Data Ingestion with Flume Sending Events to Kafka
The author, Rafael Salerno, takes us step-by-step through this process.
Join the DZone community and get the full member experience.
Join For FreeWhat Is Data Ingestion?
Date ingestion is the process of getting data from somewhere like logging, database for immediate use, or for storage.
These data could be sent in real time or in Batches.
Ingestion by real-time data is sent one by one directly from the data source, as in batch mode data are taken in batches in pre-defined intervals.
Usually when ingestion date of talks is likely to be related to Big Data, a large volume of data and assigned to it a few concerns us may come in mind, such as volume, variety, velocity and Veracity.
For this work Data Ingestion, a consolidated and widely used tool is Apache Flume.
Apache Flume
Apache flume is an open source tool, reliable, high-availability for aggregation, collection and able to move large amounts of data from many different sources into a centralized data storage. Based on data flow streaming is robust, fault-tolerant with high-reliability mechanisms.
A Flume event is defined as a data flow unit. A Flume agent is a process of the JVM that hosts the components through which events flow from an external source to the next destination.
The idea in this post is to represent the flow data model below focusing on the necessary settings for this flow happen, abstracting some concepts that should be checked in flume if necessary for documentation. 
Tools Required to Test the Sample:
Configuration Files:
After downloading the Apache flume should be created a configuration file in the folder conf/ "flume-sample.conf"
This file can basically be divided for better understanding of 6 parts:
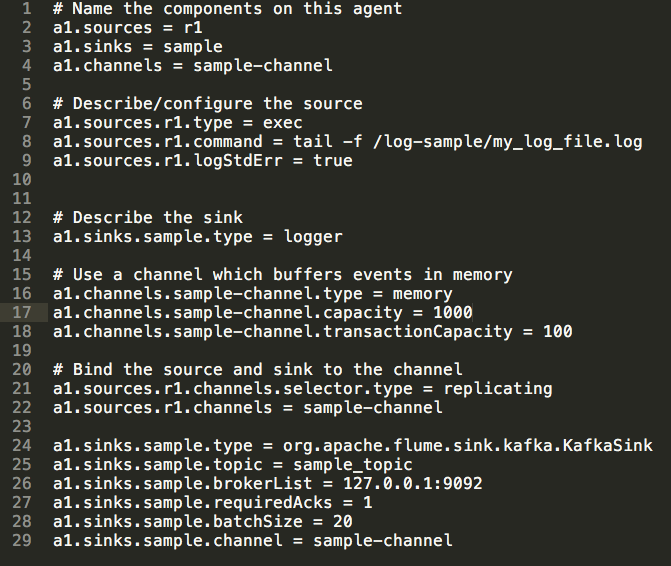
1.Agent Name:
a1.sources = r1
a1.sinks = sample
a1.channels = sample-channel2.Source configuration:
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /log-sample/my_log_file.log
a1.sources.r1.logStdErr = true3.Sink type
a1.sinks.sample.type = logger4.Buffers events in memory to channel
a1.channels.sample-channel.type = memory
a1.channels.sample-channel.capacity = 1000
a1.channels.sample-channel.transactionCapacity = 1005. Bind the source and sink to the channel
a1.sources.r1.channels.selector.type = replicating
a1.sources.r1.channels = sample-channel6.Related settings Kafka, topic, and host channel where it set the source
a1.sinks.sample.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.sample.topic = sample_topic
a1.sinks.sample.brokerList = 127.0.0.1:9092
a1.sinks.sample.requiredAcks = 1
a1.sinks.sample.batchSize = 20
a1.sinks.sample.channel = sample-channelFinal result of the file below:
To run Apache Flume with this configuration you must run the following command within the Flume folder:
sh bin/flume-ng agent --conf conf --conf-file conf/flume-sample.conf -Dflume.root.logger=DEBUG,console --name a1 -Xmx512m -Xms256mWhere:
- Indicate where the file that was set flume-sample.conf
- "- - Name" is the agent name equals to a1
- Dflume.root.logger is the form that will be logged on the console
Before it is necessary to raise the Apache Kafka (concepts related to Kafka are not part of this post the focus here is only the data ingestion with flume).
After downloading the Kafta with the default settings, you can see the flow work.
Execute the following commands:
- START Zookepper -> sudo bin/zookeeper-server-start.sh config/zookeeper.properties&
- START Kafka Server -> sudo bin/kafka-server-start.sh config/server.properties&
- CREATE TOPIC - bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --replication-factor 1 --partitions 1 --topic sample_topic
In this command should show the data being extracted from the Source (my_log_file.log) and are being sent to the sample_topic topic. START CONSUMER -> bin/kafka-console-consumer.sh --zookeeper 127.0.0.1:2181 --topic sample_topic --from-beginning
Thus the proposed data flow is complete and providing data to other consumers in real time.
Opinions expressed by DZone contributors are their own.
Comments