How to Automatically Migrate All Tables From a Database to Hadoop With No Coding
This is a great tool for instantly moving over tables from relational databases. This is also a great way to quickly build up a data lake.
Join the DZone community and get the full member experience.
Join For FreeA company wants to know when new tables are added to a JDBC source (say an RDBMS). Using the ListDatabaseTables processor, we can get a list of tables (also views, system tables, and other database objects), but for our purposes, we want tables with data. I have used the ngdbc.jar from SAP HANA to connect and query tables with ease.
For today's example, I am connecting to MySQL, as I have a MySQL database available for use and modification.
This is a great tool for instantly moving over tables from relational databases. This is also a great way to quickly build up a data lake.
Pre-step:
mysql -u root -p test < person.sql
CREATE USER 'nifi'@'%' IDENTIFIED BY 'reallylongDifficultPassDF&^D&F^Dwird';
GRANT ALL PRIVILEGES ON *.* TO 'nifi'@'%' WITH GRANT OPTION;
COMMIT;
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| MOCK_DATA |
| mock2 |
| personReg |
| visitor |
+----------------+
4 rows in set (0.00 sec)I created a user to use for my JDBC Connection Pool in NiFi to read the metadata and data.
These table names will show up in NiFi in the db.table.name attribute.
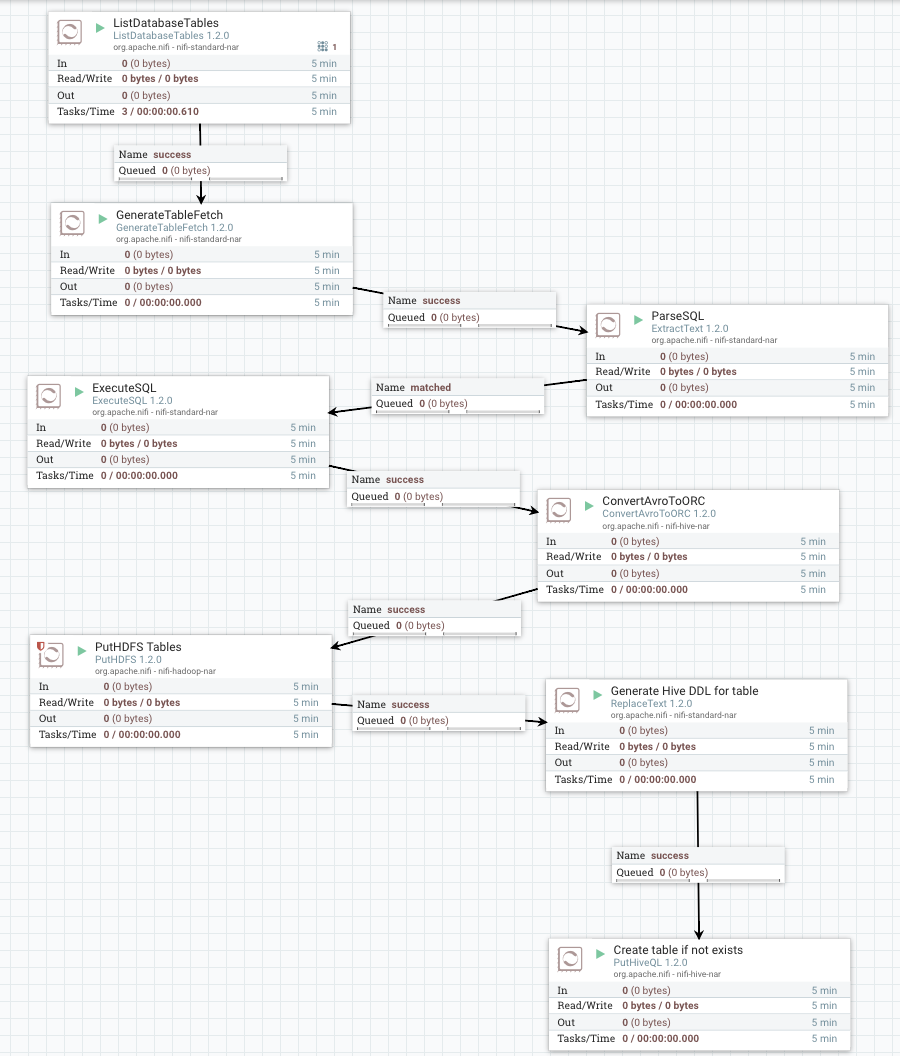
1. ListDatabaseTables
Let's get a list of all the tables in MySQL for the database we have chosen. After it starts running, you can check its state and see what tables were ingested and the most recent timestamp (value).
We will get back what catalog we read from, how many tables, and each table name and it's full name. HDF NiFi supports generic JDBC drivers and specific coding for Oracle, MS SQL Server 2008, and MS SQL Server 2012+.
2. GenerateTableFetch
GenerateTableFetch using the table name returned from the list returned by the database control.
3. Get the SQL Statement
We extract text to get the SQL statement created by GenerateTableFetch.
We add a new attribute, sql, with value, ^(.*).
4. Execute SQL
Execute SQL with the $sql attribute.
5. Convert AVRO Files
Convert the AVRO produced by the executed SQL into performant Apache ORC files.
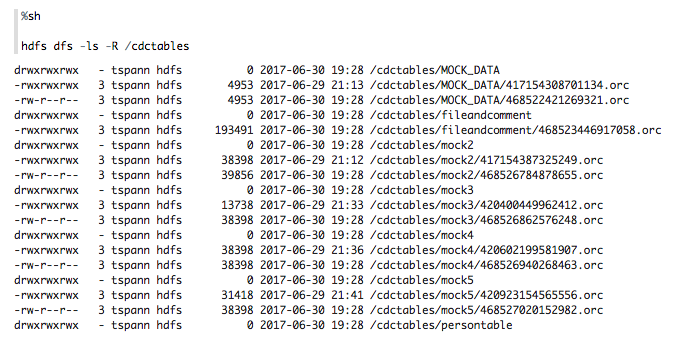
6. Put HDFS to Store These ORC Files in Hadoop
I added the table name as part of the directory structure so a new directory is created for each transferred table. Now we have dynamic HDFS directory structure creation.
7. Build a SQL Statement
Replace text to build a SQL statement that will generate an external Hive table on our new ORC directory.
8. Execute the Statement
Put Hive SQL to execute the statement that was just dynamically created for our new table.
We no have instantly queryable Hadoop data available to Hive, SparkSQL, Zeppelin, ODBC, JDBC and a ton of BI tools and interfaces.
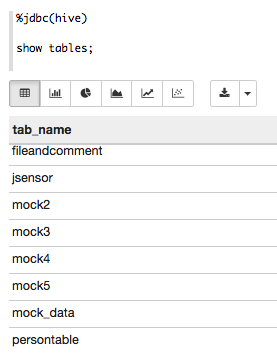
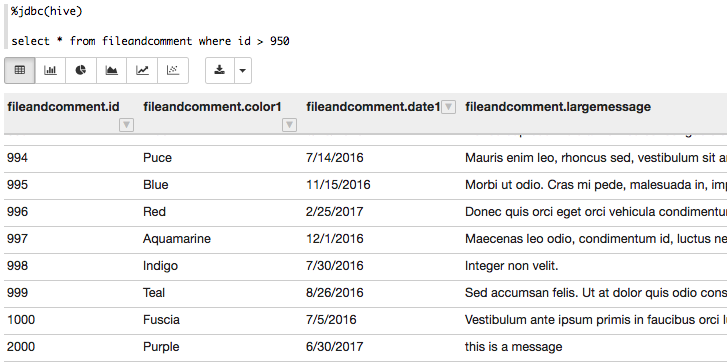
9. Look at the Data!
Finally, we can look at the data that we have ingested from MySQL into new Hive tables.
That was easy! The best part is that as new tables are added to MySQL, they will be automatically ingested into HDFS and the Hive tables built.
You can download the Apache NiFi template from here.
See below:
Opinions expressed by DZone contributors are their own.
Comments