How To Improve a GenAI's Model Output
Generative AI has evolved into powerful content generators thanks to DL algorithms. However, to get more accurate results, different cycles and iterations can be used.
Join the DZone community and get the full member experience.
Join For FreeGenerative AI, dating back to the 1950s, evolved from early rule-based systems to models using deep learning algorithms. In the last decade, advancements in hardware and software enabled real-time, high-quality content generation by large-scale generative AI models.
In this article, I’ll tell how you can successfully integrate Generative AI into large-scale production processes within the business environment. So, you will know how to prepare for implementing Generative AI at an enterprise level. For example, for customer service, marketing communications, finance management, or other GenAI business applications.
ML Role in GenAI
In the context of Generative AI, ML algorithms structure a series of tasks. These task sequences are continuous experiments, requiring us to prepare our teams and businesses for recurring cycles.
For example, you’re instructing a language model to provide responses. In this case, you have to establish a cycle, evaluate results, and iterate as needed. Here, you’ll use different problem-solving approaches or “patterns” that progress from simpler to more advanced strategies for managing tasks.
This diagram includes different cycles and iterations. You can refer to it and adapt it to your enterprise's specific requirements.
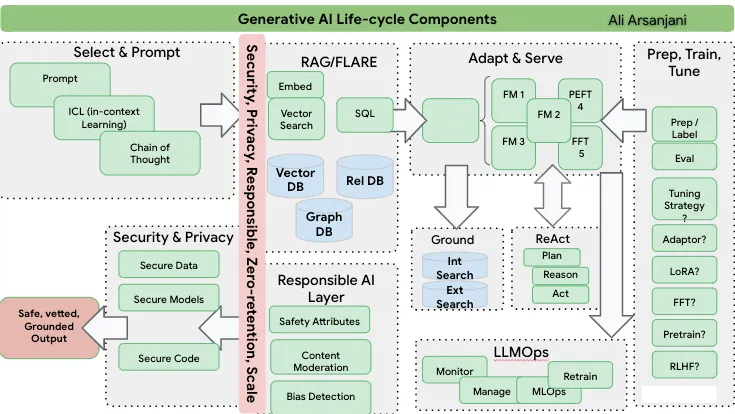
Let’s break down a simple cycle.
Level 1: Prompt, In-Context Learning and Chaining
Step 1
You pick a model, give it a prompt, get a response, evaluate the response, and re-prompt if needed until you get the desired outcome.
In-context learning is a prompt engineering approach where language models learn tasks from a few natural language examples and try to perform them. ICL is a new approach in NLP with similar objectives to few-shot learning that lets models understand context without extensive tuning.
Step 2
Apart from Prompt → FM → Adapt → Completion pattern, we often need a Chain of Tasks that involves data extraction, predictive AI, and generative AI foundational models. This pattern follows:
Chain: Extract data/analytics → Run predictive ML model → Send result to LLM → Generate output
For example, in a marketing scenario, you can start by using SQL with BigQuery to target specific customer segments. Next, a Predictive AI ranking algorithm is used to identify the best customers and send this data to the LLM to generate personalized emails.
Level 2. Improving the Previous Level
If you're still unsatisfied with the model's responses, you can try fine-tuning the foundational model. It can be domain-specific, industry-specific, or created for specific output formats. It fine-tunes all parameters on a large dataset of labeled examples, which can be computationally intensive but offers top performance.
Parameter-efficient fine-tuning (PEFT) can be a more computationally efficient approach compared to traditional fine-tuning. PEFT fine-tunes only a subset of the model's parameters, either through adaptor tuning or Low-Rank Adaptation of Large Language Models.
- Adaptor tuning adds a task-specific layer trained on a small set of labeled examples, letting the model learn task-specific features without full parameter fine-tuning.
- LoRA approximates the model's parameters with a low-rank matrix using matrix factorization, efficiently fine-tuning it on a small dataset of labeled examples to learn task-specific features.
Level 3. Upgrading the Input's Context
Step 1
To implement the semantic search for related documents, you should divide them into sentences or paragraphs. You can then transform them into embeddings using a Vector Embedding tool. This process utilizes an Approximate Nearest Neighbor (ANN) search, improving the model's responses by reducing the chances of hallucination and providing relevant context.
It's known as Retrieval Augmented Generation (RAG).
- Start with a user query or statement.
- Make the prompt better by adding context from the Vector Embedding tool.
- Send the augmented prompt to the LLM.
Step 2
You can boost the model's accuracy by letting it show where it got its answers. With RAG, this happens before showing the answer. After generating the answer, it finds a source and shares it. Many providers, like Google Cloud AI, offer ways to do this.
Step 3
FLARE, a spin-off of RAG, involves proactive retrieval. It predicts what's coming next and fetches information in advance, especially when it's unsure about the answers.
Last Thoughts
Mastering the stages of a generative AI project and adapting the needed skills empowers businesses to use AI effectively. It's a challenging journey that requires planning, resources, and ethical commitment, but the result is a powerful AI tool that can transform business operations. I hope you found this information helpful!
Published at DZone with permission of Igor Paniuk. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments