Far Memory Unleashed: What Is Far Memory?
In-memory databases, which offer super fast transaction processing capabilities for OLTP systems and key-value store DBs, are gaining popularity.
Join the DZone community and get the full member experience.
Join For FreeIn-memory databases, which offer super fast transaction processing capabilities for OLTP systems and key-value store DBs, are gaining popularity. Some examples of well-known in-memory databases are SAP HANA, VoltDB, Oracle TimesTen, MSSQL In-Memory OLTP, and Memcached. Some less-known ones are GridGain, Couchbase, and Hazlecast. The demand for DRAM has skyrocketed due to the use of in-memory databases for SAP S/4 HANA, big data, generative AI, and data lakes. One of the main challenges in large computer clusters is the limited availability of main memory. For instance, the maximum DRAM for SAP HANA on AWS is 24TB, which costs 63000 USD per month or about 750000 USD per year. On-premises, the maximum DRAM is often 12–18TB.
Moore’s law, which states that the number of transistors in an IC doubles every two years, is no longer valid. This means that main memory is becoming more and more of a bottleneck for in-memory databases. A potential solution was Intel’s Optane memory, a non-volatile memory that had similar performance to DRAM at a lower cost, by enabling load/store access at a cache block granularity. However, Intel discontinued Optane, ending its effort to create and market a memory tier that was slightly slower than RAM but had the advantages of persistence and high IOPS.
A possible alternative that is being explored both academically and commercially is far memory or memory virtualization. Far memory is a memory tier between DRAM and Flash that has a lower cost per GB than DRAM and a higher performance than Flash. Far memory works by disaggregating memory and allowing nodes or machines to access the memory of a remote node/machine via compute express link. Memory is the most contested and least elastic resource in a data center. Currently, servers can only use local memory, which may be scarce on the local system but abundant on other underutilized servers. With far memory, local machines can use remote machine’s memory. By introducing far memory into the memory tier and moving less frequently accessed data to far memory, the system can perform efficiently with low DRAM and reduce the total cost of ownership. Far memory uses a remote machine’s memory as a swap device, either by using idle machines or by building memory appliances that only serve to provide a pool of memory shared by many servers. This approach optimizes memory usage and reduces over-provisioning.
However, far memory also has its own challenges. Swapping out memory pages to remote machines increases the failure domain of each machine, which can lead to a catastrophic failure of the entire cluster. Moreover, swapping over RDMA causes poor latency and throughput due to head-of-line blocking. There are some recent developments that can address these issues.
- Fastswap: Fastswap, designed by a group of researchers from UC Berkeley, is optimized for far memory through RDMA and is transparent to applications and developers. It achieves remote page access latencies of <5 us, enabling applications to access far memory at 10Gbps using a single thread and 25 Gbps using multiple threads.
- Infiniswap: A group of researchers from the University of Michigan developed INFINISWAP on an RDMA cluster by dividing the swap space of each machine into many slabs and distributing them across the remote machine’s memory. They experimented on VoltDB, Memcached, and PowerGraph and observed a performance improvement of 4x over the disk. This is also transparent to applications and OS.
- Zswap: Google developed a software-defined far memory by storing cold compressed pages in memory using Zswap and implementing far memory in software. Compressing memory pages allows us to pack more data in memory (i.e., lower cost per GB) at the cost of increased access time. At a high level, this is no different from any other far memory implementation from a TCO perspective. swap, being a software approach, can be deployed in a much shorter time and with lower effort and does not require cross-vendor collaborations as there is no need for any special hardware (e.g., NVM).
- AIFM: In another study by researchers from Brown University, they made far memory available to the local machine using a simple API. The concept is called application-integrated far memory (AIFM). It avoids read and write amplification that paging-based approaches suffer. They claim that AIFM outperforms Fastswap, a state-of-the-art kernel-integrated, paging-based far memory system, by up to 61×.
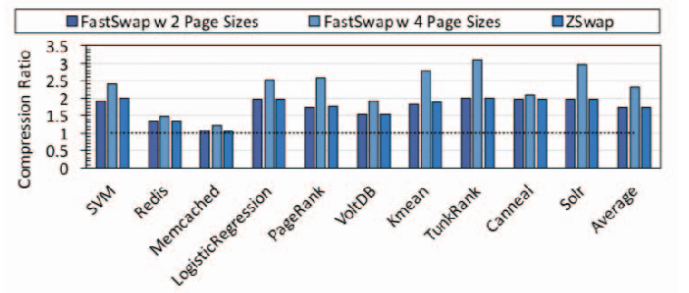
Figure 1: Fastswap vs ZSwap compression ratio
To sum up, the exploration and progression of far memory represent a highly promising pathway for transforming the data center landscape. A pivotal factor contributing to the potential of far memory is the emergence of groundbreaking technologies like Compute Express Link (CXL). Engineered to bolster high-performance computing and ensure memory coherency, CXL has the capacity to revolutionize how systems access and utilize memory resources. The integration of CXL with far memory architectures opens up novel avenues for improving data processing, storage efficiency, and overall system performance. Noteworthy is the capability of Kubernetes to harness far memory in tandem with CXL, further expanding the horizons of efficient and innovative computing solutions. Far memory, in this context, offers an opportunity to address the high memory costs associated with SAP HANA.
Opinions expressed by DZone contributors are their own.
Comments