How to Export Jupyter Notebooks Into Other Formats
Let's check out a tutorial that explains how to export Jupyter notebooks into other formats.
Join the DZone community and get the full member experience.
Join For Freewhen working with jupyter notebook, you will find yourself needing to distribute your notebook as something other than a notebook file. the most likely reason is that you want to share the content of your notebook to non-technical users that don't want to install python or the other dependencies necessary to use your notebook. the most popular solution for exporting your notebook into other formats is the built-in tool. you can use nbconvert to export to the following formats:
- html (-to html)
- latex (-to latex)
- pdf (-to pdf)
- reveal js (-to slides)
- markdown (md) (-to markdown)
- restructured text (rst) (-to rst)
- executable script (-to script)
the nbconvert tool uses jinja templates to convert your notebook files ( .ipynb ) to these other static formats. jinja is a template engine for python. the nbconvert tool depends on pandoc and tex for some of the conversions that it does. you may need to install these separately on your machine. this is documented on readthedocs .
using nbconvert
the first thing we need is a notebook that we want to convert. i did a presentation on python decorators where i used a jupyter notebook. we will use that one. you can get it on github . if you would like to use something else, feel free to go download your favorite notebook. i also found this gallery of interesting notebooks that you could use for too.
the notebook that we will be using is called decorators.ipynb . the typical command you use to export using nbconvert is as follows:
the default output format is html. but let's start out by trying to convert the decorators notebook into a pdf:
jupyter nbconvert decorators.ipynb --to pdfi won't mention this for every nbconvert run, but when i ran this command, i got the following output in my terminal:
[nbconvertapp] converting notebook decorators.ipynb to pdf
[nbconvertapp] writing 45119 bytes to notebook.tex
[nbconvertapp] building pdf
[nbconvertapp] running xelatex 3 times: [u'xelatex', u'notebook.tex' ]
[nbconvertapp] running bibtex 1 time: [u'bibtex', u'notebook' ]
[nbconvertapp] warning | bibtex had problems, most likely because there were no citations
[nbconvertapp] pdf successfully created
[nbconvertapp] writing 62334 bytes to decorators.pdfyou will see something similar when you convert your notebook to other formats, although the output will differ obviously. this is what the output looked like:
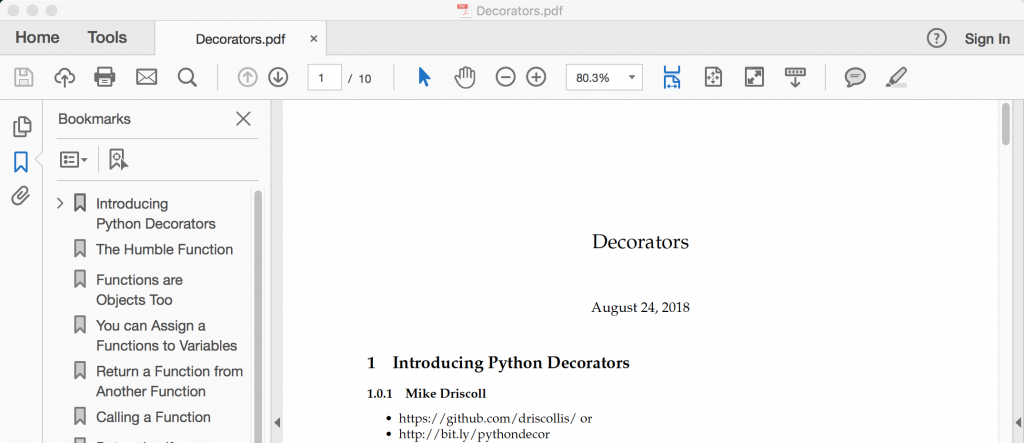
if you convert a notebook to restructuredtext or latex, then nbconvert will use pandoc underneath the covers to do the conversion. that means that pandoc is a dependency that you may need to install before you can do a conversion to one of those formats.
let's try converting our notebook to markdown just to see what we get:
jupyter nbconvert decorators.ipynb --to markdownwhen you run this command, you will get output that looks like this:
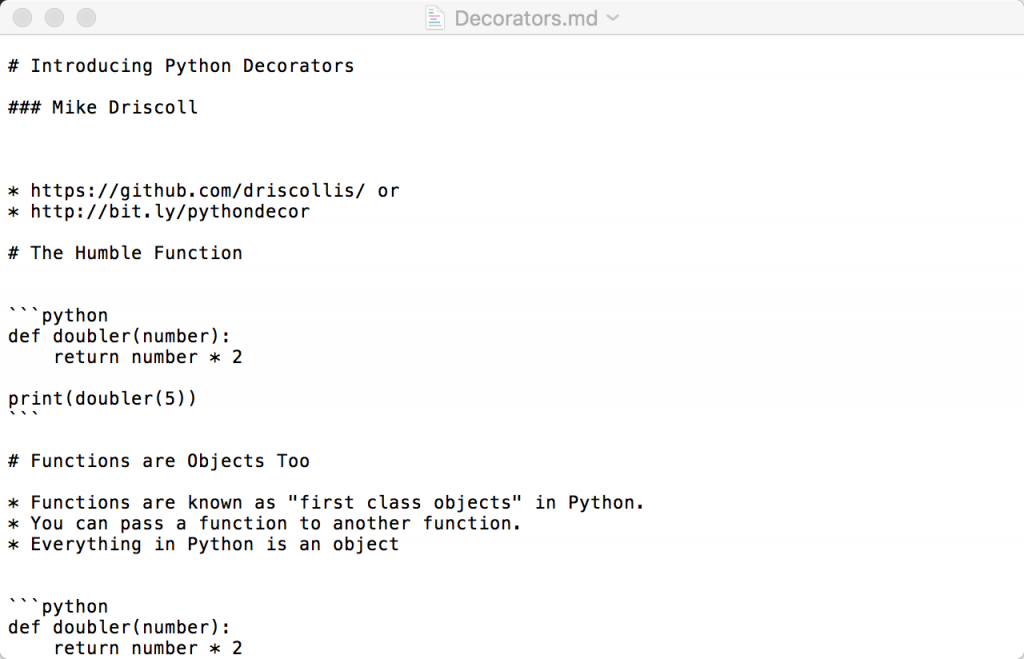
let's do one conversion of our notebook. for this conversion, we will turn our notebook into html. the html conversion actually has two modes:
- -template full (default)
- -template basic
the full version will make the html render of the notebook look very much like a regular notebook looks when it is in its "interactive view" whereas the basic version uses html headers and is mostly aimed at people who want to embed the notebook in a web page or blog. let's give it a try:
jupyter nbconvert decorators.ipynb --to htmlwhen i ran this, i got a nice single html file. if you open the html in your web browser, you should see the following:
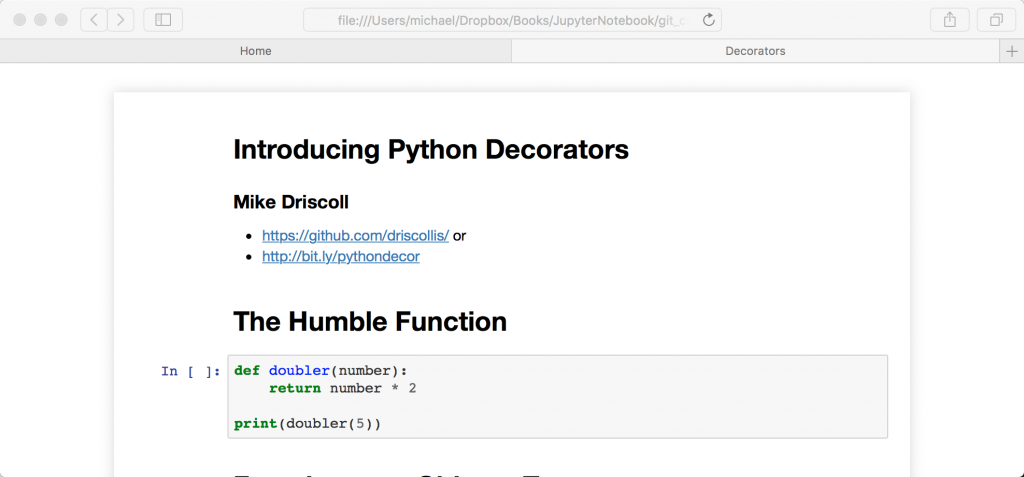
converting multiple notebooks
the nbconvert utility also supports converting multiple notebooks at once. if you have a set of notebooks with similar names, you could use the following command:
jupyter nbconvert notebook*.ipynb --to formatthis would convert all the notebooks in your folder to the format you specify as long as the notebook began with "notebook". you can also just provide a space delimited list of notebooks to nbconvert:
jupyter nbconvert decorators.ipynb my_other_notebook.ipynb --to formatif you have many notebooks, another method of converting them in bulk is to create a python script that acts as configuration file. according to this documentation , you can create a python script with the following contents:
if you save this, you can then run it using the following command:
jupyter nbconvert --config mycfg.pythis will then convert the listed notebooks to the format of your choice.
executing notebooks
as you might expect, most of the time, jupyter notebooks are saved with the output cells cleared. what this means is that when you run the conversion you won't get the output in your export automatically. to do this feat, you must use the -execute flag. here is an example:
jupyter nbconvert --execute my_notebook.ipynb --to pdfnote that the code in your notebook cannot have any errors or the conversion will fail. this is why i am not using the decorators notebook in this example as i have some purposely created cells that fail for demonstration purposes.
executing notebooks with python
you can also create a python script that you can use to execute your notebooks programmatically. let's write some code that will run all the cells in my decorators notebook including the ones that will throw exceptions. let's create an empty python script and name it notebook_runner.py . enter the following code into your editor:
the first items of interest are at the top of the code. here we import nbformat and a preprocessor from nbconvert.preprocessors that is called executepreprocessor . next, we create a function called run_notebook that accepts a path to the notebook that we want to run. inside of this function, we extract the file name and the directory name from the path that we passed in.
then we read the notebook file using nbformat.read . you will note that you can tell nbformat what version to read the file as. be sure to set this to match whichever version of jupyter notebook you are using. the next step is to instantiate the executepreprocessor class. here we give it a timeout and the kernel name. if you were using something other than python this is where you would want to specify that information.
since we want to ignore errors, we set the allow_errors attribute to true . the default is false . if we hadn't done this, we would need to wrap the next step in a try/except block. anyway, we then tell python to do the preprocessing via the preprocess method call. you will note that we need to pass in the notebook data that we read as well as tell it where the notebook is located via a dictionary of metadata. be sure to update this if your path is different than the one used in this example.
finally, we create the output path and write out our the notebook to a new location. if you open it up, you should see output for all of the code cells that actually produce output.
configuration
the nbconvert utility has many configuration options that you can use to customize how it works. for full details, i recommend reading the documentation here .
wrapping up
in this article, we learned how to export/convert our jupyter notebooks into other formats such as html, markdown, and pdf. we also learned that we can convert multiple notebooks at once in several different ways. finally, we learned different ways to execute a notebook before exporting it.
Published at DZone with permission of Mike Driscoll. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments