Exactly-Once Processing: Myth vs Reality
Exactly-once is a collection of local guarantees, not an end-to-end guarantee, and real systems rely on idempotency and at-least-once guarantees.
Join the DZone community and get the full member experience.
Join For FreeExactly-once processing (EOP) is often touted as the gold standard for reliability in distributed systems. The promise of processing each message just once seems perfect, whether you're developing financial systems, real-time analytics pipelines, or event-driven microservices.
But the truth is much more complex. What most systems refer to as "exactly once" is actually an approximation that balances trade-offs, limitations, and assumptions rather than an absolute.
To help you create systems that are accurate, robust, and practical, this article dissects exactly once processing.
The Myth
The myth is straightforward:
- The entire program must be executed exactly once if the broker supports exactly once semantics.
- Similarly, it is frequently assumed that the entire pipeline ensures exactly-once processing if a stream processor can restore state from checkpoints.
- Another widespread misconception is that, the user-visible result must likewise have happened exactly once if a database transaction commits only once.
When analyzed throughout a whole, real-world system, none of these claims actually hold.
The Reality
This is a more truthful statement:
- A broker can provide exactly-once writes between producers and broker-managed topics.
- Within its checkpoint boundary, a stream processor can provide exactly-once state transitions.
- One local transaction can be made atomic by a database.
- When idempotency and replay-safety are implemented across all boundaries, an end-to-end business workflow is effective only once.
That goes beyond semantics. It is designed for failure.
Three Important Questions
Three distinct questions should be asked in a useful design review:
- Is it possible to send the same input more than once?
- Is it possible to try the same calculation more than once?
- Is it possible for a business effect to occur more than once?
The approach is typically effective if the first two questions are answered affirmatively, but the third is answered negatively.
Definition
Before debating "exactly once," precisely clarify the meanings at each layer:
| Semantic | Definition |
|---|---|
| At-most-once | A message may be lost, but once acknowledged it is not retried. No duplicates, possible data loss. |
| At-least-once | A message is retried until acknowledged. No data loss, but duplicates are possible. |
| Exactly-once within a boundary | A subsystem guarantees one logical input results in one durable state transition relative to its recovery model. |
| Effectively-once | Duplicate deliveries may occur, but the final business effect is idempotent, so users observe the action exactly once. |
The first hard fact is that exactly once is nearly always local rather than global.
Where The Boundaries Actually Break
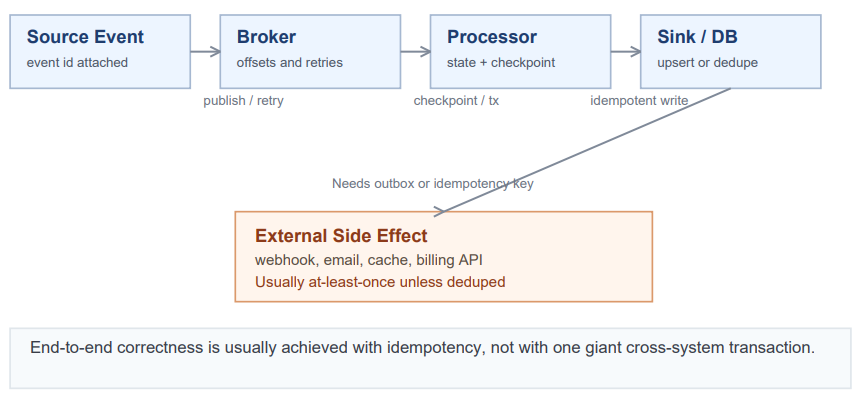
Acknowledgment, retry, timeout, crash recovery, replay, and deduplication are concepts unique to each boundary. It is not a given that a strong assurance at one boundary would automatically compose with the next.
| Boundary | Mechanism | Guarantee Level | Failure Risk |
|---|---|---|---|
| Producer to Broker | Producer ID + sequence numbers | Idempotent append | Limited to broker partitions |
| Broker to Consumer | Consumer group offsets | At-least-once delivery | Crash leads to replay |
| Consumer to DB | ACID transaction + unique key | Idempotent sink write | No dedupe causes duplicates |
| DB to Outbox | Same ACID transaction | Atomic state + event | Relay may republish |
| Outbox to Downstream Broker | Event ID deduplication by consumer | At-least-once publish | Consumer must handle dedupe |
| Service to External API | Idempotency key per request | Effectively-once | Timeout creates uncertainty |
Every boundary has its own notion of acknowledgment, retry, timeout, crash recovery, replay, and deduplication.
Why Are Duplicates Common Rather Than Unusual
Recovery behavior typically results in duplicates:
- After a transmit timeout, a producer attempts again because it cannot distinguish between failure and success.
- Before the offset acknowledgment, a customer writes to a sink and crashes.
- A processor reruns a portion of the input after restoring from a checkpoint.
- Because the publish acknowledgment was not observed, a relay republishes an outbox record.
- Even though the remote service has already applied the request, an HTTP client attempts again after the timeout.
None of those actions is strange. They are precisely what well-behaved distributed software accomplishes under uncertainty.
Technical Reality at Each Layer
Producer Semantics
At the producer layer, exactly once usually means idempotent append behavior to the broker, not magical downstream correctness. For a broker such as Kafka, an idempotent producer can use:
- Producer id
- Sequence numbers
- Partition-level ordering
- Broker-side dedupe of retried sends
A minimal producer configuration seems like:
enable.idempotence=true
acks=all
retries=Integer.MAX_VALUE
max.in.flight.requests.per.connection=5This is important. It stops a common type of duplicate appends caused by producer retries. However, it only discusses records that were written to Kafka partitions. It makes no mention of:
- A consumer writing twice to PostgreSQL
- A webhook firing twice
- An email being sent twice
Kafka Producer Details: Idempotence Versus Transactions
Kafka provides you with two distinct tools that are frequently mistakenly combined into a single idea:
- Idempotent producer semantics
- Transactional producers Semantics
Retried appends to a partition benefit from idempotence. Multiple writes and offset commits can be combined into a single broker-visible unit with the aid of transactions.
The following are typical transactional producer settings:
enable.idempotence=true
transactional.id=orders-service-1
acks=allAnd the application flow is conceptually:
producer.initTransactions();
producer.beginTransaction();
producer.send(outputRecord1);
producer.send(outputRecord2);
producer.sendOffsetsToTransaction(offsets, consumerGroupMetadata);
producer.commitTransaction();This resolves the issue: output records and ingested offsets can become atomically visible simultaneously within Kafka if the application consumes from Kafka and produces back to Kafka.
But take note of what's absent:
- No database write is included
- No webhook is included
- No Redis mutation is included
- No email is included
Kafka transactions are genuine, but their scope is Kafka-managed state rather than arbitrary external state.
Broker and Consumer Semantics
When the customer's progress marker is behind the durable write, it has already completed, the broker may redeliver a record.
The classic race is:
- Consumer reads message
- Consumer writes to sink
- Process crashes before offset commit
- Consumer restarts
- Broker redelivers
The business effect occurs twice if the sink write is not idempotent.
For this reason, "broker exactly once" and "application exactly once" are not interchangeable terms.
Kafka Consumer Details: Offsets Are Not Business State
The consumer offset as evidence that the business activity occurred exactly once is the root cause of many application issues. It isn't. The offset is only evidence of the consumer group's advancement.
These are distinct facts:
- The broker knows a record was consumed by a consumer group
- The application knows a sink mutation was committed
- The business knows the effect should be visible once
Only when the application specifically aligns those facts will they do so.
Additionally, "isolation.level=read_committed" is frequently misinterpreted on the read side. It stops customers from seeing transactional writes that Kafka producers have aborted. Although that is helpful, not all downstream effects are transformed into exactly one.
It simply means:
- Committed Kafka transactions are visible
- Aborted Kafka transactions are hidden
It does not mean:
- Downstream database writes cannot duplicate
- External side effects cannot duplicate
- Application retries are automatically idempotent
Because of this, consumer accuracy nearly always necessitates one of:
- Idempotent sink keys
- Inbox dedupe tables
- Sink-side upserts
- Compare-and-set version checks
- Business-key uniqueness constraints
The Honest Way to Document Guarantees
Rather than writing "the system is exactly once," use scoped statements for each boundary in your documentation:
| Boundary | Guarantee Statement |
|---|---|
| Producer to Kafka | Producer writes to Kafka are idempotent per partition. |
| Processor State | State transitions are exactly-once relative to checkpoint recovery. |
| Primary Database Writes | Writes are idempotent by business key and message ID. |
| Outbox Publication | Publication is at-least-once; downstream consumers must dedupe by event ID. |
| Webhook / SaaS APIs | Integrations rely on idempotency keys and replay-safe receivers. |
| End-to-End Behavior | Business behavior is effectively-once under replay and recovery. |
Final Thoughts
If you make the promise specific and local, exactly once processing is not a fiction.
Within clearly specified constraints, databases, Kafka, Flink, and other subsystems can unquestionably offer exactly-once guarantees.
The misconception is that the local assurances automatically combine to form a single end-to-end promise that spans brokers, processors, databases, outboxes, caches, webhooks, and external APIs.
The robust architecture in real systems is typically:
- At-least-once delivery
- Transactional local state
- Idempotent sinks
- Outbox or inbox patterns
- Idempotency keys for side effects
- Explicit documentation of every guarantee boundary
It is the version that endures node draining, broker failovers, replay after restore, and unclear network timeouts, but it is less commercially viable than stating "exactly once everywhere."
Opinions expressed by DZone contributors are their own.
Comments