How To Implement RAG: A Simple Walkthrough
Learn how to enhance your LLMs with retrieval-augmented generation, using LlamaIndex and LangChain for data context, deploying your application to Heroku.
Join the DZone community and get the full member experience.
Join For FreeHaving the correct data to support your use case is essential to the successful implementation of LLMs in any business. While most out-of-the-box LLMs are great at general tasks, they can struggle with specific business problems. They didn’t train on the data for your business problem, so they don’t have adequate context to solve it.
Businesses often have a treasure trove of internal data and documents that could meet this need for specific context. But, here’s the question: How do we integrate all this useful data (context) into the LLM without doing resource-intensive and time-consuming retraining or fine-tuning the LLM?
The answer is retrieval-augmented generation (RAG), a technique that enhances LLMs with just-in-time retrieval of close context information.
In this post, we’ll walk through how to use LlamaIndex and LangChain to implement the storage and retrieval of this contextual data for an LLM. We’ll solve a context-specific problem with RAG by using LlamaIndex, and then we’ll deploy our solution easily to Heroku.
Before we start coding, let’s quickly cover the core concepts.
A Brief Introduction to RAG and LlamaIndex
When you ask your LLM a question that requires context to answer, RAG retrieves that contextual data to help the LLM give a more accurate and specific response. It’s like having a sous chef quickly run out to the farmer’s market to get the freshest ingredients that weren’t in the pantry so that the executive chef can cook up the perfect dish with all the necessary ingredients.
One key to how the RAG workflow can provide context is using vector databases and vector search indexes. Let’s break down some of the core concepts and what this all entails.
- A vector is a set of coded numbers that represent the meaning and context of a piece of text (such as a word, phrase, sentence, or even an entire document).
- An embedding is the actual numerical values in a vector, but most people tend to use the terms “vector” and “embedding” interchangeably.
- An embedding model has been trained on documents so that it can convert newly input text into vectors. Not all texts talk about the same things or in the same way — consider a set of academic research papers versus a set of marketing materials. So, we have different embedding models — each trained on specific datasets with specific goals in mind.
- Using an embedding model, we can create embeddings from documents, breaking the text in those documents down to their coded numbers. Creating an embedding might involve a strategy like document chunking, which splits large documents into smaller, manageable pieces. From there, each chunk is converted into an embedding.
- When you query a vector database, your question is turned into an embedding and compared against all of the other embeddings stored in a vector database.
- When you build a vector search index, you can perform very fast and accurate vector searches (also called similarity searches). Using vector databases lets you perform fast and accurate searches — not merely to match the presence of a specific string like in traditional databases, but to match for documents that are similar in meaning to the words you used.
Within the context of RAG, we use our original prompt to perform a vector search against all of the documents in a vector database. Then, those matching documents are sent as context to the LLM application. The LLM now has a set of detailed notes to refer to when crafting its answer to the original prompt.
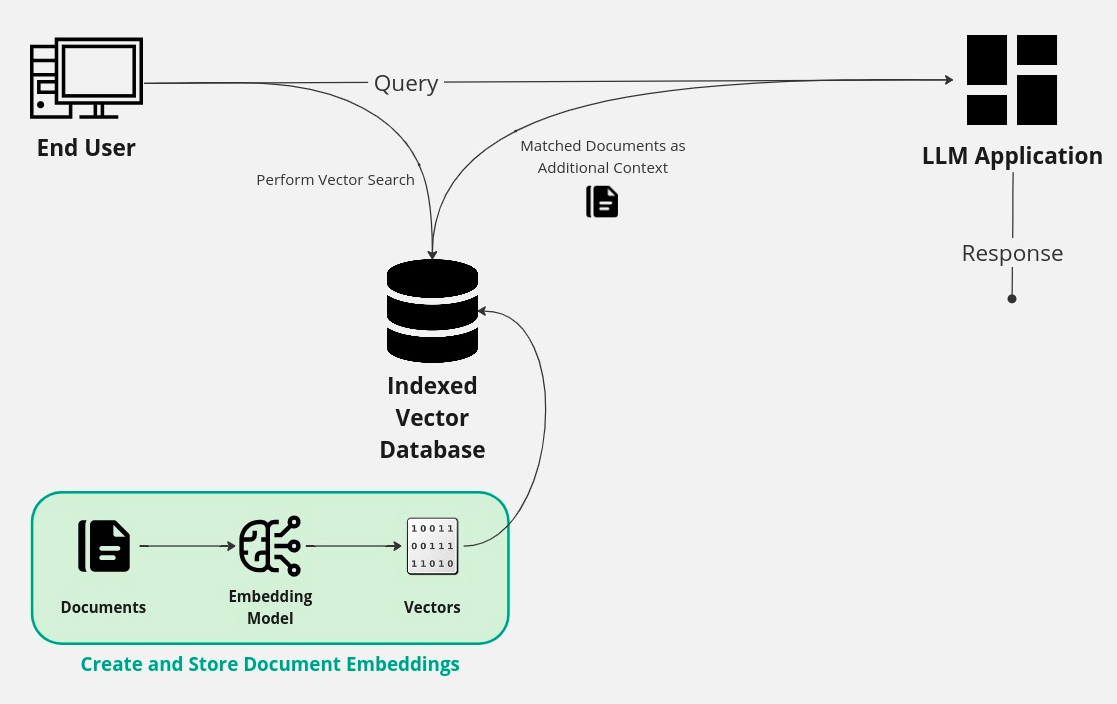
LlamaIndex is a crucial framework that simplifies the process of integrating, organizing, and retrieving private or specialized data. It will help us with creating the document embeddings and vector search index. Then, we’ll lean on LangChain to piece it all together, executing the similarity search and sending the results to our LLM to fetch a response. Together, LlamaIndex and LangChain provide a secure and dependable solution for handling the RAG workflow.
Are you ready to build something? Here we go!
An Introduction to Our Demo Project
The best way to learn about RAG with LlamaIndex and Heroku is to build a small sample application. For our purposes, let's pretend we work with Project Gutenberg, a library of over 70,000 free ebooks. We want to build an LLM-based chatbot that can answer specific questions about the free books in the project.
This is the perfect use case for using RAG, and we can use LlamaIndex to take advantage of the large corpus of book texts available to us. To keep our project simple, we’ll use The Confessions of St. Augustine, a popular book from AD 401.
The codebase for our completed project can be found in this GitHub repository. If you prefer, you can clone the repo and deploy the application to Heroku. Or, you can follow along step by step to see how we got the code that we did.
We’ll follow these general steps:
- Set up our project.
- Load the data.
- Build the index.
- Store the index.
- Integrate LangChain.
- Deploy to Heroku.
Step 1: Set Up Our Project
Create a new folder for your Python project. Then, activate a venv and install the initial dependencies that we will need.
(venv) ~/project$ pip install llama-index langchain langchain-openaiNext, we’ll load the data to be indexed.
Step 2: Load the Data
When building an index of internal data for use with RAG, you must gather all your data (text) into a single place. In our example case, that’s the text of the book we mentioned above. This is the context that we will soon convert to a vector index of embeddings using LlamaIndex.
In the typical use case, your context data will be a large corpus of text that fits the business problem you’re trying to solve.
For our mini demo, we’ll create a subfolder called data, and then we’ll download the book as a single file in that folder.
(venv) ~/project$ mkdir data
(venv) ~/project$ curl \
https://www.gutenberg.org/cache/epub/3296/pg3296.txt \
-o data/confessions.txt
(venv) ~/project$ ls data
confessions.txtStep 3: Build the Index
After gathering all your data in a single directory, it’s time to build the index. We’ll write a simple Python application that will use LlamaIndex to index the data, and then we’ll query our index.
For this to work, you will need an OpenAI account and API key. This is because LlamaIndex uses OpenAI’s text-embedding-3-small as the default embedding model. (Changing those defaults is outside the scope of this article.)
In our project root folder, we create a file called index.py. The initial contents look like this:
# index.py
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
import os
if os.environ.get('OPENAI_API_KEY') is None:
exit('You must provide an OPENAI_API_KEY env var.')
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("In which city is Saint Augustine the Bishop?")
print(response)We run our file and receive the expected response:
(venv) ~/project$ OPENAI_API_KEY=sk-******** python index.py
HippoOf course, we can double-check our data. Looking at the first few lines of the book, we see:
THE CONFESSIONS OF SAINT AUGUSTINE
By Saint Augustine
Bishop of HippoAs you can see, LlamaIndex did its job. Our Python application completed our question exactly as we would expect from the vector-indexed data.
Step 4: Store the Index
It’s important to note that, in the above example, we only store our indexed data in memory and not on a disk. Our index—now a series of vector embeddings in memory—will be lost completely after we make our call to the OpenAI model and finish the workflow.
Creating a vector index (embeddings) for our text isn’t free, so we don’t want to have to recompute those results every time we call the model. It’s best to have a separate workflow where we persist the index to disk. Then, we can reference it at any time later.
A common approach to doing this is to store embeddings in a PostgreSQL database and use pgvector to perform a similarity search. To keep our demonstration simple, we’ll just store our indexed data as flat files.
So, we add this simple step to our index.py file:
PERSIST_DIR='./my_vector_indexes/gutenberg/'
index.storage_context.persist(persist_dir=PERSIST_DIR)Now, after we run our file, we can check for our stored index.
(venv) ~/project$ OPENAI_API_KEY=sk-******** python index.py
Hippo
(venv) ~/project$ tree
.
├── data
│ └── confessions.txt
├── index.py
└── my_vector_indexes
└── gutenberg
├── default__vector_store.json
├── docstore.json
├── graph_store.json
├── image__vector_store.json
└── index_store.json
3 directories, 7 filesStep 5: Integrate LangChain
We’ve learned the basics of what a vector index store is and how easy it is to build one. But, to actually build an end-to-end application that chains it all together, we use LangChain. This way, we can deploy our solution as an API. Let’s rewrite our index.py code to be a bit more production-worthy.
We’ll show the code below and then explain what we’re doing after. It might look like a lot of code, but we are only adding a few new steps.
# index.py
import os
from langchain_openai import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferWindowMemory
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from langchain_community.retrievers import LlamaIndexRetriever
from fastapi import FastAPI
from pydantic import BaseModel
if os.environ.get('OPENAI_API_KEY') is None:
exit('You must provide an OPENAI_API_KEY env var.')
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# For this demo, we will not persist the index.
retriever = LlamaIndexRetriever(index=index.as_query_engine())
llm = ChatOpenAI(model_name="gpt-3.5-turbo", max_tokens=2048)
memory = ConversationBufferWindowMemory(
memory_key='chat_history',
return_messages=True,
k=3
)
conversation = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
max_tokens_limit=1536
)
class Prompt(BaseModel):
question: str
app = FastAPI()
@app.post("/prompt")
async def query_chatbot(prompt: Prompt):
response = conversation.invoke({'question': prompt.question})
return response['answer']
if __name__=='__main__':
import uvicorn
uvicorn.run(app, host="localhost", port=8000)First, notice that we are now directly using LangChain and OpenAI. We set up our llm along with some memory so that our conversation can be “remembered” across subsequent queries. Now, we have an actual ChatBot which we can interact with.
From there, we use FastAPI to create an API server that listens for POST requests on the /prompt endpoint. Requests to that endpoint are expected to have a request body with a question, which is then passed (along with context from our vector index) to the LLM.
We use uvicorn to spin up our server on port 8000.
Before we can start up our server, let’s add those new Python dependencies:
(venv) ~/project$ pip install fastapi pydantic uvicornNow, it’s time to test. We start by spinning up our server.
(venv) ~/project$ OPENAI_API_KEY=sk-******** python index.py
INFO: Started server process [1101807]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)In another terminal, we send a curl request to our endpoint.
$ curl -X POST \
--header "Content-type:application/json" \
--data '{"question":"Who is Ambrose?"}' \
http://localhost:8000/prompt
"Ambrose is a person mentioned in the text provided. He is described as a respected
and celibate man who was esteemed by the author. Ambrose is depicted as a figure of
great honor and excellence, particularly known for his dedication to reading and
studying."
Success! Our vector index appears to be up and running, and our chatbot is fully functional. It’s time to deploy.
Step 6: Deploy to Heroku
After completing the major legwork, we only need to take a few simple steps to deploy our application to Heroku.
Create the requirements.txt File With Python Dependencies
Heroku will need to know what Python dependencies to install when building our project. It looks for this list in a file called requirements.txt. We can easily generate one with this command:
(venv) ~/project$ pip freeze > requirements.txtCreate the Procfile
We also need to tell Heroku how to spin up our Python application. We do this in a file called Procfile.
(venv) ~/project$ echo \
'web: uvicorn index:app --host=0.0.0.0 --port=${PORT}' > ProcfileCreate the runtime.txt File
Lastly, runtime.txt will tell Heroku which Python runtime version we would like to use.
(venv) ~/project$ echo 'python-3.11.8' > runtime.txtThose are all the files we need. This is what our project folder structure should look like (we’ve removed the persisted vector index):
~/project$ tree
.
├── data
│ └── confessions.txt
├── index.py
├── Procfile
├── requirements.txt
└── runtime.txt
1 directory, 5 filesIf you’re working from scratch and didn’t clone the GitHub repo for this demo project, then commit these files to your own Git repository.
Create a Heroku App
After downloading and installing the Heroku CLI, run the following commands. You can choose any name for your app, and you’ll need to provide your unique OpenAI API key.
~/project$ heroku login
~/project$ heroku apps:create my-llamaindex-app
~/project$ heroku git:remote -a my-llamaindex-app
~/project$ heroku config:add OPENAI_API_KEY=replaceme -a my-llamaindex-app
~/project$ git push heroku main
…
remote: -----> Building on the Heroku-22 stack
remote: -----> Determining which buildpack to use for this app
remote: -----> Python app detected
remote: -----> Using Python version specified in runtime.txt
…
remote: -----> Launching...
remote: Released v4
remote: https://my-llamaindex-app-6b48faa3ee6a.herokuapp.com/ deployed to Heroku
With our application deployed, we test by sending a curl request to our API server:
$ curl -X POST \
--header "Content-type:application/json" \
--data '{"question":"Who is Ambrose?"}' \
https://my-llamaindex-app-6b48faa3ee6a.herokuapp.com/prompt
"Ambrose is a significant figure in the text provided. He is being described as a
respected and happy man, known for his celibacy and his dedication to reading and
studying. He is referred to as a holy oracle and a person of great influence and
wisdom."
Keep in mind that the curl call above uses the unique Heroku app URL for our deployment. Yours will be different from what is shown here.
We are up and running on Heroku!
Conclusion
We’ve clearly seen the power of LlamaIndex and the important role it plays when building RAG apps to interact with LLMs. When we can easily add specific data sources as context for an LLM without expensive model retraining—that’s a huge win. It’s a win for companies and developers looking to take their LLM workflows a step further.
Combining LlamaIndex with other LangChain toolsets is also seamless and straightforward. Building a chatbot requires only a few lines of additional code. And finally, being able to quickly and easily deploy our solution to Heroku makes our application immediately accessible without any fuss. Simple deployments like this free up developers to focus on the more complicated and important task of building their LLM-based solutions.
Happy coding!
Published at DZone with permission of Alvin Lee. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments