Create a Single Microservices Endpoint With GraphQL, Kotlin, and Micronaut
In today’s article, you will see an example on how to implement a GraphQL API on the JVM, particularly using Kotlin language and Micronaut framework.
Join the DZone community and get the full member experience.
Join For FreeGraphQL is a query language for APIs that was developed by Facebook. In today’s article, you will see an example on how to implement a GraphQL API on the JVM, particularly using Kotlin language and Micronaut framework. Most of the examples below are reusable on other Java/Kotlin frameworks. Then, we will consider how to combine multiple GraphQL services into a single data graph to provide a unified interface for querying all of your backing data sources. This is implemented using Apollo Server and Apollo Federation. Finally, the following architecture will be obtained:
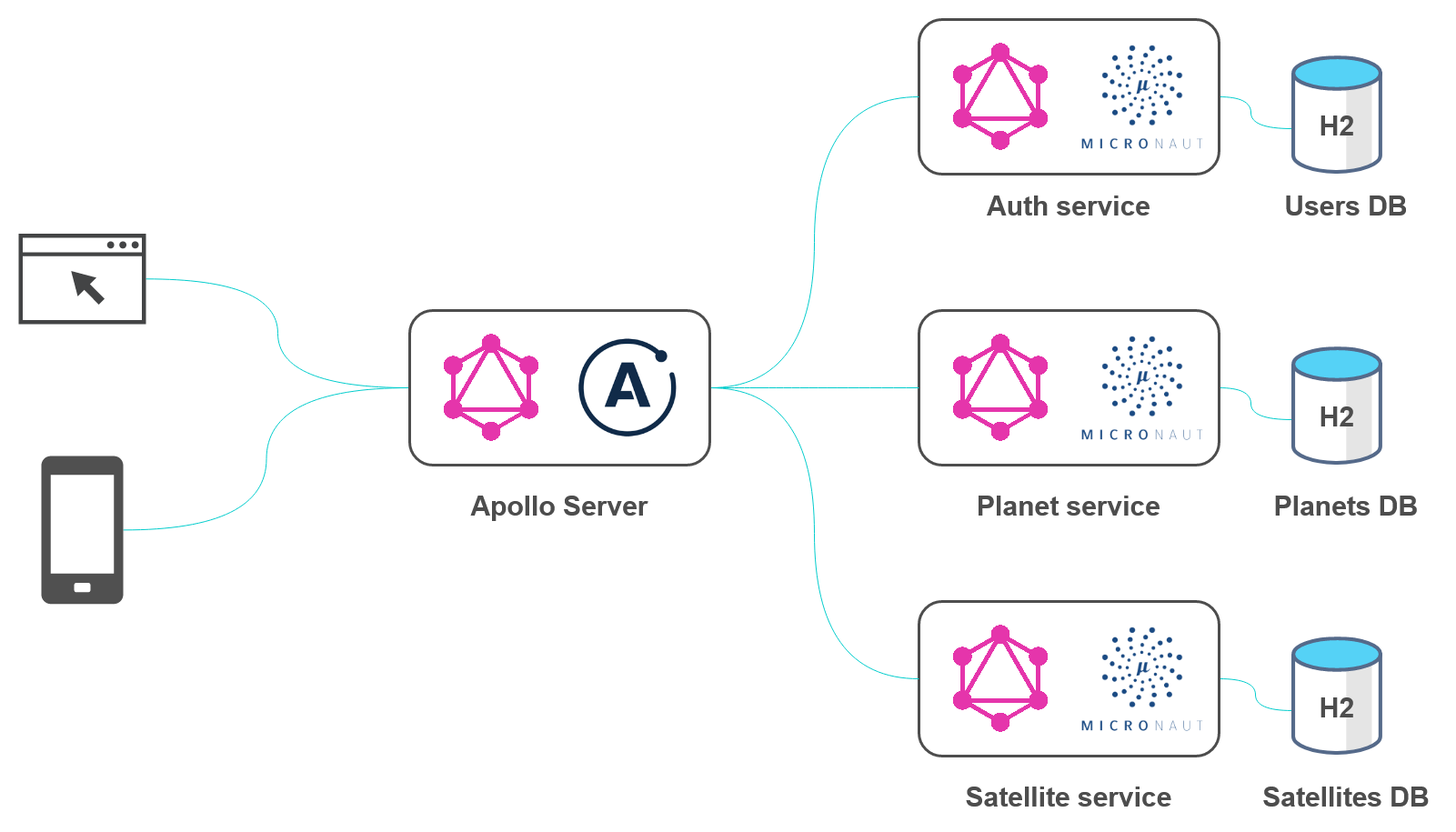
Each component of the architecture answers several questions that may arise when implementing GraphQL API. The domain model includes data about planets in the Solar System and their satellites.
Prerequisites
You might also like: Microservices in Practice: From Architecture to Deployment
Planet Service
The main dependencies related to GraphQL are given below:
implementation("io.micronaut.graphql:micronaut-graphql:$micronautGraphQLVersion")
implementation("io.gqljf:graphql-java-federation:$graphqlJavaFederationVersion")
GraphQL dependencies (source code)
The first provides integration between GraphQL Java and Micronaut, i.e., defines common beans such as GraphQL controller and others. GraphQL controller is just a regular controller in terms of Spring and Micronaut; it processes GET and POST requests to /graphql path. The second dependency is a library that adds support of Apollo Federation to applications that are using GraphQL Java.
GraphQL schema is written in Schema Definition Language (SDL) and lives in the service’s resources:
xxxxxxxxxx
type Query {
planets: [Planet!]!
planet(id: ID!): Planet
planetByName(name: String!): Planet
}
type Mutation {
createPlanet(name: String!, type: Type!, details: DetailsInput!): Planet!
}
type Subscription {
latestPlanet: Planet!
}
type Planet (fields: "id") {
id: ID!
name: String!
# from an astronomical point of view
type: Type!
isRotatingAroundSun: Boolean! (reason: "Now it is not in doubt. Do not use this field")
details: Details!
}
interface Details {
meanRadius: Float!
mass: BigDecimal!
}
type InhabitedPlanetDetails implements Details {
meanRadius: Float!
mass: BigDecimal!
# in billions
population: Float!
}
type UninhabitedPlanetDetails implements Details {
meanRadius: Float!
mass: BigDecimal!
}
enum Type {
TERRESTRIAL_PLANET
GAS_GIANT
ICE_GIANT
DWARF_PLANET
}
input DetailsInput {
meanRadius: Float!
mass: MassInput!
population: Float
}
input MassInput {
number: Float!
tenPower: Int!
}
scalar BigDecimal
Schema of Planet service (source code)
Planet.id field has type ID which is one of the 5 default scalar types. GraphQL Java adds several scalar types and provides the ability to write custom scalars. The presence of the exclamation mark after type name means that a field cannot be null and vice versa (you may notice the similarities between Kotlin and GraphQL in their ability to define nullable types). @directive s will be discussed later. To learn more about GraphQL schemas and their syntax see, for example, an official guide. If you use IntelliJ IDEA, you can install JS GraphQL plugin to work with schemas.
There are two approaches to GraphQL API development:
schema-first
First design the schema (and therefore the API), then implement it in code
code-first
Schema is generated automatically based on code
Both have their pros and cons; you can find more on the topic in this blog post. For this project (and for the article) I decided to use the schema-first way. You can find a tool for either approach on this page.
There is an option in Micronaut application’s config which enables GraphQL IDE — GraphiQL — what allows making GraphQL requests from a browser:
xxxxxxxxxx
graphql
graphiql
enabledtrue
Switching on GraphiQL (source code)
Main class doesn’t contain anything unusual:
xxxxxxxxxx
object PlanetServiceApplication {
@JvmStatic
fun main(args: Array<String>) {
Micronaut.build()
.packages("io.graphqlfederation.planetservice")
.mainClass(PlanetServiceApplication.javaClass)
.start()
}
}
Main class (source code)
GraphQL bean is defined in this way:
xxxxxxxxxx
@Bean
@Singleton
fun graphQL(resourceResolver: ResourceResolver): GraphQL {
val schemaInputStream = resourceResolver.getResourceAsStream("classpath:schema.graphqls").get()
val transformedGraphQLSchema = FederatedSchemaBuilder()
.schemaInputStream(schemaInputStream)
.runtimeWiring(createRuntimeWiring())
.excludeSubscriptionsFromApolloSdl(true)
.build()
return GraphQL.newGraphQL(transformedGraphQLSchema)
.instrumentation(
ChainedInstrumentation(
listOf(
FederatedTracingInstrumentation()
// uncomment if you need to enable the instrumentations. but this may affect showing documentation in a GraphQL client
// MaxQueryComplexityInstrumentation(50),
// MaxQueryDepthInstrumentation(5)
)
)
)
.build()
}
GraphQL configuration (source code)
FederatedSchemaBuilder class makes a GraphQL application adapted to the Apollo Federation specification. If you are not going to combine multiple GraphQL Java services into a single graph, then a configuration will be different (see this tutorial).
RuntimeWiring object is a specification of data fetchers, type resolvers and custom scalars that are needed to wire together a functional GraphQLSchema; it is defined as follows:
xxxxxxxxxx
private fun createRuntimeWiring(): RuntimeWiring {
val detailsTypeResolver = TypeResolver { env ->
when (val details = env.getObject() as DetailsDto) {
is InhabitedPlanetDetailsDto -> env.schema.getObjectType("InhabitedPlanetDetails")
is UninhabitedPlanetDetailsDto -> env.schema.getObjectType("UninhabitedPlanetDetails")
else -> throw RuntimeException("Unexpected details type: ${details.javaClass.name}")
}
}
return RuntimeWiring.newRuntimeWiring()
.type("Query") { builder ->
builder
.dataFetcher("planets", planetsDataFetcher)
.dataFetcher("planet", planetDataFetcher)
.dataFetcher("planetByName", planetByNameDataFetcher)
}
.type("Mutation") { builder ->
builder.dataFetcher("createPlanet", createPlanetDataFetcher)
}
.type("Subscription") { builder ->
builder.dataFetcher("latestPlanet", latestPlanetDataFetcher)
}
.type("Planet") { builder ->
builder.dataFetcher("details", detailsDataFetcher)
}
.type("Details") { builder ->
builder.typeResolver(detailsTypeResolver)
}
.type("Type") { builder ->
builder.enumValues(NaturalEnumValuesProvider(Planet.Type::class.java))
}
.build()
}
Creating a RuntimeWiring object (source code)
For the root type Query (other root types are Mutation and Subscription), for instance, planets field is defined in the schema, therefore it is needed to provide a DataFetcher for it:
xxxxxxxxxx
@Singleton
class PlanetsDataFetcher(
private val planetService: PlanetService,
private val planetConverter: PlanetConverter
) : DataFetcher<List<PlanetDto>> {
override fun get(env: DataFetchingEnvironment): List<PlanetDto> = planetService.getAll()
.map { planetConverter.toDto(it) }
}
PlanetsDataFetcher (source code)
Here the env input parameter contains all the context that is needed to fetch a value. The method just gets all the items from a repository and converts them into DTO. Conversion is performed in this way:
xxxxxxxxxx
@Singleton
class PlanetConverter : GenericConverter<Planet, PlanetDto> {
override fun toDto(entity: Planet): PlanetDto {
val details = DetailsDto(id = entity.detailsId)
return PlanetDto(
id = entity.id,
name = entity.name,
type = entity.type,
details = details
)
}
}
PlanetConverter (source code)
GenericConverter is just a common interface for Entity → DTO transformation. Let’s suppose details is a heavy field, then we should return it only if it was requested. So in the snippet above only simple properties are converted and for details object only id field is filled. Earlier, in the definition of the RuntimeWiring object, DataFetcher for details field of Planet type was specified; it is defined as follows (it needs to know a value of details.id field):
xxxxxxxxxx
@Singleton
class DetailsDataFetcher : DataFetcher<CompletableFuture<DetailsDto>> {
private val log = LoggerFactory.getLogger(this.javaClass)
override fun get(env: DataFetchingEnvironment): CompletableFuture<DetailsDto> {
val planetDto = env.getSource<PlanetDto>()
log.info("Resolve `details` field for planet: ${planetDto.name}")
val dataLoader: DataLoader<Long, DetailsDto> = env.getDataLoader("details")
return dataLoader.load(planetDto.details.id)
}
}
DetailsDataFetcher (source code)
Here you see that it is possible to return CompletableFuture instead of an actual object. More simple would be just to get Details entity from DetailsService, but this would be a naive implementation that leads to the N+1 problem: if we would make GraphQL request say:
xxxxxxxxxx
{
planets {
name
details {
meanRadius
}
}
}
Example of possible resource-consuming GraphQL request
then for each planet’s details field separate SQL call would be made. To prevent this, java-dataloader library is used; BatchLoader and DataLoaderRegistry beans should be defined:
xxxxxxxxxx
// bean's scope is `Singleton`, because `BatchLoader` is stateless
@Bean
@Singleton
fun detailsBatchLoader(): BatchLoader<Long, DetailsDto> = BatchLoader { keys ->
CompletableFuture.supplyAsync {
detailsService.getByIds(keys)
.map { detailsConverter.toDto(it) }
}
}
// bean's (default) scope is `Prototype`, because `DataLoader` is stateful
@Bean
fun dataLoaderRegistry() = DataLoaderRegistry().apply {
val detailsDataLoader = DataLoader.newDataLoader(detailsBatchLoader())
register("details", detailsDataLoader)
}
BatchLoader and DataLoaderRegistry (source code)
BatchLoader makes it possible to get a bunch of Details at once. Therefore, only two SQL calls will be performed instead of N+1 requests. You can make sure of it by making the GraphQL request above and seeing at the application’s log where actual SQL queries will be shown. BatchLoader is stateless, so it may be a singleton object. DataLoader simply points to the BatchLoader; it is stateful, therefore, it should be created per request as well as DataLoaderRegistry. Depending on your business requirements you may need to share data across web requests which is also possible. More on batching and caching is in the GraphQL Java documentation.
Details in GraphQL schema is defined as an interface, therefore, at the first part of the RuntimeWiring object’s definition TypeResolver object is created to specify to what concrete GraphQL type what DTO should be resolved:
xxxxxxxxxx
val detailsTypeResolver = TypeResolver { env ->
when (val details = env.getObject() as DetailsDto) {
is InhabitedPlanetDetailsDto -> env.schema.getObjectType("InhabitedPlanetDetails")
is UninhabitedPlanetDetailsDto -> env.schema.getObjectType("UninhabitedPlanetDetails")
else -> throw RuntimeException("Unexpected details type: ${details.javaClass.name}")
}
}
TypeResolver (source code)
It is also needed to specify Java runtime values for values of Type enum defined in the schema (it seems like this is necessary only for using an enum in mutations):
xxxxxxxxxx
.type("Type") { builder ->
builder.enumValues(NaturalEnumValuesProvider(Planet.Type::class.java))
}
Enum processing (source code)
After launching a service, you can navigate to http://localhost:8082/graphiql and see GraphiQL IDE, in which it is possible to make any requests defined in the schema; the IDE is divided into three parts: request (query/mutation/subscription), response, and documentation:
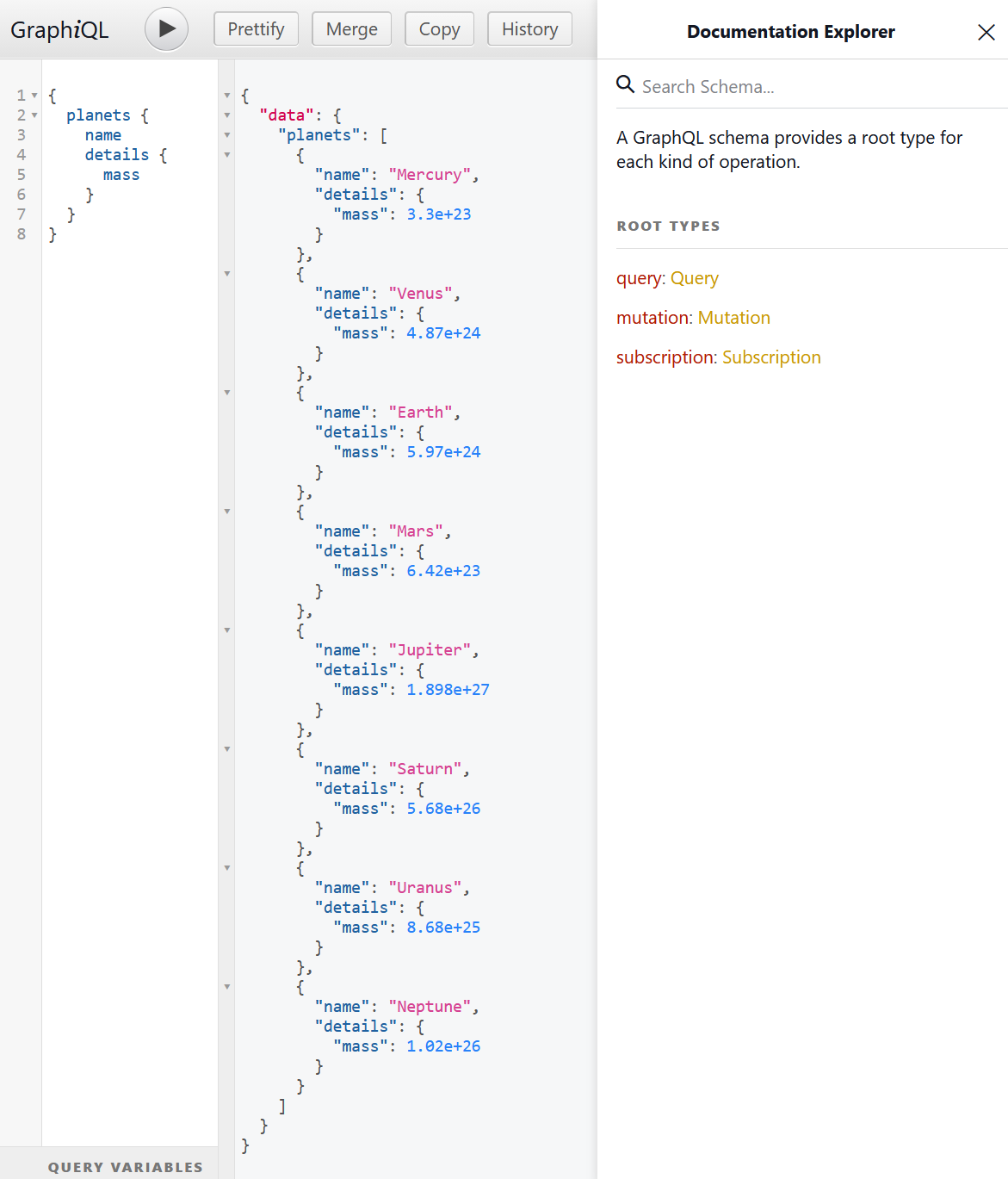
There are other GraphQL IDEs, for example, GraphQL Playground and Altair (which is available as a desktop application, browser extension, and web page). The latter I will use further:
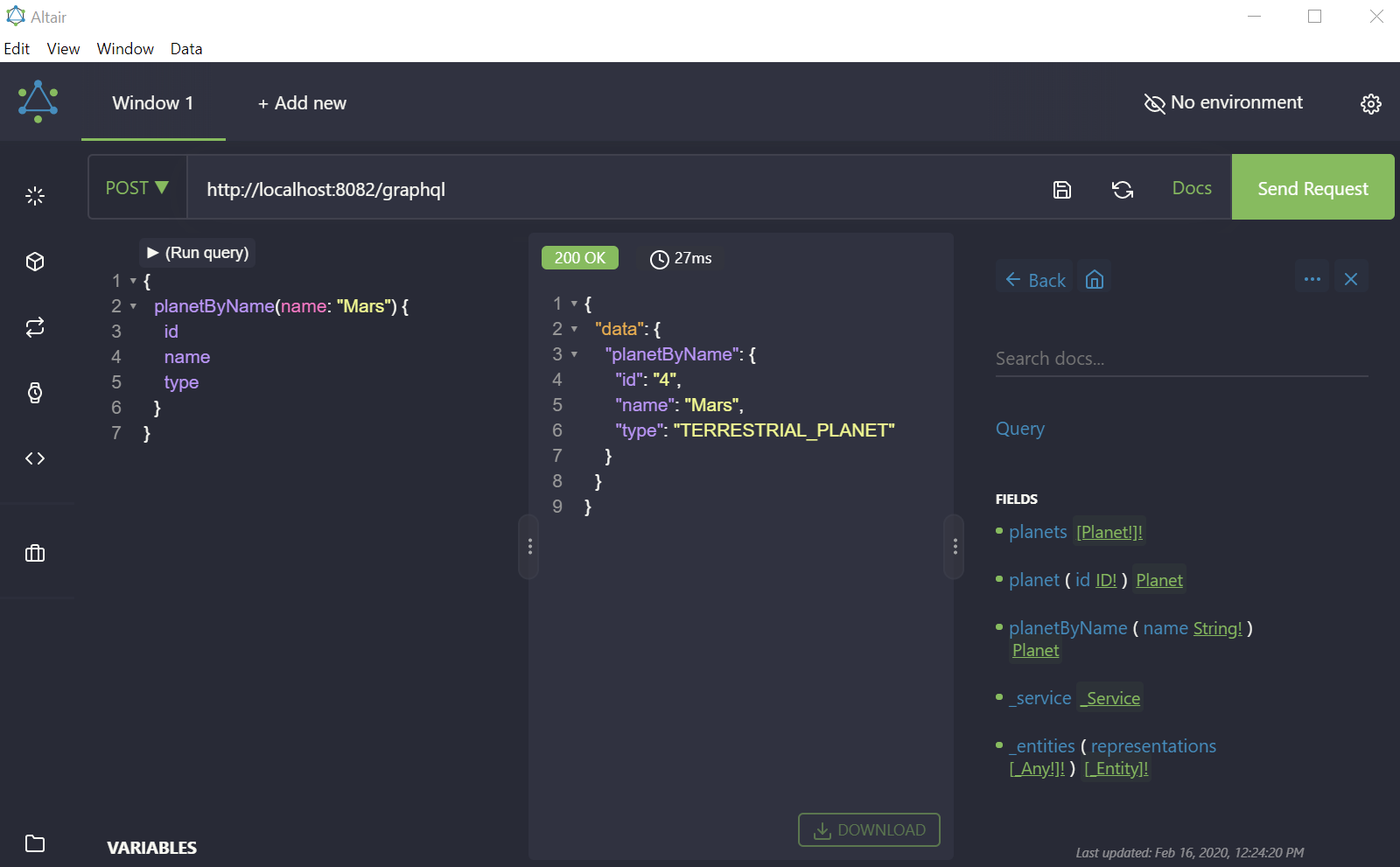
On the documentation part, there are two additional queries besides defined in the schema: _service and _entities. They are created by the library that adapts the application to the Apollo Federation specification; this question will be discussed later.
If you navigate to the Planet type, you will see its definition:
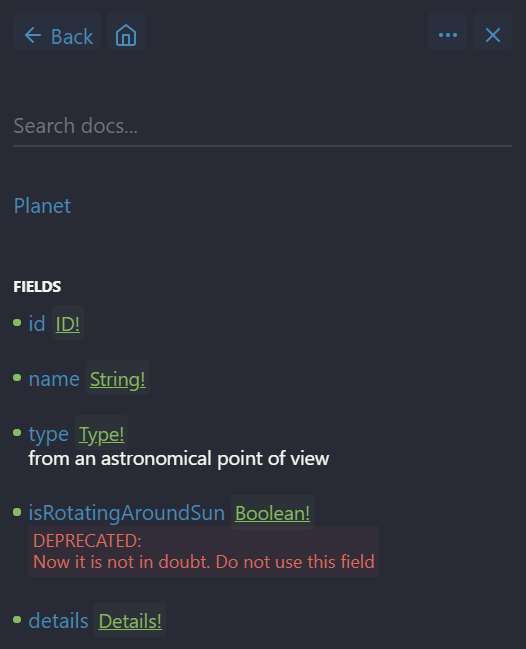
Both the comment for type field and the @deprecated directive for isRotatingAroundSun field are specified in the schema.
There is one mutation defined in the schema:
xxxxxxxxxx
type Mutation {
createPlanet(name: String!, type: Type!, details: DetailsInput!): Planet!
}
Mutation (source code)
As a query, it also allows requesting fields of a returning type. Note that if you need to pass an object as an input parameter, input type should be used instead of queries' type:
xxxxxxxxxx
input DetailsInput {
meanRadius: Float!
mass: MassInput!
population: Float
}
input MassInput {
number: Float!
tenPower: Int!
}
Input type
As for a query, DataFetcher should be defined for a mutation:
xxxxxxxxxx
@Singleton
class CreatePlanetDataFetcher(
private val objectMapper: ObjectMapper,
private val planetService: PlanetService,
private val planetConverter: PlanetConverter
) : DataFetcher<PlanetDto> {
private val log = LoggerFactory.getLogger(this.javaClass)
override fun get(env: DataFetchingEnvironment): PlanetDto {
log.info("Trying to create planet")
val name = env.getArgument<String>("name")
val type = env.getArgument<Planet.Type>("type")
val detailsInputDto = objectMapper.convertValue(env.getArgument("details"), DetailsInputDto::class.java)
val newPlanet = planetService.create(
name,
type,
detailsInputDto.meanRadius,
detailsInputDto.mass.number,
detailsInputDto.mass.tenPower,
detailsInputDto.population
)
return planetConverter.toDto(newPlanet)
}
}
DataFetcher for the mutation (source code)
Let’s suppose that someone wants to be notified of a planet adding event. For such a purpose subscription can be used:
xxxxxxxxxx
type Subscription {
latestPlanet: Planet!
}
Subscription (source code)
The subscription’s DataFetcher returns Publisher:
xxxxxxxxxx
@Singleton
class LatestPlanetDataFetcher(
private val planetService: PlanetService,
private val planetConverter: PlanetConverter
) : DataFetcher<Publisher<PlanetDto>> {
override fun get(environment: DataFetchingEnvironment) = planetService.getLatestPlanet().map { planetConverter.toDto(it) }
}
DataFetcher for subscription (source code)
To test the mutation and the subscription open two tabs of any GraphQL IDE or two different IDEs; in the first subscribe as follows (it may be required to set subscription URL ws://localhost:8082/graphql-ws):
xxxxxxxxxx
subscription {
latestPlanet {
name
type
}
}
Request for subscription
In the second perform mutation like this:
xxxxxxxxxx
mutation {
createPlanet(
name: "Pluto"
type: DWARF_PLANET
details: { meanRadius: 50.0, mass: { number: 0.0146, tenPower: 24 } }
) {
id
}
}
Request for mutation
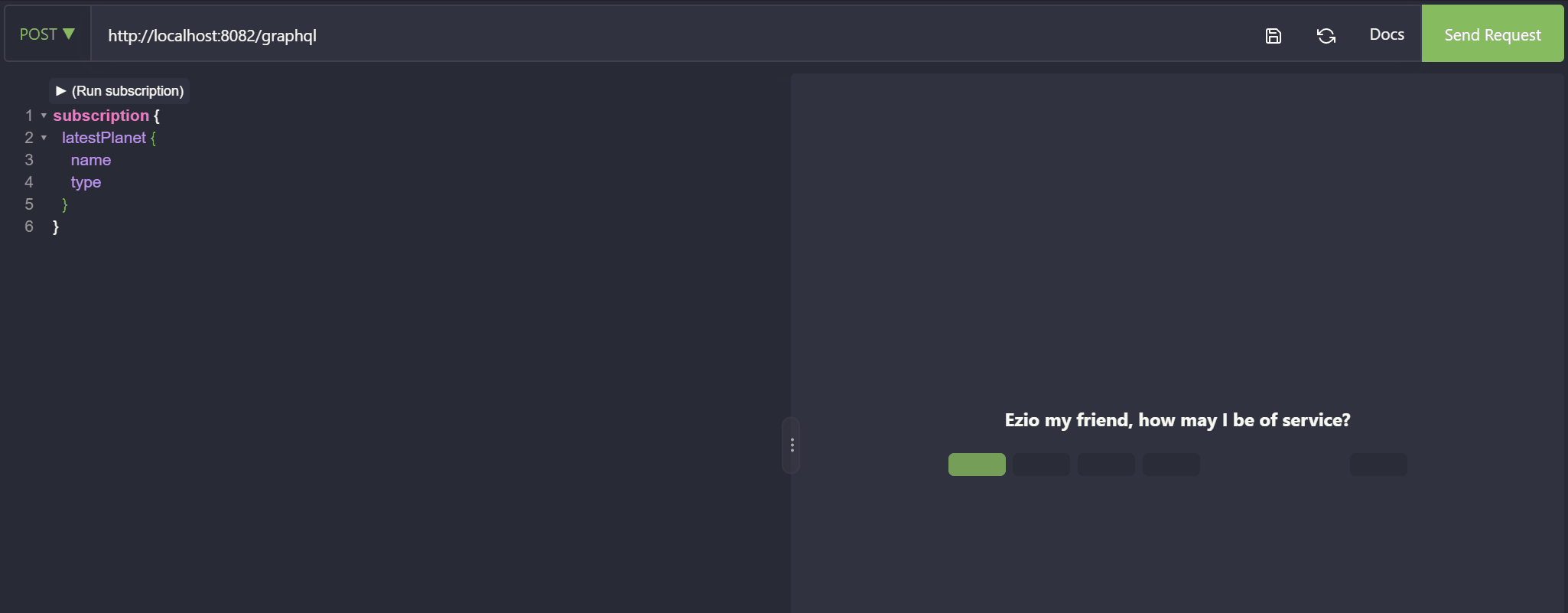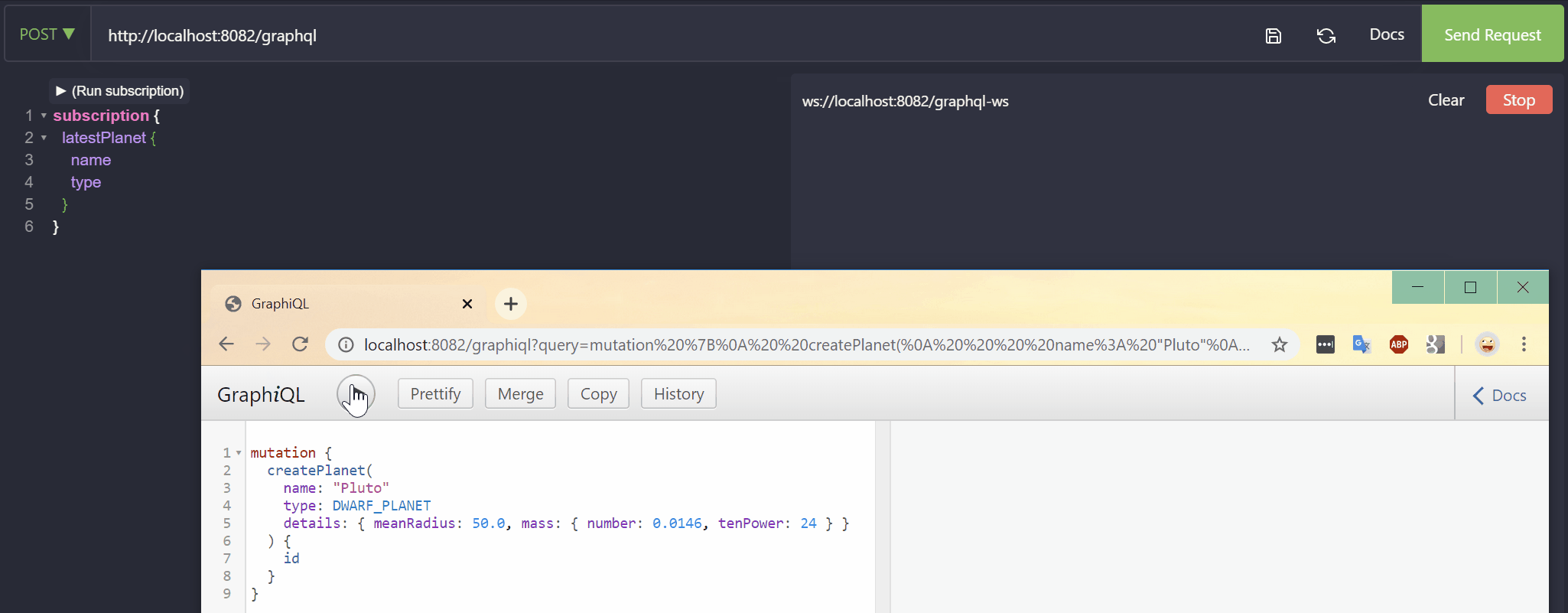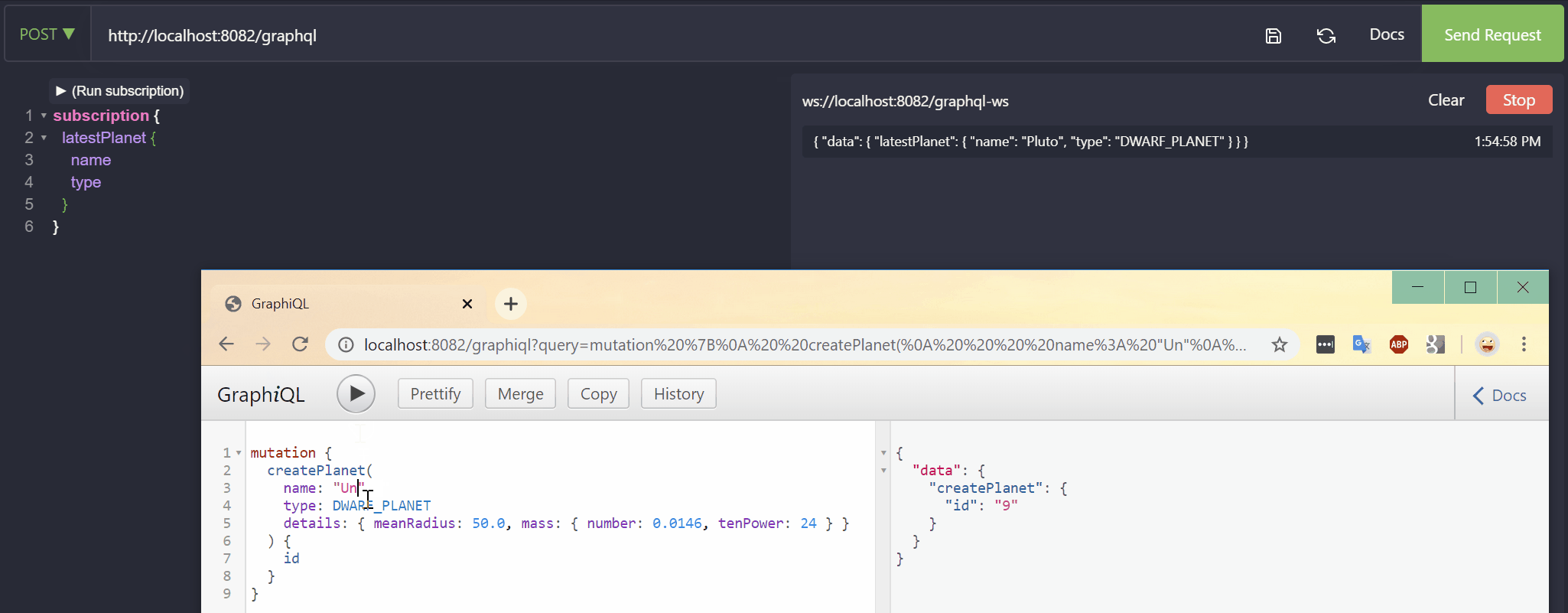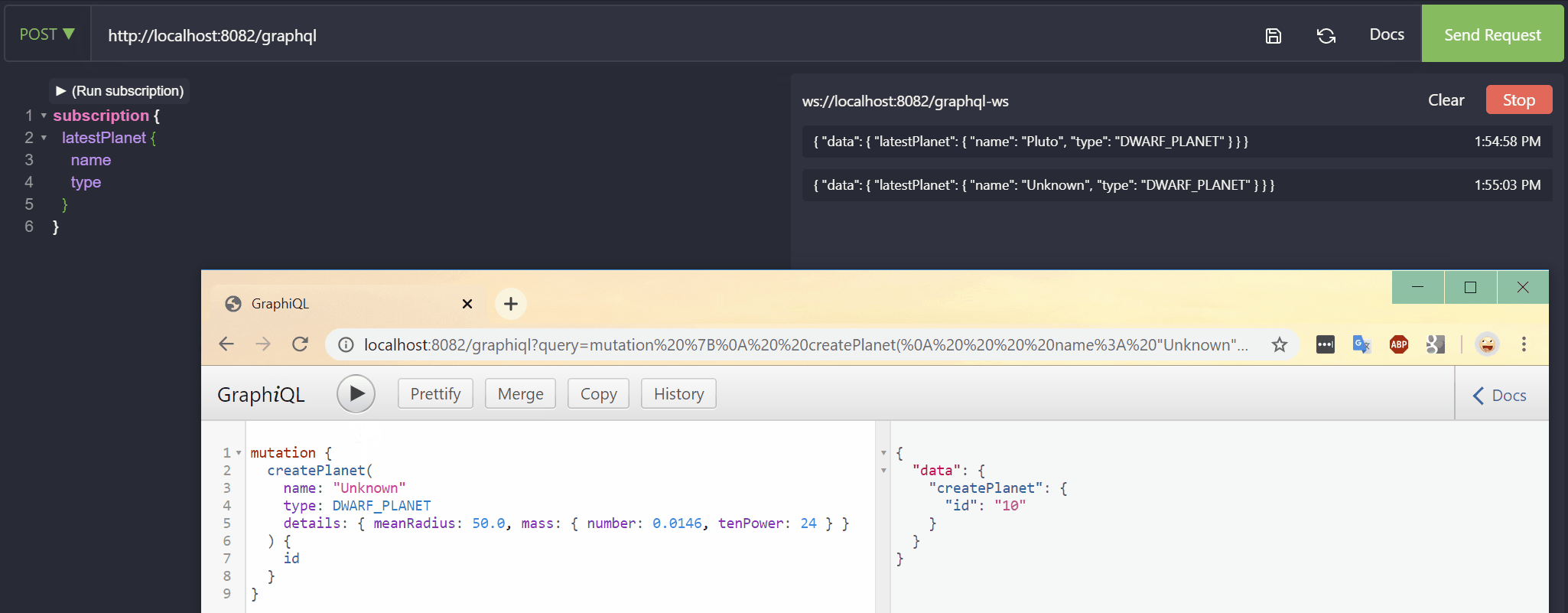
The subscribed client will be notified of a planet creation:
Subscriptions in Micronaut are enabled by using the following option:
xxxxxxxxxx
graphql
graphql-ws
enabledtrue
Switching on GraphQL over WebSocket (source code)
Another example of subscriptions in Micronaut is a chat application. For more information on subscriptions, see GraphQL Java documentation.
Tests for queries and mutations can be written like this:
xxxxxxxxxx
@Test
fun testPlanets() {
val query = """
{
planets {
id
name
type
details {
meanRadius
mass
... on InhabitedPlanetDetails {
population
}
}
}
}
""".trimIndent()
val response = graphQLClient.sendRequest(query, object : TypeReference<List<PlanetDto>>() {})
assertThat(response, hasSize(8))
assertThat(
response, contains(
hasProperty("name", `is`("Mercury")),
hasProperty("name", `is`("Venus")),
hasProperty("name", `is`("Earth")),
hasProperty("name", `is`("Mars")),
hasProperty("name", `is`("Jupiter")),
hasProperty("name", `is`("Saturn")),
hasProperty("name", `is`("Uranus")),
hasProperty("name", `is`("Neptune"))
)
)
}
Query test (source code)
If a part of a query can be reused in another query, you can use fragments:
xxxxxxxxxx
private val planetFragment = """
fragment planetFragment on Planet {
id
name
type
details {
meanRadius
mass
... on InhabitedPlanetDetails {
population
}
}
}
""".trimIndent()
@Test
fun testPlanetById() {
val earthId = 3
val query = """
{
planet(id: $earthId) {
... planetFragment
}
}
$planetFragment
""".trimIndent()
val response = graphQLClient.sendRequest(query, object : TypeReference<PlanetDto>() {})
// assertions
}
Query test using a fragment (source code)
To use variables, you can write tests in this way:
xxxxxxxxxx
@Test
fun testPlanetByName() {
val variables = mapOf("name" to "Earth")
val query = """
query testPlanetByName(${'$'}name: String!){
planetByName(name: ${'$'}name) {
... planetFragment
}
}
$planetFragment
""".trimIndent()
val response = graphQLClient.sendRequest(query, variables, null, object : TypeReference<PlanetDto>() {})
// assertions
}
Query test using a fragment and variables (source code)
This approach looks a little strange because in Kotlin raw strings, or string templates, you can’t escape a symbol, so to represent $ you need to write ${'$'}.
Injected GraphQLClient in the snippets above is just a self-written class (it is framework-agnostic by using OkHttp library). There are other Java GraphQL clients, for example, Apollo GraphQL Client for Android and the JVM, but I haven’t used them yet.
Data of all 3 services are stored in H2 in-memory databases and are accessed using Hibernate ORM provided by the micronaut-data-hibernate-jpa library. The databases are initialized with data at the applications' startup.
Auth Service
GraphQL doesn’t provide means for authentication and authorization. For this project, I decided to use JWT. Auth service is only responsible for JWT token issue and validation and contains just one query and one mutation:
xxxxxxxxxx
type Query {
validateToken(token: String!): Boolean!
}
type Mutation {
signIn(data: SignInData!): SignInResponse!
}
input SignInData {
username: String!
password: String!
}
type SignInResponse {
username: String!
token: String!
}
Schema of Auth service (source code)
To get a JWT you need to perform in a GraphQL IDE the following mutation (Auth service URL is http://localhost:8081/graphql):
xxxxxxxxxx
mutation {
signIn(data: {username: "john_doe", password: "password"}) {
token
}
}
Getting JWT
Including the Authorization header to further requests (it is possible in Altair and GraphQL Playground IDEs) allows access to protected resources; this will be shown in the next section. The header value should be specified as Bearer $JWT.
Working with JWT is done using the micronaut-security-jwt library.
Satellite Service
The service’s schema looks like that:
xxxxxxxxxx
type Query {
satellites: [Satellite!]!
satellite(id: ID!): Satellite
satelliteByName(name: String!): Satellite
}
type Satellite {
id: ID!
name: String!
lifeExists: LifeExists!
firstSpacecraftLandingDate: Date
}
type Planet (fields: "id") {
id: ID!
satellites: [Satellite!]!
}
enum LifeExists {
YES,
OPEN_QUESTION,
NO_DATA
}
scalar Date
Schema of Satellite service (source code)
Say in the Satellite type field lifeExists should be protected. Many frameworks offer security approach in which you just need to specify routes and different security policies for them, but such an approach can’t be used to protect some specific GraphQL query/mutation/subscription or types' fields, because all requests are sent to /graphql endpoint. Only you can do is to configure a couple of GraphQL-specific endpoints, for example, as follows (requests to any other endpoints will be disallowed):
xxxxxxxxxx
micronaut
security
enabledtrue
intercept-url-map
pattern/graphql
httpMethodPOST
access
isAnonymous()
pattern/graphiql
httpMethodGET
access
isAnonymous()
Security configuration (source code)
It is not recommended putting authorization logic into DataFetcher to not make an application’s logic brittle:
xxxxxxxxxx
@Singleton
class LifeExistsDataFetcher(
private val satelliteService: SatelliteService
) : DataFetcher<Satellite.LifeExists> {
override fun get(env: DataFetchingEnvironment): Satellite.LifeExists {
val id = env.getSource<SatelliteDto>().id
return satelliteService.getLifeExists(id)
}
}
LifeExistsDataFetcher (source code)
Protection of a field can be done using a framework’s means and custom logic:
xxxxxxxxxx
@Singleton
class SatelliteService(
private val repository: SatelliteRepository,
private val securityService: SecurityService
) {
// other stuff
fun getLifeExists(id: Long): Satellite.LifeExists {
val userIsAuthenticated = securityService.isAuthenticated
if (userIsAuthenticated) {
return repository.findById(id)
.orElseThrow { RuntimeException("Can't find satellite by id=$id") }
.lifeExists
} else {
throw RuntimeException("`lifeExists` property can only be accessed by authenticated users")
}
}
}
SatelliteService (source code)
The following request can only be successful if you will specify the Authorization header with received JWT (see the previous section):
xxxxxxxxxx
{
satellite(id: "1") {
name
lifeExists
}
}
Request for protected field
The service validates token automatically using the framework. The secret is stored in the configuration file (in the Base64 form):
xxxxxxxxxx
micronaut
security
token
jwt
enabledtrue
signatures
secret
validation
base64true
# In real life, the secret should NOT be under source control (instead of it, for example, in environment variable).
# It is here just for simplicity.
secret'TG9yZW0gaXBzdW0gZG9sb3Igc2l0IGFtZXQsIGNvbnNlY3RldHVyIGFkaXBpc2NpbmcgZWxpdA=='
jws-algorithmHS256
JWT configuration (source code)
In real life, the secret can be stored in an environment variable to share it with several services. Also, instead of the sharing validation of the JWT can be used (validateToken method was shown in the previous section).
Such scalar types as Date, DateTime, and some others can be added to GraphQL Java service using graphql-java-extended-scalars library (com.graphql-java:graphql-java-extended-scalars:$graphqlJavaExtendedScalarsVersion in build script). Then the required types should be declared in the schema (scalar Date) and registered:
xxxxxxxxxx
private fun createRuntimeWiring(): RuntimeWiring = RuntimeWiring.newRuntimeWiring()
// other stuff
.scalar(ExtendedScalars.Date)
.build()
Registration of an additional scalar type (source code)
Then they can be used as others:
xxxxxxxxxx
{
satelliteByName(name: "Moon") {
firstSpacecraftLandingDate
}
}
Request
xxxxxxxxxx
{
"data": {
"satelliteByName": {
"firstSpacecraftLandingDate": "1959-09-13"
}
}
}
Response
There are different security threats to your GraphQL API (see this checklist to learn more). For example, if the domain model of the described project was a bit more complex, the following request would be possible:
xxxxxxxxxx
{
planet(id: "1") {
star {
planets {
star {
planets {
star {
... # more deep nesting!
}
}
}
}
}
}
}
Example of expensive query
To make such a request invalid, MaxQueryDepthInstrumentation should be used. To restrict query complexity, MaxQueryComplexityInstrumentation can be specified; it optionally takes FieldComplexityCalculator in which it is possible to define fine-grained calculation criteria. The next code snippet shows an example on how to apply multiple instrumentations (FieldComplexityCalculator there calculates complexity like default one based on the assumption that every field’s cost is 1):
xxxxxxxxxx
return GraphQL.newGraphQL(transformedGraphQLSchema)
// other stuff
.instrumentation(
ChainedInstrumentation(
listOf(
FederatedTracingInstrumentation(),
MaxQueryComplexityInstrumentation(50, FieldComplexityCalculator { env, child ->
1 + child
}),
MaxQueryDepthInstrumentation(5)
)
)
)
.build()
Setup an instrumentation (source code)
Note that if you specify MaxQueryDepthInstrumentation and/or MaxQueryComplexityInstrumentation, then documentation of a service may stop showing in your GraphQL IDE. This is because the IDE tries to perform IntrospectionQuery which has considerable size and complexity (discussion on this is on GitHub). FederatedTracingInstrumentation is used to make your server generate performance traces and return them along with responses to Apollo Gateway (which then can send them to Apollo Graph Manager; it seems like a subscription is needed to use this function). More on instrumentation see in GraphQL Java documentation.
There is an ability to customize requests; it differs in different frameworks. In Micronaut, for example, it is done in this way:
xxxxxxxxxx
@Singleton
// mark it as primary to override the default one
@Primary
class HeaderValueProviderGraphQLExecutionInputCustomizer : DefaultGraphQLExecutionInputCustomizer() {
override fun customize(executionInput: ExecutionInput, httpRequest: HttpRequest<*>): Publisher<ExecutionInput> {
val context = HTTPRequestHeaders { headerName ->
httpRequest.headers[headerName]
}
return Publishers.just(executionInput.transform {
it.context(context)
})
}
}
Example of GraphQLExecutionInputCustomizer (source code)
This customizer provides an ability to FederatedTracingInstrumentation to check whether a request has come from Apollo Server and whether to return performance traces.
To have an ability to handle all exceptions during data fetching in one place and to define custom exception handling logic you need to provide a bean as follows:
xxxxxxxxxx
@Singleton
class CustomDataFetcherExceptionHandler : SimpleDataFetcherExceptionHandler() {
private val log = LoggerFactory.getLogger(this.javaClass)
override fun onException(handlerParameters: DataFetcherExceptionHandlerParameters): DataFetcherExceptionHandlerResult {
val exception = handlerParameters.exception
log.error("Exception while GraphQL data fetching", exception)
val error = object : GraphQLError {
override fun getMessage(): String = "There was an error: ${exception.message}"
override fun getErrorType(): ErrorType? = null
override fun getLocations(): MutableList<SourceLocation>? = null
}
return DataFetcherExceptionHandlerResult.newResult().error(error).build()
}
}
Custom exception handler (source code)
The main purpose of the service is to demonstrate how the distributed GraphQL entity (Planet) can be resolved in two services and then accessed through Apollo Server. Planet type was earlier defined in the Planet service in this way:
xxxxxxxxxx
type Planet (fields: "id") {
id: ID!
name: String!
# from an astronomical point of view
type: Type!
isRotatingAroundSun: Boolean! (reason: "Now it is not in doubt. Do not use this field")
details: Details!
}
Definition of Planet type in Planet service (source code)
Satellite service adds the satellites field (which contains only non-nullable elements and is non-nullable by itself as follows from its declaration) to the Planet entity:
xxxxxxxxxx
type Satellite {
id: ID!
name: String!
lifeExists: LifeExists!
firstSpacecraftLandingDate: Date
}
type Planet (fields: "id") {
id: ID!
satellites: [Satellite!]!
}
Extension of Planet type in Satellite service (source code)
In Apollo Federation terms Planet is an entity — a type that can be referenced by another service (by Satellite service in this case which defines a stub for Planet type). Declaring an entity is done by adding a @key directive to the type definition. This directive tells other services which fields to use to uniquely identify a particular instance of the type. The @extends annotation declares that Planet is an entity defined elsewhere (in Planet service in this case). More on Apollo Federation core concepts see in Apollo documentation.
There are two libraries for supporting Apollo Federation; both are built on top of GraphQL Java but didn’t fit the project:
This is a set of libraries written in Kotlin; it uses the code-first approach without a necessity to define a schema. The project contains
graphql-kotlin-federationmodule, but it seems like you need to use this library in conjunction with other libraries of the project.The project’s development is not very active and the API could be improved.
So I decided to refactor the second library to enhance the API and make it more convenient. The project is on GitHub.
To specify how a particular instance of the Planet entity should be fetched FederatedEntityResolver object is defined (basically, it points what should be filled in the Planet.satellites field); then the resolver is passed to FederatedSchemaBuilder:
xxxxxxxxxx
@Bean
@Singleton
fun graphQL(resourceResolver: ResourceResolver): GraphQL {
// other stuff
val planetEntityResolver = object : FederatedEntityResolver<Long, PlanetDto>("Planet", { id ->
log.info("`Planet` entity with id=$id was requested")
val satellites = satelliteService.getByPlanetId(id)
PlanetDto(id = id, satellites = satellites.map { satelliteConverter.toDto(it) })
}) {}
val transformedGraphQLSchema = FederatedSchemaBuilder()
.schemaInputStream(schemaInputStream)
.runtimeWiring(createRuntimeWiring())
.federatedEntitiesResolvers(listOf(planetEntityResolver))
.build()
// other stuff
}
Definition of GraphQL bean in Satellite service (source code)
The library generates two additional queries (_service and _entities) that will be used by Apollo Server. These queries are internal, i.e., they won’t be exposed by Apollo Server. A service with Apollo Federation support still can work independently. The library’s API may change in the future.
Apollo Server
Apollo Server and Apollo Federation allow achieving 2 main goals:
create a single endpoint for GraphQL APIs' clients
create a single data graph from distributed entities
That is even if you don’t use federated entities, it is more convenient for frontend developers to use a single endpoint than multiple endpoints.
There is another way for creating single GraphQL schema — schema stitching — but now on the Apollo site, it is marked as deprecated. However, there is a library that implements this approach: Nadel. It is written by creators of GraphQL Java and has nothing to do with Apollo Federation; I haven’t used it yet.
This module includes the following sources:
xxxxxxxxxx
{
"name": "api-gateway",
"main": "gateway.js",
"scripts": {
"start-gateway": "nodemon gateway.js"
},
"devDependencies": {
"concurrently": "5.1.0",
"nodemon": "2.0.2"
},
"dependencies": {
"@apollo/gateway": "0.12.0",
"apollo-server": "2.10.0",
"graphql": "14.6.0"
}
}
Meta information, dependencies, and other (source code)
xxxxxxxxxx
const {ApolloServer} = require("apollo-server");
const {ApolloGateway, RemoteGraphQLDataSource} = require("@apollo/gateway");
class AuthenticatedDataSource extends RemoteGraphQLDataSource {
willSendRequest({request, context}) {
request.http.headers.set('Authorization', context.authHeaderValue);
}
}
const gateway = new ApolloGateway({
serviceList: [
{name: "auth-service", url: "http://localhost:8081/graphql"},
{name: "planet-service", url: "http://localhost:8082/graphql"},
{name: "satellite-service", url: "http://localhost:8083/graphql"}
],
buildService({name, url}) {
return new AuthenticatedDataSource({url});
},
});
const server = new ApolloServer({
gateway, subscriptions: false, context: ({req}) => ({
authHeaderValue: req.headers.authorization
})
});
server.listen().then(({url}) => {
console.log(`�� Server ready at ${url}`);
});
Apollo Server definition (source code)
Maybe the source above can be simplified (especially in the part of passing authorization header); if so, feel free to contact me for change.
Authentication still works as was described earlier (you just need to specify Authorization header and its value). Also, it is possible to change security implementation, for example, move JWT validation logic from downstream services to the apollo-server module.
To launch this service you need to make sure you’ve launched 3 GraphQL Java services described previously, cd to the apollo-server directory, and run the following:
xxxxxxxxxx
npm install
npm run start-gateway
A successful launch should look like this:
xxxxxxxxxx
[nodemon] 2.0.2
[nodemon] to restart at any time, enter `rs`
[nodemon] watching dir(s): *.*
[nodemon] watching extensions: js,mjs,json
[nodemon] starting `node gateway.js`
� Server ready at http://localhost:4000/
[INFO] Sat Feb 15 2020 13:22:37 GMT+0300 (Moscow Standard Time) apollo-gateway: Gateway successfully loaded schema.
* Mode: unmanaged
Apollo Server startup log
Then you can use a unified interface to perform GraphQL requests to all of your services:
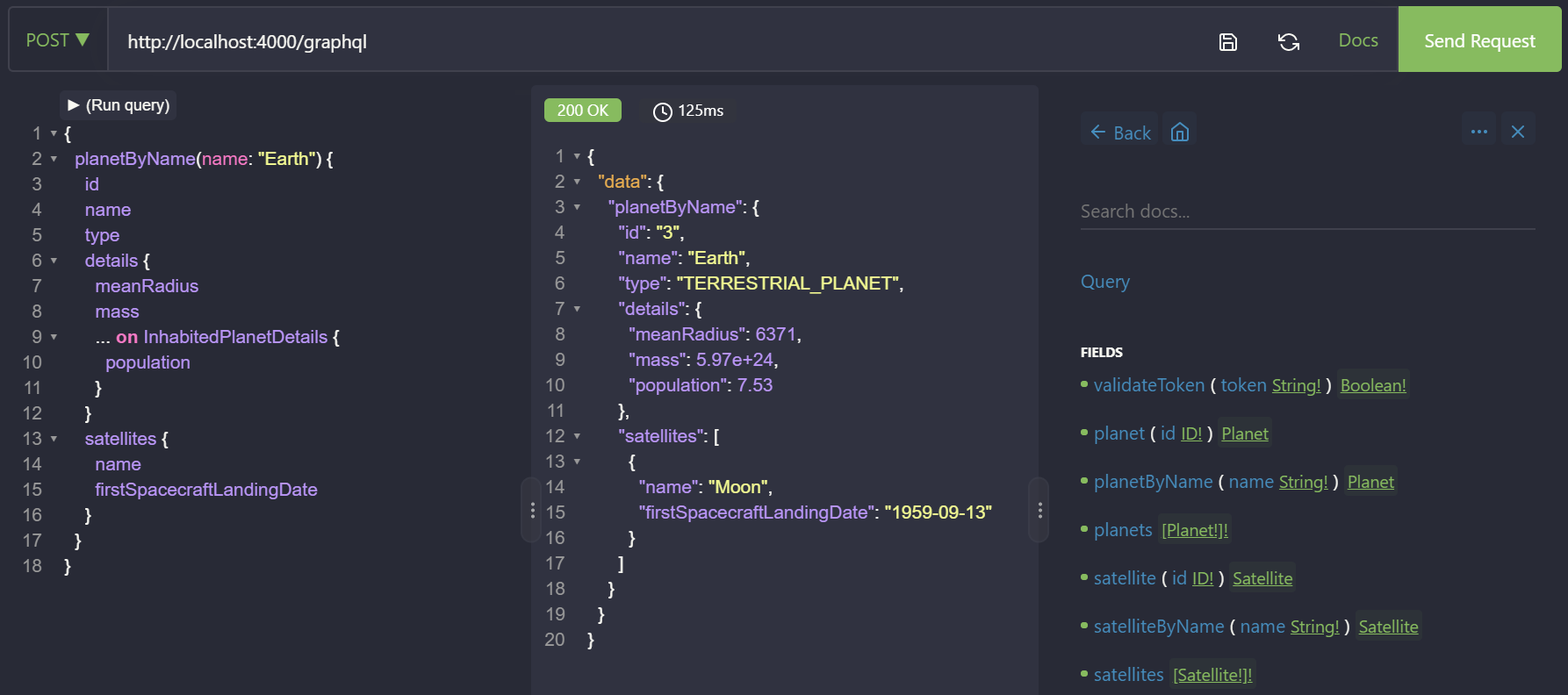
Also, you can navigate to http://localhost:4000/playground in your browser and use a built-in Playground IDE.
Note that now even if you have set limitations on queries using MaxQueryComplexityInstrumentation and/or MaxQueryDepthInstrumentation with reasonable parameters as was described above, GraphQL IDE does show the combined documentation. This is because Apollo Server is getting each service’s schema by performing simple { _service { sdl } } query instead of sizeable IntrospectionQuery.
Currently, there are some limitations of such an architecture which I encountered while implementing this project:
subscriptions are not supported by Apollo Gateway (but still works in a standalone GraphQL Java service)
That’s why in Planet service
.excludeSubscriptionsFromApolloSdl(true)was specified.a service trying to extend GraphQL interface requires knowledge of concrete implementations
An application written in any language or framework can be added as a downstream service of Apollo Server if it implements Federation specification; a list of libraries that offer such support is available on Apollo documentation.
Conclusion
In this article, I tried to summarize my experience with GraphQL on the JVM. Also, I showed how to combine APIs of GraphQL Java services to provide a unified GraphQL interface; in such an architecture an entity can be distributed among several microservices. It is achieved by using Apollo Server, Apollo Federation, and graphql-java-federation library. The source code of the considered project is on GitHub. Thanks for reading!
Further Reading
Published at DZone with permission of Roman Kudryashov. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments