Event-Driven Architecture Using Serverless Technologies
Event-driven architecture (EDA) design pattern uses events to determine which parts of the software to execute.
Join the DZone community and get the full member experience.
Join For FreeIn modern architecture, most of the system has some component of Asynchronous computing. Any application which you see has one versus other Asynchronous communications. Popular Examples of such applications are Video Streaming Services, where you stream the packet of data and then render it on client applications, Popular messaging applications, or any of the collaboration tools. These are just a handful of examples, but you can think of asynchronous communication anywhere where you are not transiting the data in the same request/response.
What Is Event-Driven Architecture?
Event-driven architecture can be visualized as a bunch of the applications module triggered by some kind of event, and then it processes and puts these events back into some place to be consumed by the other application.
These independent modules are isolated and stateless; they are good at performing one operation and don’tdoesn't care about the overall application.
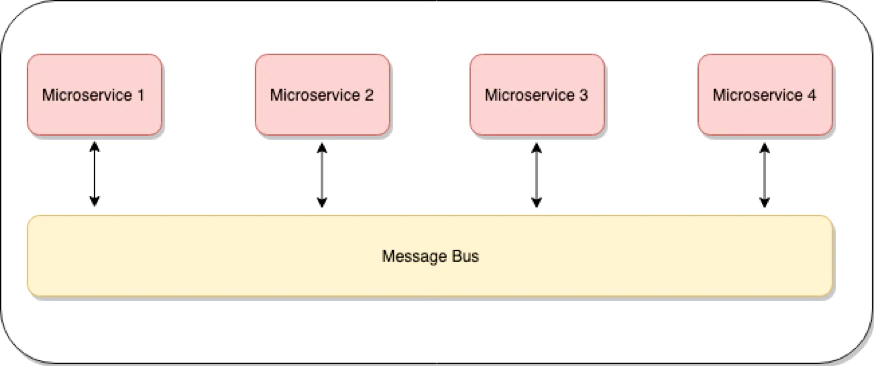
Now let's start designing this Event-driven architecture using Serverless technologies.
First thing first, What's in a well-architected streaming solution?
Having implemented several streaming related use-cases, I think the ideal streaming solution should address the following requirements:
Scaling
In modern application architecture, auto-scaling should be one of the basic design considerations. In the era of cloud computing, you can get unlimited computing as you need; hence there is no need to scale it for peak loads and pay extra. Although you can plan for major cyclical loads, it's hard to optimize it by the minute in traditional server-based infrastructure. Ideally, applications should have the capability to auto-heal and auto-scale in the event of major spikes in requests.
Throttling
Streaming applications are typically designed to ingest thousands of requests per second and eventually filter to a more manageable scale. When unexpected spikes hit, streaming applications can scale out, but downstream blocking IOs (APIs, DB, etc.) may not be able to. Because of this, throttling becomes one of the fundamental requirements for any streaming application. Remember, your system is only as good as the weakest link.
Fault Tolerance
Invariably applications are connected with other resources like APIs, Databases, etc. It's difficult to avoid failures in the dependent systems, but at the same time, you also want to safeguard your application against these issues. In a streaming application, fault tolerance is one of the critical requirements, as you don't want to lose your data when your backend system is down.
Reusability
It's very common to focus on reuse versus recreating the solution. The degree of reuse depends on the modularity and size of the component, with microservices being the best example of reuse. By making the building blocks of streaming solutions small and configurable, we can emphasize component reuse across multiple applications.
Monitoring
Well, I must admit that one of the best feelings is knowing what is happening with my application. Imagine millions of messages/events are flowing through your application, and you have the ability to trace every message and understand what exactly happened to that message. This becomes even more crucial when you are building critical customer-facing applications and are required to find out what exactly happened to a specific customer event. So monitoring is very crucial for synchronous or asynchronous systems.
Now let's try to break the problem.
We divided the overall architecture into three layers -Source, Sink, and Processing.
- Source: In this layer, microservices are only responsible for pulling the data from the sources. Think about this more as the entry point of the event into your streaming application. Example: Reading the events from the Kafka cluster.
- Processing: This layer is responsible for processing the event which you got from the source layer. You can also think of this as a layer where you can have your application-specific logic. Example: Filtering the events or calling the API to decide on the event. You can have one or more processing layers to map, reduce, or enhance your messages.
- Sink: This is the last layer in your application where you are taking the final action on the event. Example: Storing the events in the data store or triggering other processes by making API calls.
Now let's see the serverless version of how to build this architecture.
Below is the mapping from Message Driven Architecture to the AWS Services.
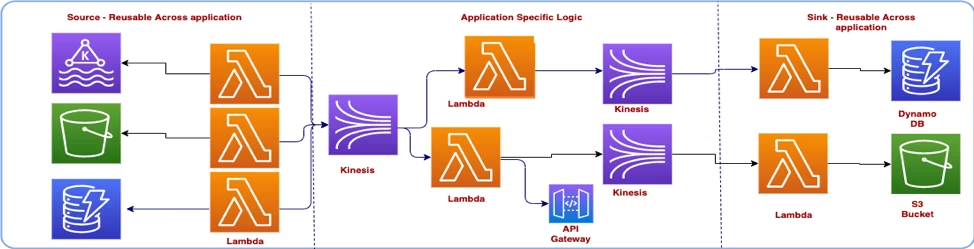
From the above diagram, you may feel that there are lots of repetitive actions, specifically from Lambda to writing/reading from the Kinesis. Well, you can be creative and can build some kind of library for repetitive functionality.
At Capital One, we did exactly that and built our internal SDK to abstract the repetitive tasks. Our SDK has the below features:
- Read and write from message bus: Writing and Reading the events from the message bus(Kinesis or others in the future).
- Exception handling and retries: There are two main retry categories, blocking and non-blocking. You can have the blocking errors retry when your backend application is failing until it is back. Non-blocking retries will be used when you only want to retry the specific event, and it doesn't have any impact on the other events.
- Secret management: This feature will be needed when you don't want to rely on storing the credentials on your serverless function. You can take your pick of enterprise secret management tools and integrate them as part of your library.
- Monitoring: We created our customized message envelope, which has the metadata which helped us to track every message. The SDK can take that overhead from the developer and can insert/remove the envelope on the entry/exit of each microservice.
- Logging: To achieve a uniform experience across all the microservices, you can build a logging pattern in the SDK.
- Message deduplication: As we know, most of the distributed fast data systems guarantee at least one delivery. When you want to filter out duplicate messages, you can think about abstracting them as part of the library. You can use hashing or other methodologies to implement message deduplication with sub milliseconds latency.
How This Solution Implements the Requirements of Our Ideal Streaming Solution
As we discussed earlier, any serverless streaming solution would need to address scaling, throttling, reusability, fault tolerance, and monitoring. So how did this stake up?
Scaling
This architectural pattern, in combination with scalable cloud services, inherently makes this possible.
- The pattern uses Lambdas to implement microservices and connected via Kinesis. Therefore, we only need to scale Lambdas that have high TPS, and as the messages get filtered out, adjust the scale configuration accordingly.
- By design, serverless functions are auto-scalable. Example: If you are using Lambdas and Kinesis, you can scale the Kinesis if your message throughput increases from 2MB/Sec to 4 MB/Sec, which will also scale the Lambda functions that are connected to the Kinesis.

Throttling
The fundamental function of throttling is based on needing to hold your request if your input request rate is much higher than what your downstream can support. The persistent nature of the message bus can help us here since you can only pick the number of messages which you can handle at one time and hold others. Example: If you are using Kinesis as a message bus, you can specify the batch size which you can handle in your function.
Reusability
If we can build the source and sink microservices in such a way that they do not have any business functionality and are configuration-driven, then multiple teams can use them to consume events. Example: If you can build the source function to consume events from Kafka that allow for configuration on things like topic name, broker address, etc., any team can take that function and deploy it into their stack as per their needs without needing to make any code change.
The above can help us to achieve code-level reusability. The other reusability is the reusability of the flow itself. If the message bus you selected for your architecture is a pub-sub-based bus, then you can have multiple subscribers to the same events. Example: You can just fan out your event to the two microservice without writing a single additional code.
Fault Tolerance
Again, the message bus can rescue us here. Think about if you are having errors from your backend services; you can hold all/failed messages into the message bus and retry until your backend calls start succeeding.
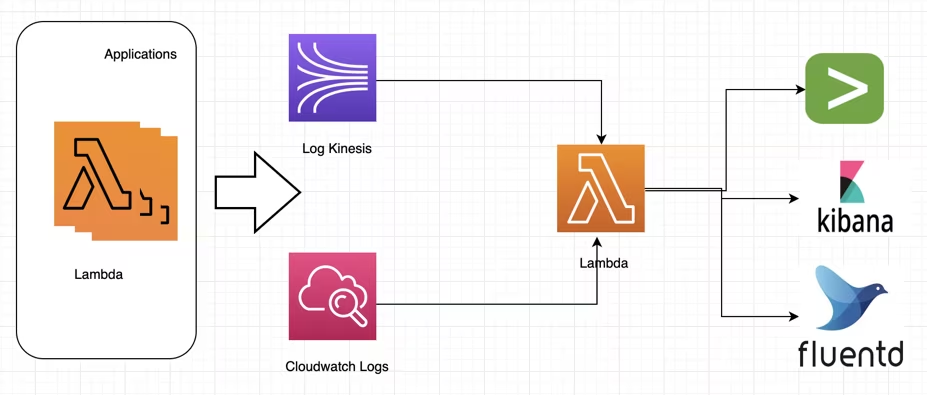
Monitoring
Logging metadata payload as a part of SDK can help achieve uniform logs across different functions. You can also build one reusable function which can forward your logs to the preferred monitoring solution.
Is Serverless Streaming Really the Best Option?
Not really. Apache Spark is a distributed computing platform that really shines for large-scale distributed data processing loads. Spark remains the tool of choice when it comes to high-volume computing and batch processing, where data and compute functions can be distributed and performed in parallel. Typical examples include the heavy computing needs of machine learning use cases, the map/reduce paradigm involving several hundred files, long-running processes that deal with petabytes of data, etc. Spark can also be the tool of choice for the real-time streaming world as well, but only if the volume is very high, running in hundreds of thousands of transactions per second.
Across Capital One, we use multiple flavors of big data engineering tools. In my group, I use serverless streaming for high-volume use cases, such as generating meaningful alerts based on customers' transactions at thousands of events per second, and for low-volume events like card reissues that run in tens of events per second. I also use Spark to process large transaction files to generate customers' spending profiles using machine learning models. It all depends on specific needs.
Published at DZone with permission of Maharshi Jha. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments