How to Optimize Elasticsearch for Better Search Performance
A how-to for optimizing Elaticsearch to improve search performance.
Join the DZone community and get the full member experience.
Join For FreeIn today's world, data is generated in high volumes and to make something out of it, extracted data is needed to be transformed, stored, maintained, governed and analyzed. These processes are only possible with a distributed architecture and parallel processing mechanisms that Big Data tools are based on. One of the top trending open-source data storage that responds to most of the use cases is Elasticsearch.
Elasticsearch is a distributed data storage and search engine with fault-tolerance and high availability capabilities. To make the best use of its search feature, Elasticsearch needs to be configured properly. Because one simple configuration will not be suitable for every use case, you will need to extract your requirements first and then configure your cluster based on your use case. This article will focus on the search intensive initial and dynamic configurations of the Elasticsearch.
Index Configuration
By default, an Elasticsearch index has 5 primary shards and 1 replica for each. Such configuration is not suitable for every use case. Shard configuration needs to be computed properly to maintain a stable and efficient index.
Physical Boundaries
Shard size is quite critical for search queries. If there would be too many shards that are assigned to an index, Lucene segments would be small which causes an increase in overhead. Lots of small shards would also reduce query throughput when multiple queries are made simultaneously. On the other hand, too large shards cause a decrease in search performance and longer recovery time from failure. Therefore, it is suggested by Elasticsearch that one shard’s size should be around 20 to 40 GB.
For instance, if you calculated that your index would store 300 GBs of data, you would assign 9 to 15 primary shards to that index. Depending on the cluster size, let’s say you have 10 nodes in your cluster, you would choose to have 10 primary shards for this index to distribute shards evenly between the nodes of your cluster.
Continuous Flow
If there is a data stream that continuously ingested to the Elasticsearch cluster, time-based indices should be used to maintain indices more easily. If the throughput of the stream changes over time, just changing the next index’s configuration appropriately simplifies the adaptation and allows it to scale quite easily.
So, how to query for all of the documents residing in separate time-based indices? The answer is aliased. Multiple indices could be put into an alias and searching on that alias makes queries as if they were made on a single index. Of course, a balance needs to be kept on how many indices should be put into an alias since too many small indices on an alias affect performance negatively. For example, a decision might need to be made between keeping monthly or weekly indices. If the cluster allows monthly indices in terms of size with the best configuration, there is no need to keep weekly indices as it will affect the performance negatively since there would be too many indices and the results coming from each of them need to be sorted out.
Index Sorting
One use case is that just focusing only on recent events. Elasticsearch has the mechanism of lazy evolution for such a use case. Top documents of each segment are already sorted in the index and if the total number of documents is not interested, Elasticsearch will only compare top documents per segment by setting track_total_hits to false. This will help speeding up the conjunctions efficiently which works with low-cardinality fields if the index sorting machine is used.
Shard Optimization
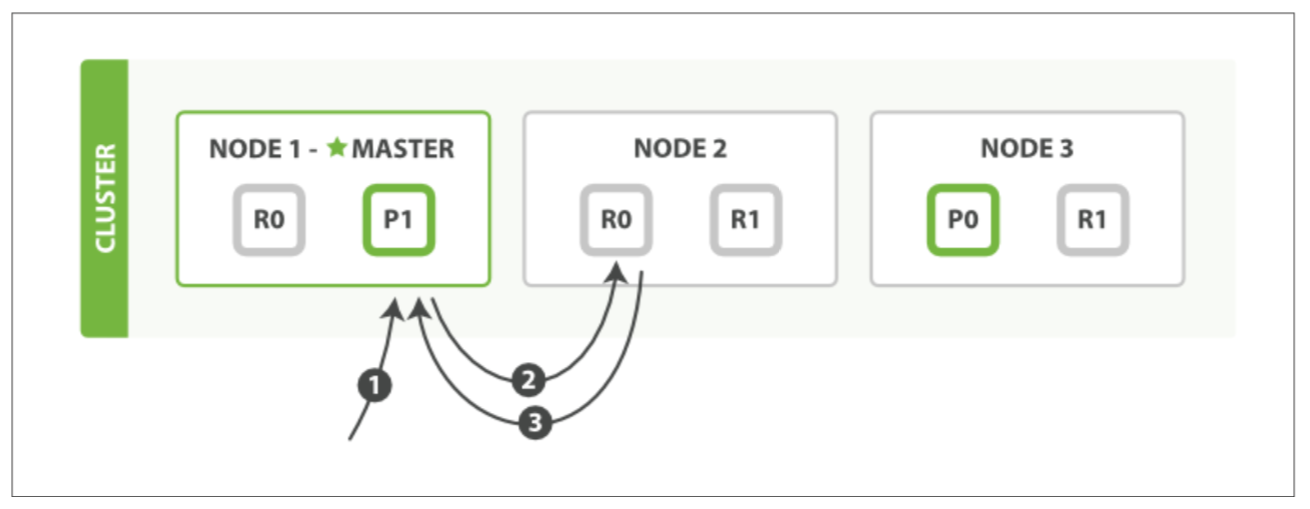
Sharding allows to make operations in parallel with the distributed architecture and so, it allows horizontal scaling. There are two types of shards. One of them being the primary shard responsible for reading and writing operations like index, reindex, delete, etc… The other one is replica shards responsible for high availability and read throughput.
Size of the shards, size of each segment in a shard, how many active ones in a node are the major considerations while optimizing shards.
Replica shards are important to scale out the search throughput and the number of replica shards can be increased carefully if the hardware is suitable for such cases. A good launch point for capacity planning is to allocate shards with a factor of 1.5 to 3 times the number of nodes. Usually, the setup that has fewer shards per node will perform better since the filesystem cache will be more efficiently distributed across nodes.
Also, the formula for which allocation of the number of replica shards:
The expected maximum number of nodes to fail needs to be computed first since no one would want data loss in their database. Then, according to the number of primary shards for index and the number of nodes, the efficient distribution of replica shards across the cluster for high throughput is extracted. The maximum of each gives the true value for the number of replica shards.
Elasticsearch Configuration
One of the most primary considerations when configuring the Elasticsearch cluster is that making sure that at least half the available memory goes to the filesystem cache so that Elasticsearch can keep hot regions of the index in physical memory.
Physical available heap space should also be considered while designing the cluster. Elasticsearch recommends shard allocation based on available heap space should be 20 shards/GB at maximum as a good rule-of-thumb. For instance, a node with a 30 GBs of the heap should have 600 shards maximum to keep the cluster in good health. storage on one node could be formulated as below:
Disk space a node can support = 20 * (Heap Size per GB) * (Size of Shard in GB)
Since it is common to see shards between 20 and 40 GBs in size in an efficient cluster, maximum storage a node with 16 GBs of available heap space can support is up to 12 TBs of disk space. Awareness of boundaries helps to prepare for better design and future scaling operations. But of course, to make the cluster efficient, one shard per index, per node rule also applies to every ideal scenario.
There are many configuration settings could be made on run-time as well as at the initial phase. Being aware of what can be changed during run-time and what can not be is crucial when constructing the Elasticsearch index and the cluster itself for better search performance.
Dynamic Settings
- Using time-based indices for managing data and also for better organization. If there is no write operation on past indices, one can set passed monthly indices to the read-only mode to improve search performance made on those indices.
- When an index is set to be read-only, force merge operation could be made to reduce the number of segments by merging them. Hence, optimized segments will result in better search performance since overhead per shard depends on the segment count and size. Do not apply this to read-write indices since it will cause very large segments to be produced (>5Gb per segment). Also, this operation should be done during off-peak times since it is an expensive operation.
- The cache can be utilized for use-cases of the end-user. The preference setting can be used to optimize the usage of the caches since it will allow analyzing a narrower subset of the index.
- Swapping can be disabled on each node for stability and should be avoided at all costs. It can cause garbage collections to last for minutes instead of milliseconds and can cause nodes to respond slowly or even to disconnect from the cluster. In a resilient distributed system, it’s more effective to let the operating system kill the node. It can be disabled by setting bootstrap.memory_lock to True.
- On active indices refresh interval could be increased. Active indices mean that data indexing on these indices is still being made. The default refresh interval is 1 second. This forces Elasticsearch to create a segment in every second. Increasing this value depending on your use case, (to say, the 30s) will allow larger segments to flush and decreases future merge pressure. Therefore, the fact that it decreases merge pressure on active indices searches queries more stable.
- index.merge.scheduler.max_thread_count is set to Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2)) by default. But this works well with SSD configuration. In the case of HDD, it should be set to 1.
- Sometimes, Elasticsearch will rebalance the shards across the cluster. This operation might lead to a decrease in the performance of the search queries. In the production mode, when needed, rebalancing can be set to none through cluster.routing.rebalance.enable setting.
- The searches based on the dates should not include now parameter since now is not a cacheable parameter. Instead, specifically, define the timestamp of now in your queries that include dates for it to be cacheable.
Initial Settings
- Make use of the copy-to feature of the Elasticsearch for some fields that are been queried more often. For example, brand name, engine version, model name and color fields of the car could be merged with the copy-to directive. It will improve the search query performance made in those fields.
- Of course, having a homogeneous cluster is always desirable. But, in case of a heterogeneous cluster, it would be good to assign weight on shard allocation for the node that has better hardware. In order to assign weight,
cluster.routing.allocation.balance.shardvalue needs to be set while the default value is 0.45f. - The query itself has also a major impact on the latency of the response. In order not to break the circuit while querying and cause Elasticsearch cluster to be in an unstable condition,
indices.breaker.total.limitcould be set appropriately to your JVM heap size concerning your queries' complexity. The default of this setting is 70% of JVM heap. - Elasticsearch, by default, assumes the primary use case is searching. In case of a need to increase the concurrency, thread pool threadpool for search setting could be increased and threadpool for indexing could be decreased concerning the number of cores in the CPU on a node.
- Adaptive replica selection should be turned on. The request will be redirected to the most responsive nodes instead of the round-robin approach based on these:
- Response time of past requests between the coordinating node and the node containing the copy of the data.
- Time past search requests took to execute on the node containing the data.
- The queue size of the search threadpool on the node containing the data.
There are lots of configuration settings for the Elasticsearch cluster to improve the latency of queries. If you are looking to design an Elasticsearch cluster that contains a heavy search use case, it would be my pleasure to help you through every single aspect of the design with this blog.
Thanks for reading! Don't forget to leave a comment!
Opinions expressed by DZone contributors are their own.
Comments