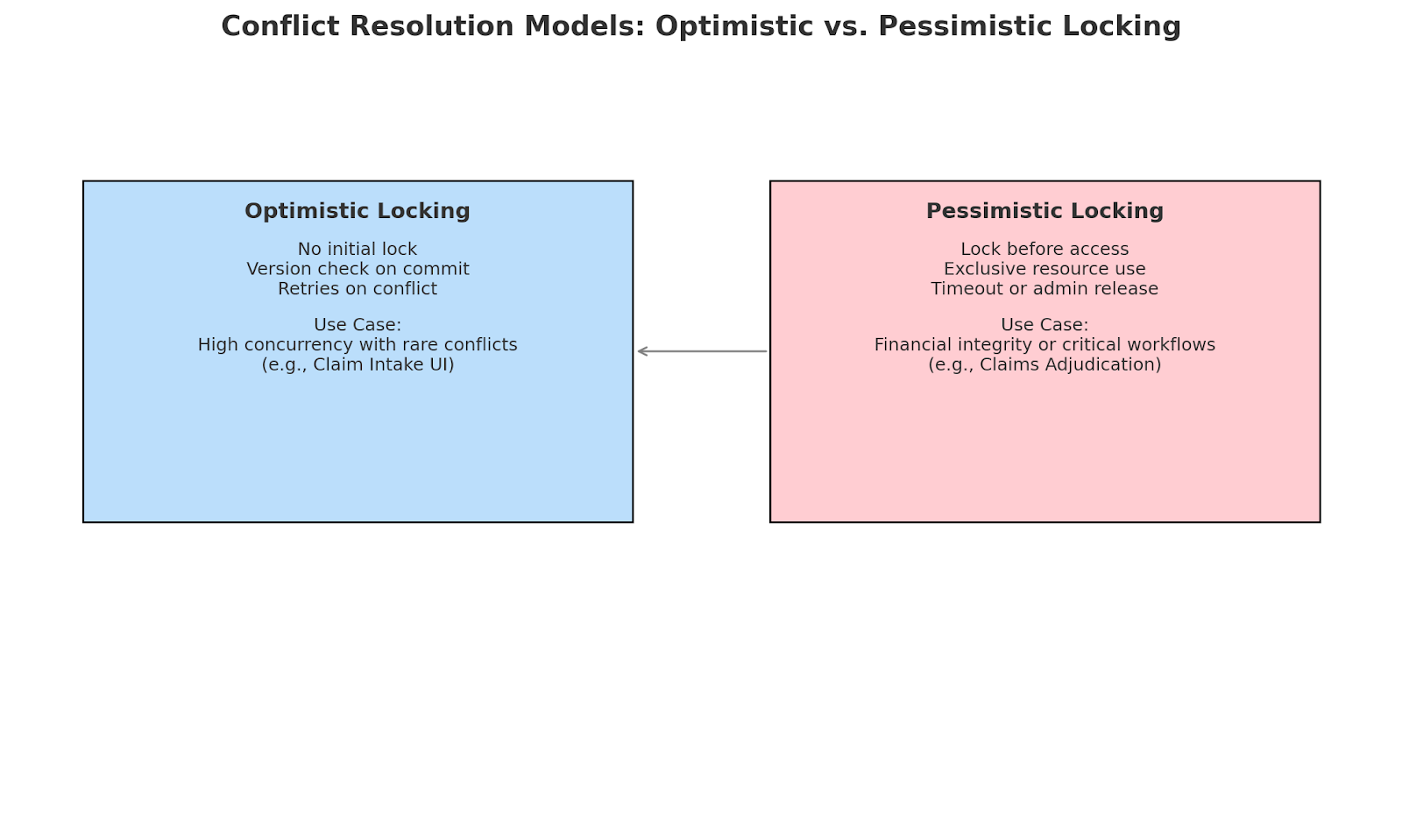
Pessimistic Locking: When You Can’t Afford Mistakes
In contrast, pessimistic locking assumes that conflicts are common and dangerous. Before proceeding, an exclusive lock is grabbed. The lock temporarily makes the record unavailable to other users.
This model had to be used in the claims adjudication module of the same platform. Once a financial benefit calculation was underway, concurrent edits could lead to a wrong reimbursement. Data integrity was not negotiable in this case.
When the claim was set to ‘review,’ an automatic lock was applied. Additionally, the lock owner and duration were displayed with visual indicators to other users so they could not make changes. The problem wasn't the lock; it was abandonment. Others were blocked if someone locked a case and walked away.
We added a lock expiration mechanism and a lock dashboard to let system administrators release or reassign locks after predefined time-outs. This combination of strict access control and admin visibility was critical to keeping things moving without losing data accuracy.
Scaling Locking Beyond One System
Locking isn’t just about transactional guarantees. It becomes a system-wide decision to control concurrent access between different services. This turns out to be exceptionally tricky in microservices. In the same resource, other parts of the system can use different APIs, jobs, or queues to operate on the same resource.
In one of our distributed architectures, however, we have handled this using Redis as a shared lock registry. Instead, a lock would be checked before each service needed to secure data access. These locks were tied to service health and ephemeral, meaning there would be no stale process holding on to a resource for an infinite amount of time.
Optimistic strategies with in-app version tracking were used in less sensitive operations like tagging files and updating non-crucial metadata. This dual approach allowed us to control throughput and adjust locking strategies depending on the nature of each workflow.
Making Conflict Visibility a First-Class Feature
Observability is one of the more subtle challenges to achieving locking at scale. Most systems today lock without conveying to users or support teams what’s going on. When something breaks, users don’t know why, and engineers don’t know where.
We streamed the lock lifecycle events (acquisition, rejection, release) into our log analytics pipeline to solve this. Then, we brought the most contested records, the number of retries, and where contention hotspots showed up inside the system to our internal dashboards.
That provided them with data they could work with. Tuning retry logic, changing lock durations, and improving user training taught them about actual friction in the system. This approach turned conflict resolution into something measurable and tunable, rather than a black box.
Locking Is Not Binary: It's Layered
Many people assume they must pick only one model for the entire system. However, most enterprise systems benefit from using both. Different workflows require different levels of control, which should be reflected in the locking strategies.
For this, we built lock-aware components, which could change allowing and denying strategies based on the environment setup and business rules depending on the case or user role. For example, field agents were default restricted, and support users with override permissions could bypass a few locks. That configurability eliminated locking as a system constraint and turned it into a governance feature.
Conclusion
Data conflict is not an edge case. It’s a certainty in enterprise systems with users collaborating or processes overlapping. Conflict doesn’t have to be the end of the system. The only thing is the right locking strategy, making those decisions visible, and adapting to real usage flow.
Optimistic and pessimistic locking are not opposites; they are tools. They help systems align with real-world usage, where collaboration and concurrency are the norm and not the exception. They give teams the tools to resolve those conflicts without breaking trust or losing data.
Opinions expressed by DZone contributors are their own.
Comments