How Does Kafka Perform When You Need Low Latency?
In this article, we take a look at various benchmarks testing higher throughputs with end-to-end latencies between 2.5 and 30 milliseconds.
Join the DZone community and get the full member experience.
Join For FreeMost Kafka benchmarks appear to test high throughput but not low latency. Apache Kafka was traditionally used for high throughput rather than latency-sensitive messaging, but it does have a low-latency configuration. (Mostly setting linger.ms=0 and reducing buffer sizes). In this configuration, you can get below 1-millisecond latency a good percentage of the time for modest throughputs.
Benchmarks tend to focus on clustering Kafka in a high-throughput configuration. While this is perhaps the most common use case, how does it perform if you need lower latencies?
Where are Some Latency Benchmarks Available?
These are various benchmarks testing higher throughputs of 200kmsg/s to 800kmsg/s, with end-to-end latencies between 2.5 and 30 milliseconds.
Confluent benchmark, looking at the 99 percentile latency compared with Apache Pulsar and Rabbit MQ (pro Kafka). “Kafka provides the lowest latency at higher throughputs, while also providing strong durability and high availability.”
NativeStream benchmark comparing Pulsar to Kafka (pro Pulsar). “Pulsar’s 99th percentile latency is within the range of 5 and 15 milliseconds.”
Instacluster performance, looking at average latencies with varying number of producers, with different configurations.
Datastax latency benchmark using the same benchmark as Confluent. Their conclusion appears to be that, when flushing every message to disk, Pulsar is better.
Using Confluent Cloud from AWS: “With my specific test parameters, Kafka p99 latencies are 100-200 ms and much lower than Pub/Sub latencies.”
My impression is that these benchmarks aren’t so much an attempt to show low latency, but rather show what the authors consider good latency under high load.
Benchmarking Kafka for Low Latency
For a low-latency system, you want the hardware which will best support your requirements. This is often plenty of the fastest CPUs you can afford and more than enough IO bandwidth as well.
The best way to go fast is often to do as little as possible, and keep the solution simple. In my case, I am starting with just one PC, a Ryzen 9 5950X with 64 GB memory and a Corsair MP600 PRO XT M.2 drive.
Obviously cluster support is an important use case for Kafka, but let's start with a really simple end-to-end use case: one machine, two message hops and a trivial microservice in between.
One Machine, One Trivial Microservice, End-to-End Latency
This benchmark is similar to a previous one found here. However, Kafka is configured for lower latencies and multiple producers are used to support a significant, but lower, message throughput.
In this configuration, Kafka has a fraction of the latencies reported in the benchmarks above.
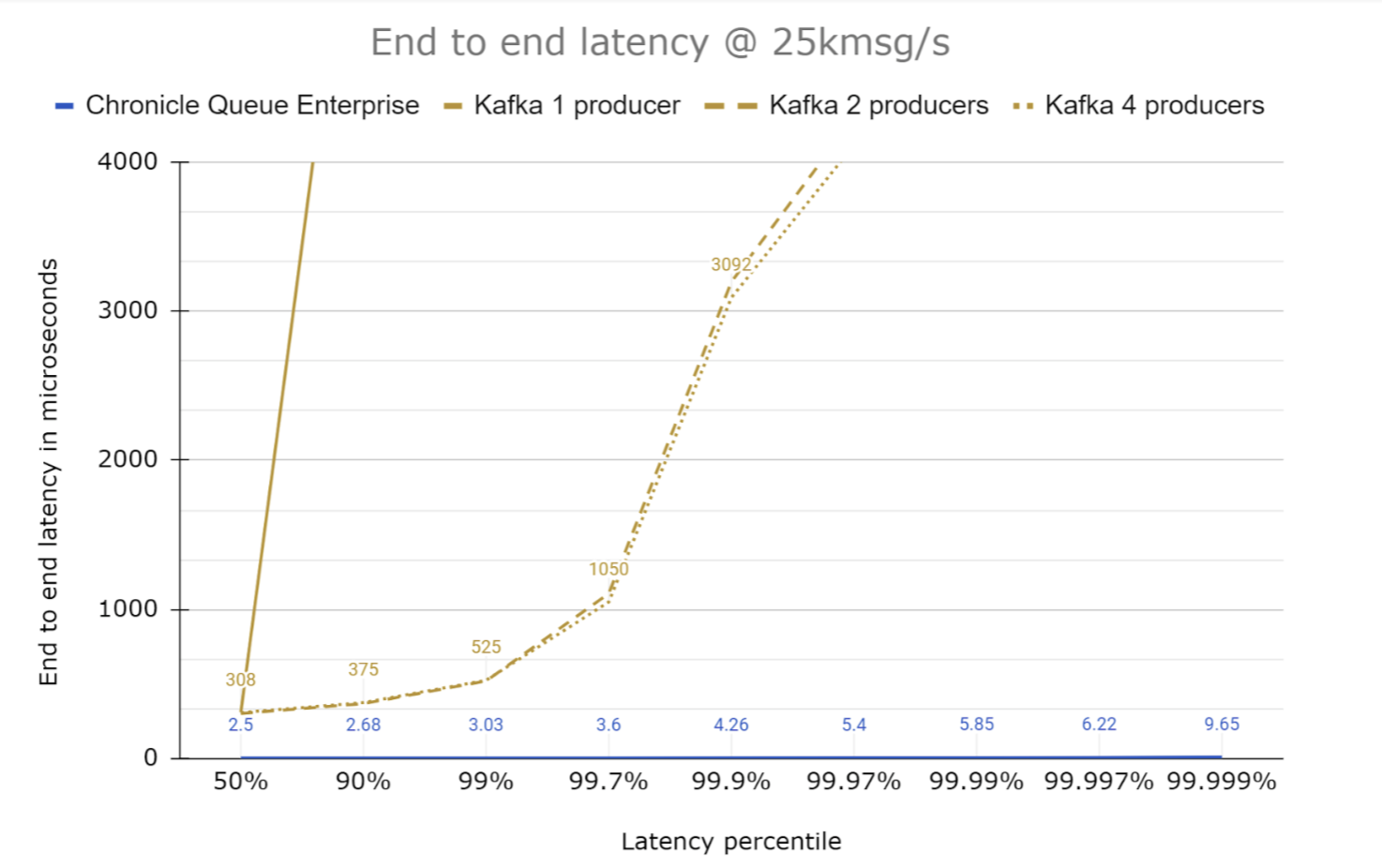
One producer doesn’t handle this throughput well, but two and above producers (I tested up to 10) produce good results. Increasing the number of partitions only increased the overhead (albeit slightly). Increasing the number of consumers saw a small variation in latencies.
To put this in perspective, I added the results for a single producer using Chronicle Queue Enterprise which you might expect has far, far less jitter. (See the almost invisible blue line at the bottom of the graph above. The line runs just above the X-Axis; the reason this line can’t be seen is that Chronicle Queue is performing significantly better than Kafka.) This indicates the performance between processes on the same machine.
No Conclusion
I like to finish with a conclusion, but this leaves me with more questions than answers. The benchmarks linked at the start of the post aim to discuss the low latency characteristics of Kafka. However, in actual fact, these tests appear to have instead configured Kafka to maximize throughput rather than for low latency. Kafka can produce better benchmark numbers when suitably configured for low latency, but even in this setup, other options can perform two or more orders of magnitude better.
Published at DZone with permission of Peter Lawrey. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments