How To Handle 100k Rows Decision Table in Drools (Part 2)
In this article, I created a prototype to demonstrate how to handle large rows in a decision table with reasonable performance.
Join the DZone community and get the full member experience.
Join For FreeAs described in my previous article, we are handling a performance issue when solving 100k row decision tables.
Solution 2: Precompile the SpreadSheet Rule

Following the vertical thinking of solution 1, I think we can improve the situation corresponding to the problems:
- Don’t dynamically load Excel data at runtime, let’s precompile it at build time.
- Use drools spreadsheet decision table so that it can be 'version-controlled' by KIE workbench;
When drools using rule template + Excel to fire rules, what it actually doing under the hood is:
- Using ExternalSpreadsheetCompiler to compile rule template and rule data( ie the Excel file) into drl (Drools rule language).
- Drools engine compiles drl into Java byte code.
- Java byte code formed rules is fired in JVM.
So can we do the first step before the runtime? even better can we do even the first 2 steps of transformation?
Fortunately, the answer is yes, drools already provided a friendly maven plugin (kie-maven-plugin) to precompile drl, or drools awareness rule format into Java byte. It is called Drools Executable Model.
One stone two birds, it makes what is good even better. In order to apply the drools executable model solution, we need to convert the raw Excel format into Drools awareness spreadsheet decision table. It can be managed by 'kie-workbench,' so problem 2 is resolved. What we need to do is simply add the Drools syntax 'header' into the decision table.
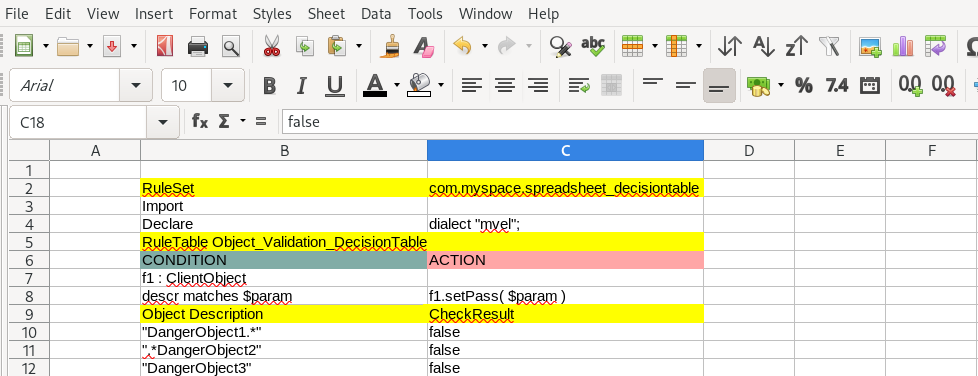
As you can see that:
B7: f1: ClientObject, it is the Fact declaration;
B8: descr matches $param, it is the condition logic
C8: f1.setPass($param), it is the action logic;
That’s it.
Let’s have a quick review of the change, then test the performance improvements.
Testing Improvements
Solution 2 is stored in the precompile-rule-solution branch.
1. In your rules pom.xml, drools-model-compiler is required.
xxxxxxxxxx
<! -- This is required for compile execution model-->
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-model-compiler</artifactId>
<version>7.39.0.Final</version>
</dependency>
2. Update kmodule.xml
Since we have converted the excel file into Drools awareness format excel file, we can get rid of the rule template. And update kmodule.xml as following:
xxxxxxxxxx
<kmodule xmlns="http://www.drools.org/xsd/kmodule">
<kbase name="template-db-KBase" default="true" packages="com.myspace.spreadsheet_decisiontable">
<ksession name="mykiesession" default="true" />
</kbase>
</kmodule>
3. Run mvn clean install
You can observe the kie-maven-plugin tasks build log which shows how we precompile the rules.
xxxxxxxxxx
[INFO] - - kie-maven-plugin:7.39.0.Final:generateModel (default-generateModel) spreadsheet-decisiontable - -
[INFO] Artifact not fetched from maven: org.drools:drools-model-compiler:7.39.0.Final. To enable the KieScanner you need kie-ci on the classpath
[INFO] Found 10206 generated files in Canonical Model
[INFO] Generating /wdc/github/ryanzhang/drools-bigtable/rules/target/generated-sources/drools-model-compiler/main/java/./com/myspace/spreadsheet_decisiontable/P36/LambdaPredicate36A1EF91A79A800E8DCE48467E3FB5EF.java
…
[INFO] DSL successfully generated
[INFO]
[INFO] - - kie-maven-plugin:7.39.0.Final:generateDMNModel (default-generateDMNModel) spreadsheet-decisiontable - -
[INFO]
[INFO] - - maven-compiler-plugin:3.8.1:compile (default-compile-1) spreadsheet-decisiontable - -
[INFO] Changes detected - recompiling the module!
[INFO] Compiling 10207 source files to /wdc/github/ryanzhang/drools-bigtable/rules/target/classes
[INFO]
[INFO] - - kie-maven-plugin:7.39.0.Final:build (default-build) spreadsheet-decisiontable - -
[INFO] Artifact not fetched from maven: org.drools:drools-model-compiler:7.39.0.Final. To enable the KieScanner you need kie-ci on the classpath
[INFO] kieMap not present
[INFO] KieModule successfully built!
[INFO]
[INFO] - - maven-jar-plugin:3.2.0:jar (default-jar) spreadsheet-decisiontable - -
[INFO] Building jar: /wdc/github/ryanzhang/drools-bigtable/rules/target/spreadsheet-decisiontable-1.0-SNAPSHOT.jar
[INFO]
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
[INFO] BUILD SUCCESS
[INFO] - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
[INFO] Total time: 01:35 min
What kie-maven-plugin does for us is:
- Use drools-model-compiler to convert spreadsheet decision table to generate 10206 Java code (Notice that it’s even better than drl file).
- Generated Java code was compiled into byte code and packaged into jars.
So when myapp client code loads the jar file, it would directly call the byte code without bothering to analyse the Excel file and do the drl parser, etc.
What’s important is that the business logic is still wrapped as its own project, not leaking into generic application code and lifecycle.
Performance
Let’s see the performance of solution 2:
10K rows table scenario:
xxxxxxxxxx
cd rules
mvn clean install -DskipTests
#You would notice that there 10000 java/class file was generated by kie-maven-plugin
# The rule package is spreadsheet-decisiontable-1.0-SNAPSHOT.jar
cd ../myapp
mvn clean package -DskipTests
Initialize Kie Session elapsed time: 1826
fired rules: 1 elapsed time: 167
Is Object Pass:false
100K rows table scenario:
xxxxxxxxxx
cd rules
mvn clean install -DskipTests
#It took me 16 mins in my laptop to compile, there are 100k java files generated
# The rule package is spreadsheet-decisiontable-1.0-SNAPSHOT.jar
cd ../myapp
mvn clean package -DskipTests
Initialize Kie Session elapsed time: 21885
fired rules: 1 elapsed time: 8603
Is Object Pass:false
Put the performance data into a table to compare:
| Solution(Row size) | Warm-up time | One rule Execution | Rule Compile(Package) |
|---|---|---|---|
| Rule Template + XLS (10k) | ~8 s | ~400ms | 14 s |
| Precompile spreadsheet decision table (10k) | ~1.7 s (4x faster) | ~150 ms (2x faster) | 1.5 mins (5x slower) |
| Rule Template + XLS (100k) | 99s | 9500ms | 1.5 mins |
| Precompile spreadsheet decision table (100k) | 21s (4x faster) | 8500ms (similar) | 15 mins (10x slower) |
Pros
Two obvious advantages we have gained by applying Drools executable models.
- Runtime performance is obviously improved.
- Spreadsheet decision table can be governed by 'kie-workbench.'
Sometimes this is not obvious to some users when they start to adopt rules oriented application framework. But it’s quite important from a rules governance perspective, such as version-controlled your rules data, deploy testing, and release your business rules. With the help of kie-workbench, all those features are already provided out of the box.
Cons
Solution 2 has two shortcomings, I think.
- Compilation time is quite long.
For a 10k rows number, the compilation time of 1.5 mins seems acceptable. It actually generated and then compiled 10k small Java files.
But for 100k rows numbers, it does not come out a reasonable compile time. It takes ~15 mins to complete. It would become very awkward no matter for dev experiences or CICD experiences. It just took too much effort when the rules became a certain level of amounts.
2. When the rows number is too big, like 100k rows, the performance improvement is very small.
Comparing the big effort to precompile it, the performance gain is not so big as we can see from the comparison data in the table.
Summary
For a certain number of decision tables, it seems that precompiling the rules can improve the runtime performance dramatically. And it’s worth a try, I think.
However, when decision tables come to 100k, it seems that it still doesn't produce very good results.
However, in reality, it’s quite common that keywords or condition values become very large. So we still need some better solutions to tackle 100k row decision tables.
In my next article, I will show a different approach to transform the dimension of fact and rule to improve performance.
Opinions expressed by DZone contributors are their own.
Comments